 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Generation for Large Knowledge Graphs Using Large Language Models
Jun 04, 2025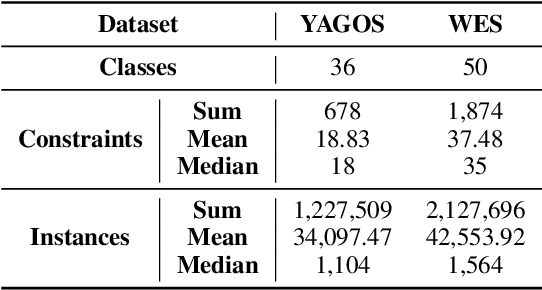
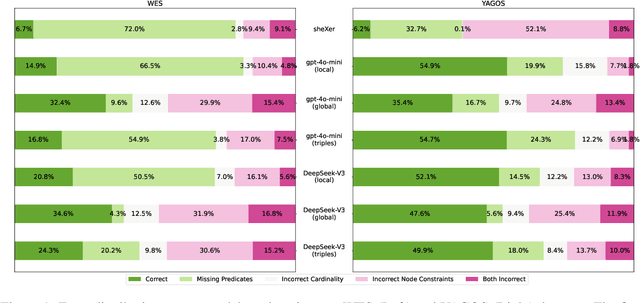
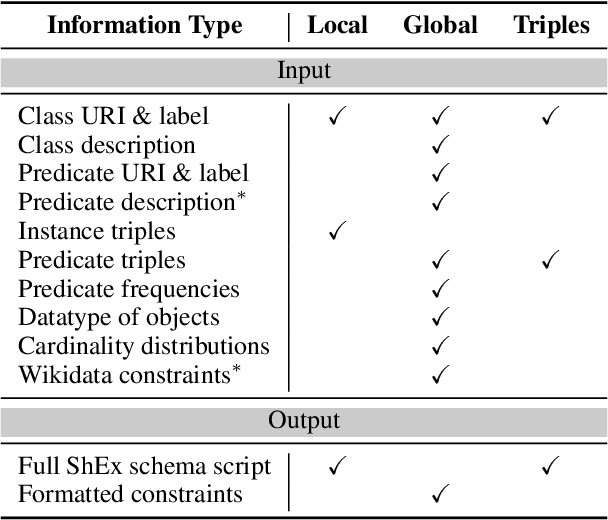

Schemas are vital for ensuring data quality in the Semantic Web and natural language processing. Traditionally, their creation demands substantial involvement from knowledge engineers and domain experts. Leveraging the impressive capabilities of large language models (LLMs) in related tasks like ontology engineering, we explore automatic schema generation using LLMs. To bridge the resource gap, we introduce two datasets: YAGO Schema and Wikidata EntitySchema, along with evaluation metrics. The LLM-based pipelines effectively utilize local and global information from knowledge graphs (KGs) to generate validating schemas in Shape Expressions (ShEx). Experiments demonstrate LLMs' strong potential in producing high-quality ShEx schemas, paving the way for scalable, automated schema generation for large KGs. Furthermore, our benchmark introduces a new challenge for structured generation, pushing the limits of LLMs on syntactically rich formalisms.
Using Large Language Models for Knowledge Engineering (LLMKE): A Case Study on Wikidata
Sep 15, 2023In this work, we explore the use of Large Language Models (LLMs) for knowledge engineering tasks in the context of the ISWC 2023 LM-KBC Challenge. For this task, given subject and relation pairs sourced from Wikidata, we utilize pre-trained LLMs to produce the relevant objects in string format and link them to their respective Wikidata QIDs. We developed a pipeline using LLMs for Knowledge Engineering (LLMKE), combining knowledge probing and Wikidata entity mapping. The method achieved a macro-averaged F1-score of 0.701 across the properties, with the scores varying from 1.00 to 0.328. These results demonstrate that the knowledge of LLMs varies significantly depending on the domain and that further experimentation is required to determine the circumstances under which LLMs can be used for automatic Knowledge Base (e.g., Wikidata) completion and correction. The investigation of the results also suggests the promising contribution of LLMs in collaborative knowledge engineering. LLMKE won Track 2 of the challenge. The implementation is available at https://github.com/bohuizhang/LLMKE.