 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleAcross Explorer: Exploring Communication Optimization for Scale-Across AI Model Training
May 23, 2026The rapid scaling of large language model training requires distributing GPU resources across multiple data center buildings and regions. We refer to such paradigm as "scale-across" training. As infrastructure expands, the system design space becomes increasingly intricate, encompassing new model architectures, hardware heterogeneity, and evolving communication patterns. Drawing from Meta's production experience, we highlight the complexities of deploying training jobs across a few data centers housing hundreds of thousands of GPUs. To accelerate exploration of the large design space and to enable efficient training for frontier model development, we conduct in-depth characterization of three key design dimensions: parallelism placement, parallelism scheduling, and network layer technologies. We then propose ScaleAcross Explorer, an optimizer that considers the interplay of design dimensions and holistically optimizes scale-across training. Testbed experiments and simulations demonstrate up to 64.62% training speedups over production configuration and up to 37.59% training speedups over the state-of-the-art baseline across a wide range of design points.
AIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Dec 30, 2025Making deep learning recommendation model (DLRM) training and inference fast and efficient is important. However, this presents three key system challenges - model architecture diversity, kernel primitive diversity, and hardware generation and architecture heterogeneity. This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architectures. KernelEvolve does so by operating at multiple programming abstractions, from Triton and CuTe DSL to low-level hardware agnostic languages, spanning the full hardware-software optimization stack. The kernel optimization process is described as graph-based search with selection policy, universal operator, fitness function, and termination rule, dynamically adapts to runtime execution context through retrieval-augmented prompt synthesis. We designed, implemented, and deployed KernelEvolve to optimize a wide variety of production recommendation models across generations of NVIDIA and AMD GPUs, as well as Meta's AI accelerators. We validate KernelEvolve on the publicly-available KernelBench suite, achieving 100% pass rate on all 250 problems across three difficulty levels, and 160 PyTorch ATen operators across three heterogeneous hardware platforms, demonstrating 100% correctness. KernelEvolve reduces development time from weeks to hours and achieves substantial performance improvements over PyTorch baselines across diverse production use cases and for heterogeneous AI systems at-scale. Beyond performance efficiency improvements, KernelEvolve significantly mitigates the programmability barrier for new AI hardware by enabling automated kernel generation for in-house developed AI hardware.
Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
Oct 02, 2025Training data plays a crucial role in Large Language Models (LLM) scaling, yet high quality data is of limited supply. Synthetic data techniques offer a potential path toward sidestepping these limitations. We conduct a large-scale empirical investigation (>1000 LLMs with >100k GPU hours) using a unified protocol and scaling laws, comparing natural web data, diverse synthetic types (rephrased text, generated textbooks), and mixtures of natural and synthetic data. Specifically, we found pre-training on rephrased synthetic data \textit{alone} is not faster than pre-training on natural web texts; while pre-training on 1/3 rephrased synthetic data mixed with 2/3 natural web texts can speed up 5-10x (to reach the same validation loss) at larger data budgets. Pre-training on textbook-style synthetic data \textit{alone} results in notably higher loss on many downstream domains especially at small data budgets. "Good" ratios of synthetic data in training data mixtures depend on the model size and data budget, empirically converging to ~30% for rephrased synthetic data. Larger generator models do not necessarily yield better pre-training data than ~8B-param models. These results contribute mixed evidence on "model collapse" during large-scale single-round (n=1) model training on synthetic data--training on rephrased synthetic data shows no degradation in performance in foreseeable scales whereas training on mixtures of textbook-style pure-generated synthetic data shows patterns predicted by "model collapse". Our work demystifies synthetic data in pre-training, validates its conditional benefits, and offers practical guidance.
Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead
Oct 02, 2025In post-training for reasoning Large Language Models (LLMs), the current state of practice trains LLMs in two independent stages: Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR, shortened as ``RL'' below). In this work, we challenge whether high SFT scores translate to improved performance after RL. We provide extensive counter-examples where this is not true. We find high SFT scores can be biased toward simpler or more homogeneous data and are not reliably predictive of subsequent RL gains or scaled-up post-training effectiveness. In some cases, RL training on models with improved SFT performance could lead to substantially worse outcome compared to RL on the base model without SFT. We study alternative metrics and identify generalization loss on held-out reasoning examples and Pass@large k performance to provide strong proxies for the RL outcome. We trained hundreds of models up to 12B-parameter with SFT and RLVR via GRPO and ran extensive evaluations on 7 math benchmarks with up to 256 repetitions, spending $>$1M GPU hours. Experiments include models from Llama3, Mistral-Nemo, Qwen3 and multiple state-of-the-art SFT/RL datasets. Compared to directly predicting from pre-RL performance, prediction based on generalization loss and Pass@large k achieves substantial higher precision, improving $R^2$ coefficient and Spearman's rank correlation coefficient by up to 0.5 (2x). This provides strong utility for broad use cases. For example, in most experiments, we find SFT training on unique examples for a one epoch underperforms training on half examples for two epochs, either after SFT or SFT-then-RL; With the same SFT budget, training only on short examples may lead to better SFT performance, though, it often leads to worse outcome after RL compared to training on examples with varying lengths. Evaluation tool will be open-sourced.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Revisiting Reliability in Large-Scale Machine Learning Research Clusters
Oct 29, 2024



