 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A case for disaggregation of ML data processing
Oct 28, 2022



Machine Learning (ML) computation requires feeding input data for the models to ingest. Traditionally, input data processing happens on the same host as the ML computation. The input data processing can however become a bottleneck of the ML computation if there are insufficient resources to process data quickly enough. This slows down the ML computation and wastes valuable and scarce ML hardware (e.g. GPUs and TPUs) used by the ML computation. In this paper, we present tf.data service, a disaggregated input data processing service built on top of tf.data. Our work goes beyond describing the design and implementation of a new system which disaggregates preprocessing from ML computation and presents: (1) empirical evidence based on production workloads for the need of disaggregation, as well as quantitative evaluation of the impact disaggregation has on the performance and cost of production workloads, (2) benefits of disaggregation beyond horizontal scaling, (3) analysis of tf.data service's adoption at Google, the lessons learned during building and deploying the system and potential future lines of research opened up by our work. We demonstrate that horizontally scaling data processing using tf.data service helps remove input bottlenecks, achieving speedups of up to 110x and job cost reductions of up to 89x. We further show that tf.data service can support computation reuse through data sharing across ML jobs with identical data processing pipelines (e.g. hyperparameter tuning jobs), incurring no performance penalty and reducing overall resource cost. Finally, we show that tf.data service advanced features can benefit performance of non-input bound jobs; in particular, coordinated data reads through tf.data service can yield up to 2x speedups and job cost savings for NLP jobs.
Plumber: Diagnosing and Removing Performance Bottlenecks in Machine Learning Data Pipelines
Nov 07, 2021
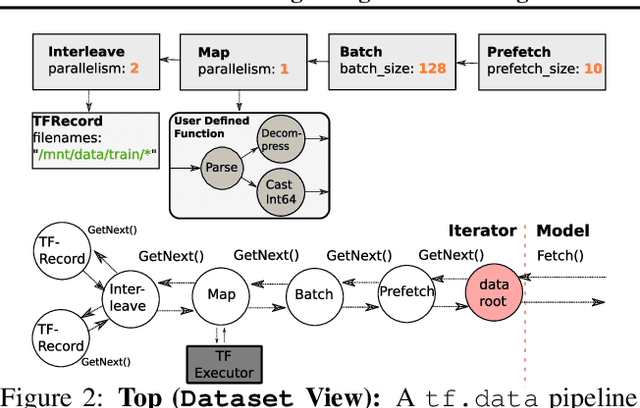
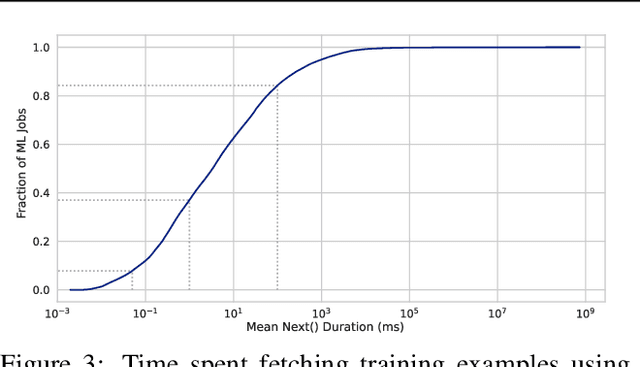
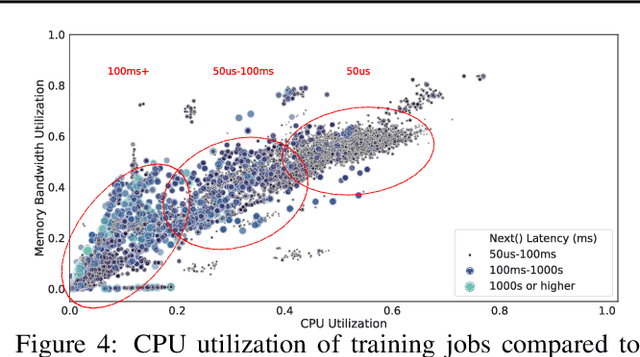
Input pipelines, which ingest and transform input data, are an essential part of training Machine Learning (ML) models. However, it is challenging to implement efficient input pipelines, as it requires reasoning about parallelism, asynchrony, and variability in fine-grained profiling information. Our analysis of over 2 million ML jobs in Google datacenters reveals that a significant fraction of model training jobs could benefit from faster input data pipelines. At the same time, our analysis reveals that most jobs do not saturate host hardware, pointing in the direction of software-based bottlenecks. Motivated by these findings, we propose Plumber, a tool for finding bottlenecks in ML input pipelines. Plumber uses an extensible and interprettable operational analysis analytical model to automatically tune parallelism, prefetching, and caching under host resource constraints. Across five representative ML pipelines, Plumber obtains speedups of up to 46x for misconfigured pipelines. By automating caching, Plumber obtains end-to-end speedups of over 40% compared to state-of-the-art tuners.
