 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
Using Large Language Models for Knowledge Engineering (LLMKE): A Case Study on Wikidata
Sep 15, 2023In this work, we explore the use of Large Language Models (LLMs) for knowledge engineering tasks in the context of the ISWC 2023 LM-KBC Challenge. For this task, given subject and relation pairs sourced from Wikidata, we utilize pre-trained LLMs to produce the relevant objects in string format and link them to their respective Wikidata QIDs. We developed a pipeline using LLMs for Knowledge Engineering (LLMKE), combining knowledge probing and Wikidata entity mapping. The method achieved a macro-averaged F1-score of 0.701 across the properties, with the scores varying from 1.00 to 0.328. These results demonstrate that the knowledge of LLMs varies significantly depending on the domain and that further experimentation is required to determine the circumstances under which LLMs can be used for automatic Knowledge Base (e.g., Wikidata) completion and correction. The investigation of the results also suggests the promising contribution of LLMs in collaborative knowledge engineering. LLMKE won Track 2 of the challenge. The implementation is available at https://github.com/bohuizhang/LLMKE.
Discovering Fine-Grained Semantics in Knowledge Graph Relations
Feb 17, 2022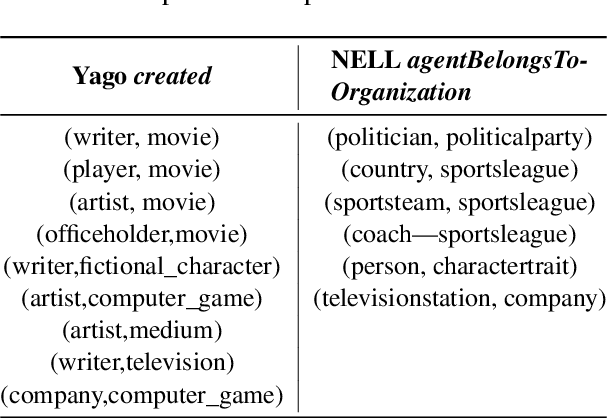
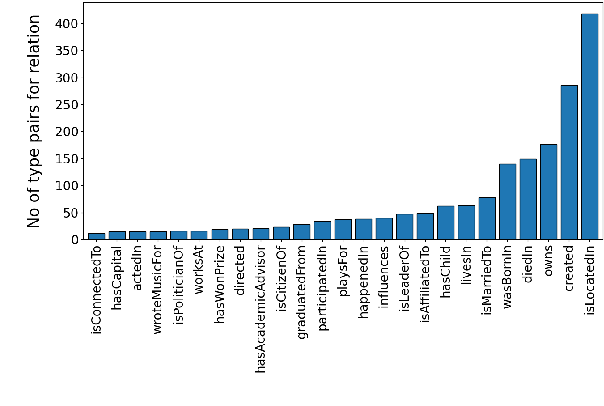
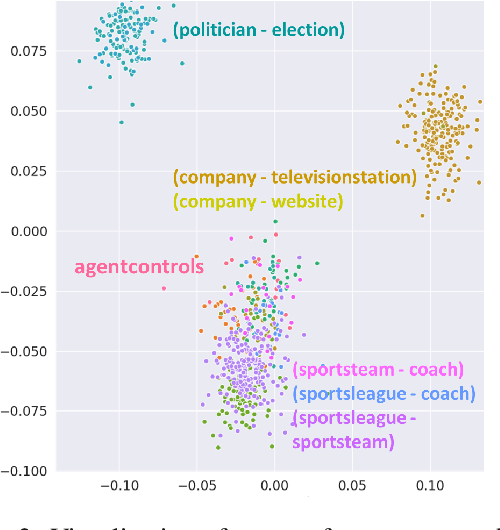
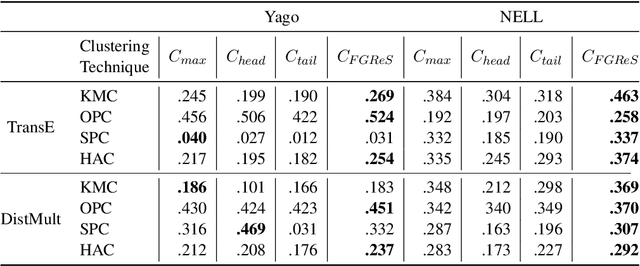
When it comes to comprehending and analyzing multi-relational data, the semantics of relations are crucial. Polysemous relations between different types of entities, that represent multiple semantics, are common in real-world relational datasets represented by knowledge graphs. For numerous use cases, such as entity type classification, question answering and knowledge graph completion, the correct semantic interpretation of these relations is necessary. In this work, we provide a strategy for discovering the different semantics associated with abstract relations and deriving many sub-relations with fine-grained meaning. To do this, we leverage the types of the entities associated with the relations and cluster the vector representations of entities and relations. The suggested method is able to automatically discover the best number of sub-relations for a polysemous relation and determine their semantic interpretation, according to our empirical evaluation.