 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Eval Ever: A Unifying Schema and Community Repository for AI Evaluation Results
Jun 12, 2026AI evaluations are widely used for testing and understanding progress. However, the diverse evaluators bring with them inconsistencies that challenge analysis and comparison. First, results are saved in incompatible formats, scattered across leaderboards, papers, blog posts, evaluation harness logs, and custom repositories. Second, results are created by different evaluation frameworks, which produce divergent scores for nominally identical evaluations and record metadata inconsistently, hindering comparison, cross-community evaluation science, cost reduction, and reuse. We introduce Every Eval Ever, the first shared schema and community-crowdsourced repository for AI evaluation results. The schema standardizes how evaluations are represented in a unified, single JSON document. It is source-agnostic by design, ingesting results from evaluation harnesses and papers alike, and optionally stores per-instance outputs for fine-grained analysis. We contribute: (i) a community-governed metadata schema with a companion instance-level schema, the first standardization effort of its kind; (ii) automatic converters from popular formats, evaluation harnesses, and leaderboards to the unified schema; and (iii) a crowdsourced community database hosted on Hugging Face, currently spanning to date 22,235 models, 2,273 unique benchmarks, and 31 evaluation formats.
Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Benchmarking and Enhancing Text-to-Image Models for Generating Visual Representations in Early Arithmetic Education
May 29, 2026AI systems are increasingly used to support educational content creation, yet it remains unclear whether they can generate outputs that faithfully represent the pedagogical concepts they are intended to teach. Thus, we introduce equation-to-visual generation, a task that, in contrast to conventional image generation, requires producing pedagogically meaningful visuals from arithmetic equations while precisely preserving their numerical and relational structure. Informed by interviews with teachers and an analysis of educational materials, we construct E2V-Bench, a benchmark spanning four pedagogically grounded visual types, along with automatic metrics for evaluating visual correctness. Our evaluation reveals that recent text-to-image (T2I) models frequently fail on this task, with errors dominated by incorrect object counts and broken relational structure. Building on this, we explore benchmark-guided enhancement strategies. These strategies improve representative models, while the remaining gap calls for stronger numerical and relational grounding in future T2I models.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
Nov 11, 2025Solving complex tasks usually requires LLMs to generate long multi-step reasoning chains. Previous work has shown that verifying the correctness of individual reasoning steps can further improve the performance and efficiency of LLMs on such tasks and enhance solution interpretability. However, existing verification approaches, such as Process Reward Models (PRMs), are either computationally expensive, limited to specific domains, or require large-scale human or model-generated annotations. Thus, we propose a lightweight alternative for step-level reasoning verification based on data-driven uncertainty scores. We train transformer-based uncertainty quantification heads (UHeads) that use the internal states of a frozen LLM to estimate the uncertainty of its reasoning steps during generation. The approach is fully automatic: target labels are generated either by another larger LLM (e.g., DeepSeek R1) or in a self-supervised manner by the original model itself. UHeads are both effective and lightweight, containing less than 10M parameters. Across multiple domains, including mathematics, planning, and general knowledge question answering, they match or even surpass the performance of PRMs that are up to 810x larger. Our findings suggest that the internal states of LLMs encode their uncertainty and can serve as reliable signals for reasoning verification, offering a promising direction toward scalable and generalizable introspective LLMs.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Chimera: Diagnosing Shortcut Learning in Visual-Language Understanding
Sep 26, 2025Diagrams convey symbolic information in a visual format rather than a linear stream of words, making them especially challenging for AI models to process. While recent evaluations suggest that vision-language models (VLMs) perform well on diagram-related benchmarks, their reliance on knowledge, reasoning, or modality shortcuts raises concerns about whether they genuinely understand and reason over diagrams. To address this gap, we introduce Chimera, a comprehensive test suite comprising 7,500 high-quality diagrams sourced from Wikipedia; each diagram is annotated with its symbolic content represented by semantic triples along with multi-level questions designed to assess four fundamental aspects of diagram comprehension: entity recognition, relation understanding, knowledge grounding, and visual reasoning. We use Chimera to measure the presence of three types of shortcuts in visual question answering: (1) the visual-memorization shortcut, where VLMs rely on memorized visual patterns; (2) the knowledge-recall shortcut, where models leverage memorized factual knowledge instead of interpreting the diagram; and (3) the Clever-Hans shortcut, where models exploit superficial language patterns or priors without true comprehension. We evaluate 15 open-source VLMs from 7 model families on Chimera and find that their seemingly strong performance largely stems from shortcut behaviors: visual-memorization shortcuts have slight impact, knowledge-recall shortcuts play a moderate role, and Clever-Hans shortcuts contribute significantly. These findings expose critical limitations in current VLMs and underscore the need for more robust evaluation protocols that benchmark genuine comprehension of complex visual inputs (e.g., diagrams) rather than question-answering shortcuts.