tf.data: A Machine Learning Data Processing Framework
Feb 23, 2021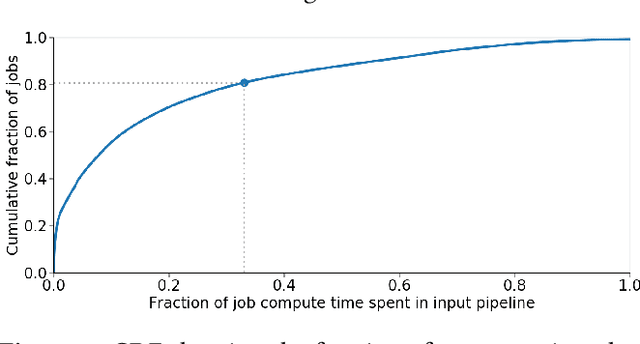

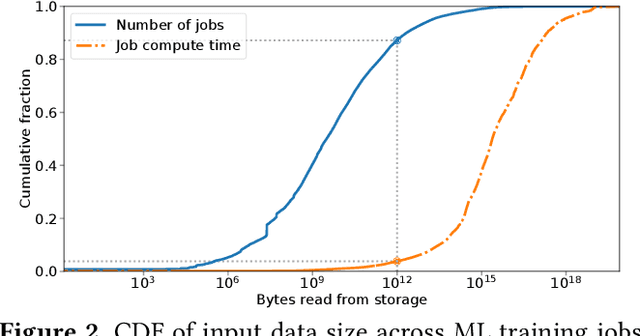
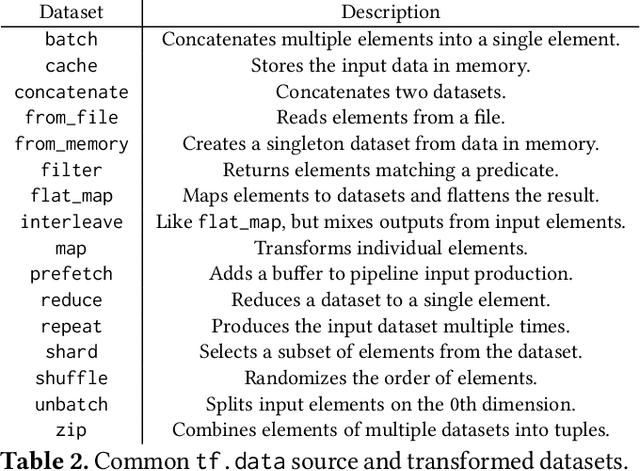
Training machine learning models requires feeding input data for models to ingest. Input pipelines for machine learning jobs are often challenging to implement efficiently as they require reading large volumes of data, applying complex transformations, and transferring data to hardware accelerators while overlapping computation and communication to achieve optimal performance. We present tf.data, a framework for building and executing efficient input pipelines for machine learning jobs. The tf.data API provides operators which can be parameterized with user-defined computation, composed, and reused across different machine learning domains. These abstractions allow users to focus on the application logic of data processing, while tf.data's runtime ensures that pipelines run efficiently. We demonstrate that input pipeline performance is critical to the end-to-end training time of state-of-the-art machine learning models. tf.data delivers the high performance required, while avoiding the need for manual tuning of performance knobs. We show that tf.data features, such as parallelism, caching, static optimizations, and non-deterministic execution are essential for high performance. Finally, we characterize machine learning input pipelines for millions of jobs that ran in Google's fleet, showing that input data processing is highly diverse and consumes a significant fraction of job resources. Our analysis motivates future research directions, such as sharing computation across jobs and pushing data projection to the storage layer.
Towards ML Engineering: A Brief History Of TensorFlow Extended
Oct 07, 2020Software Engineering, as a discipline, has matured over the past 5+ decades. The modern world heavily depends on it, so the increased maturity of Software Engineering was an eventuality. Practices like testing and reliable technologies help make Software Engineering reliable enough to build industries upon. Meanwhile, Machine Learning (ML) has also grown over the past 2+ decades. ML is used more and more for research, experimentation and production workloads. ML now commonly powers widely-used products integral to our lives. But ML Engineering, as a discipline, has not widely matured as much as its Software Engineering ancestor. Can we take what we have learned and help the nascent field of applied ML evolve into ML Engineering the way Programming evolved into Software Engineering [1]? In this article we will give a whirlwind tour of Sibyl [2] and TensorFlow Extended (TFX) [3], two successive end-to-end (E2E) ML platforms at Alphabet. We will share the lessons learned from over a decade of applied ML built on these platforms, explain both their similarities and their differences, and expand on the shifts (both mental and technical) that helped us on our journey. In addition, we will highlight some of the capabilities of TFX that help realize several aspects of ML Engineering. We argue that in order to unlock the gains ML can bring, organizations should advance the maturity of their ML teams by investing in robust ML infrastructure and promoting ML Engineering education. We also recommend that before focusing on cutting-edge ML modeling techniques, product leaders should invest more time in adopting interoperable ML platforms for their organizations. In closing, we will also share a glimpse into the future of TFX.