 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA case for disaggregation of ML data processing
Oct 28, 2022



Machine Learning (ML) computation requires feeding input data for the models to ingest. Traditionally, input data processing happens on the same host as the ML computation. The input data processing can however become a bottleneck of the ML computation if there are insufficient resources to process data quickly enough. This slows down the ML computation and wastes valuable and scarce ML hardware (e.g. GPUs and TPUs) used by the ML computation. In this paper, we present tf.data service, a disaggregated input data processing service built on top of tf.data. Our work goes beyond describing the design and implementation of a new system which disaggregates preprocessing from ML computation and presents: (1) empirical evidence based on production workloads for the need of disaggregation, as well as quantitative evaluation of the impact disaggregation has on the performance and cost of production workloads, (2) benefits of disaggregation beyond horizontal scaling, (3) analysis of tf.data service's adoption at Google, the lessons learned during building and deploying the system and potential future lines of research opened up by our work. We demonstrate that horizontally scaling data processing using tf.data service helps remove input bottlenecks, achieving speedups of up to 110x and job cost reductions of up to 89x. We further show that tf.data service can support computation reuse through data sharing across ML jobs with identical data processing pipelines (e.g. hyperparameter tuning jobs), incurring no performance penalty and reducing overall resource cost. Finally, we show that tf.data service advanced features can benefit performance of non-input bound jobs; in particular, coordinated data reads through tf.data service can yield up to 2x speedups and job cost savings for NLP jobs.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022

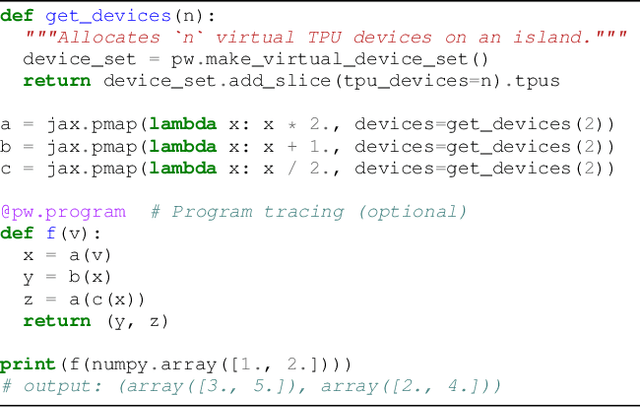

We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.