LEXam: Benchmarking Legal Reasoning on 340 Law Exams
May 19, 2025
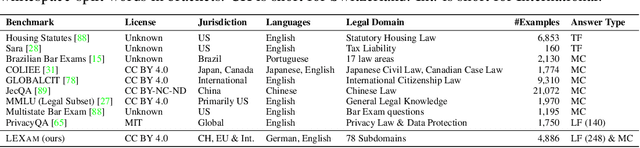
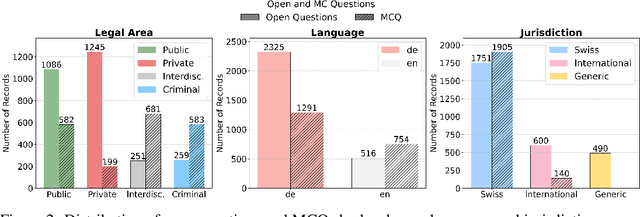
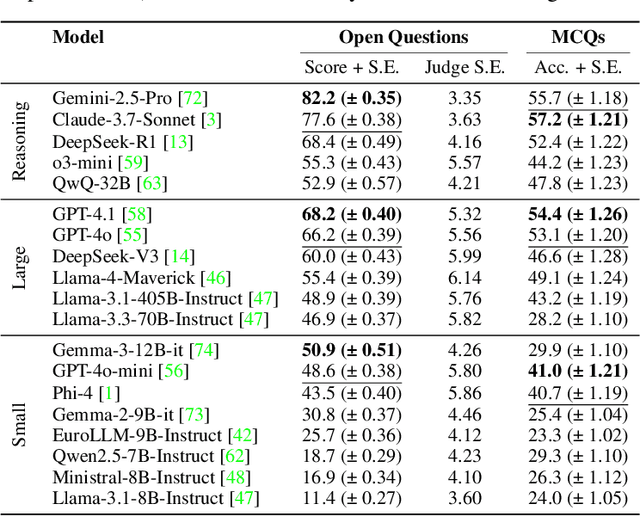
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
Ev2R: Evaluating Evidence Retrieval in Automated Fact-Checking
Nov 08, 2024



Current automated fact-checking (AFC) approaches commonly evaluate evidence either implicitly via the predicted verdicts or by comparing retrieved evidence with a predefined closed knowledge source, such as Wikipedia. However, these methods suffer from limitations, resulting from their reliance on evaluation metrics developed for different purposes and constraints imposed by closed knowledge sources. Recent advances in natural language generation (NLG) evaluation offer new possibilities for evidence assessment. In this work, we introduce Ev2R, an evaluation framework for AFC that comprises three types of approaches for evidence evaluation: reference-based, proxy-reference, and reference-less. We evaluate their effectiveness through agreement with human ratings and adversarial tests, and demonstrate that prompt-based scorers, particularly those leveraging LLMs and reference evidence, outperform traditional evaluation approaches.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.