 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Compressed Records: Taking a Byte out of Deep Learning Data
Paper and Code
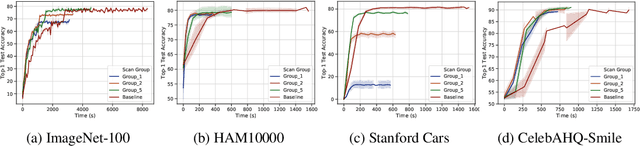
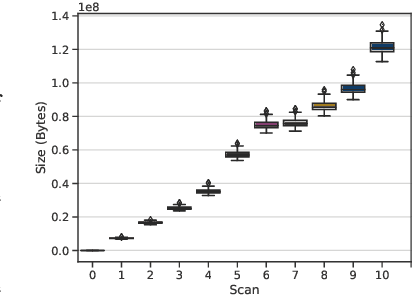
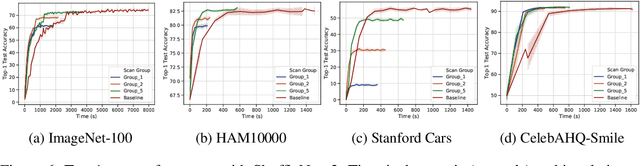
Deep learning training accesses vast amounts of data at high velocity, posing challenges for datasets retrieved over commodity networks and storage devices. We introduce a way to dynamically reduce the overhead of fetching and transporting training data with a method we term Progressive Compressed Records (PCRs). PCRs deviate from previous formats by using progressive compression to convert a single dataset into multiple datasets of increasing fidelity---all without adding to the total dataset size. Empirically, we implement PCRs and evaluate them on a wide range of datasets: ImageNet, HAM10000, Stanford Cars, and CelebA-HQ. Our results show that different tasks can tolerate different levels of compression. PCRs use an on-disk layout that enables applications to efficiently and dynamically access appropriate levels of compression at runtime. In turn, we demonstrate that PCRs can seamlessly enable a 2x speedup in training time on average over baseline formats.