Reliability is a fundamental challenge in operating large-scale machine learning (ML) infrastructures, particularly as the scale of ML models and training clusters continues to grow. Despite decades of research on infrastructure failures, the impact of job failures across different scales remains unclear. This paper presents a view of managing two large, multi-tenant ML clusters, providing quantitative analysis, operational experience, and our own perspective in understanding and addressing reliability concerns at scale. Our analysis reveals that while large jobs are most vulnerable to failures, smaller jobs make up the majority of jobs in the clusters and should be incorporated into optimization objectives. We identify key workload properties, compare them across clusters, and demonstrate essential reliability requirements for pushing the boundaries of ML training at scale. We hereby introduce a taxonomy of failures and key reliability metrics, analyze 11 months of data from two state-of-the-art ML environments with over 150 million A100 GPU hours and 4 million jobs. Building on our data, we fit a failure model to project Mean Time to Failure for various GPU scales. We further propose a method to estimate a related metric, Effective Training Time Ratio, as a function of job parameters, and we use this model to gauge the efficacy of potential software mitigations at scale. Our work provides valuable insights and future research directions for improving the reliability of AI supercomputer clusters, emphasizing the need for flexible, workload-agnostic, and reliability-aware infrastructure, system software, and algorithms.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
Validating Large Language Models with ReLM
Nov 21, 2022

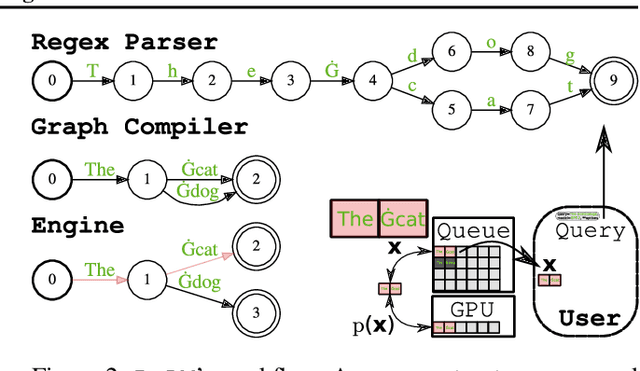

Although large language models (LLMs) have been touted for their ability to generate natural-sounding text, there are growing concerns around possible negative effects of LLMs such as data memorization, bias, and inappropriate language. Unfortunately, the complexity and generation capacities of LLMs make validating (and correcting) such concerns difficult. In this work, we introduce ReLM, a system for validating and querying LLMs using standard regular expressions. ReLM formalizes and enables a broad range of language model evaluations, reducing complex evaluation rules to simple regular expression queries. Our results exploring queries surrounding memorization, gender bias, toxicity, and language understanding show that ReLM achieves up to 15x higher system efficiency, 2.5x data efficiency, and increased statistical and prompt-tuning coverage compared to state-of-the-art ad-hoc queries. ReLM offers a competitive and general baseline for the increasingly important problem of LLM validation.