 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating Large Language Models with ReLM
Nov 21, 2022

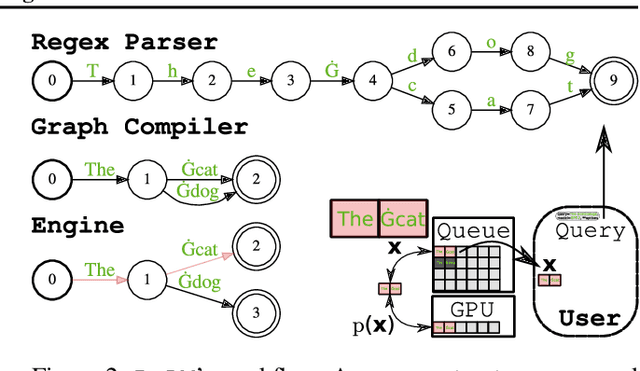

Although large language models (LLMs) have been touted for their ability to generate natural-sounding text, there are growing concerns around possible negative effects of LLMs such as data memorization, bias, and inappropriate language. Unfortunately, the complexity and generation capacities of LLMs make validating (and correcting) such concerns difficult. In this work, we introduce ReLM, a system for validating and querying LLMs using standard regular expressions. ReLM formalizes and enables a broad range of language model evaluations, reducing complex evaluation rules to simple regular expression queries. Our results exploring queries surrounding memorization, gender bias, toxicity, and language understanding show that ReLM achieves up to 15x higher system efficiency, 2.5x data efficiency, and increased statistical and prompt-tuning coverage compared to state-of-the-art ad-hoc queries. ReLM offers a competitive and general baseline for the increasingly important problem of LLM validation.
Plumber: Diagnosing and Removing Performance Bottlenecks in Machine Learning Data Pipelines
Nov 07, 2021
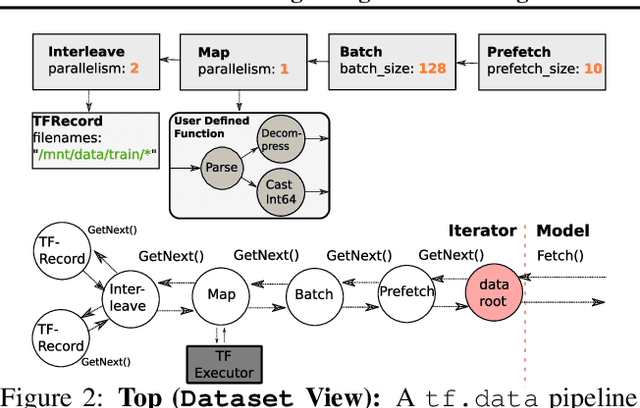
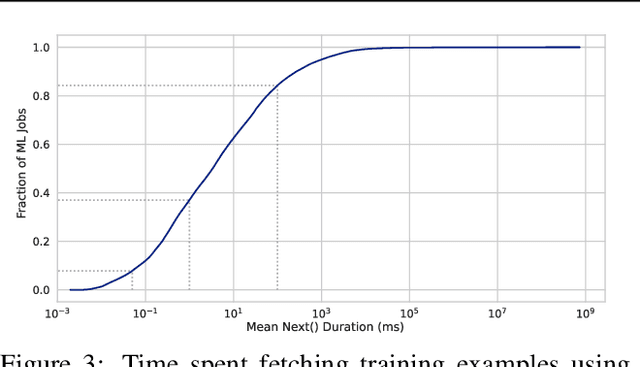
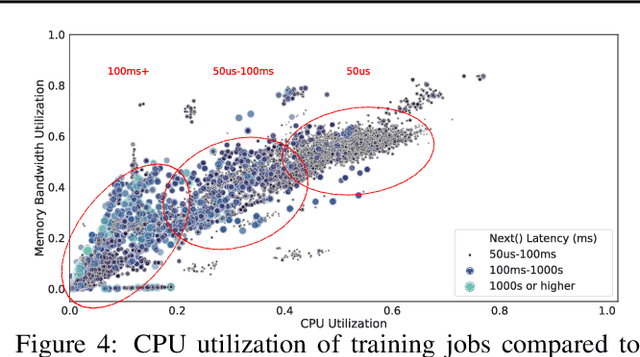
Input pipelines, which ingest and transform input data, are an essential part of training Machine Learning (ML) models. However, it is challenging to implement efficient input pipelines, as it requires reasoning about parallelism, asynchrony, and variability in fine-grained profiling information. Our analysis of over 2 million ML jobs in Google datacenters reveals that a significant fraction of model training jobs could benefit from faster input data pipelines. At the same time, our analysis reveals that most jobs do not saturate host hardware, pointing in the direction of software-based bottlenecks. Motivated by these findings, we propose Plumber, a tool for finding bottlenecks in ML input pipelines. Plumber uses an extensible and interprettable operational analysis analytical model to automatically tune parallelism, prefetching, and caching under host resource constraints. Across five representative ML pipelines, Plumber obtains speedups of up to 46x for misconfigured pipelines. By automating caching, Plumber obtains end-to-end speedups of over 40% compared to state-of-the-art tuners.
Progressive Compressed Records: Taking a Byte out of Deep Learning Data
Nov 01, 2019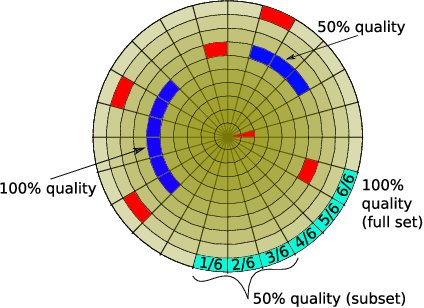
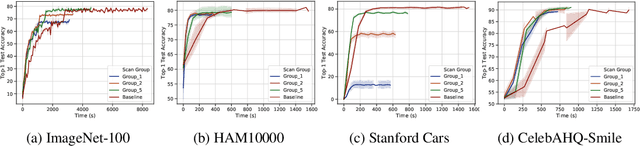
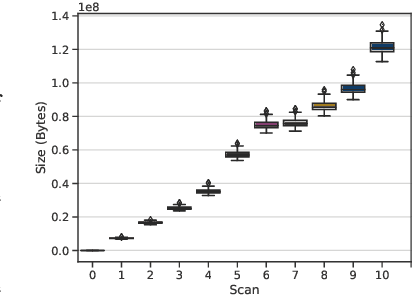
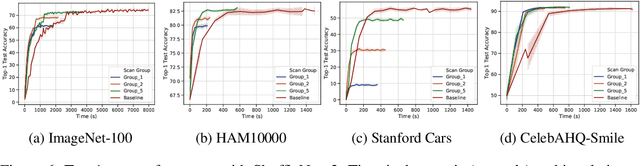
Deep learning training accesses vast amounts of data at high velocity, posing challenges for datasets retrieved over commodity networks and storage devices. We introduce a way to dynamically reduce the overhead of fetching and transporting training data with a method we term Progressive Compressed Records (PCRs). PCRs deviate from previous formats by using progressive compression to convert a single dataset into multiple datasets of increasing fidelity---all without adding to the total dataset size. Empirically, we implement PCRs and evaluate them on a wide range of datasets: ImageNet, HAM10000, Stanford Cars, and CelebA-HQ. Our results show that different tasks can tolerate different levels of compression. PCRs use an on-disk layout that enables applications to efficiently and dynamically access appropriate levels of compression at runtime. In turn, we demonstrate that PCRs can seamlessly enable a 2x speedup in training time on average over baseline formats.