 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Matryoshka Quantization
Feb 10, 2025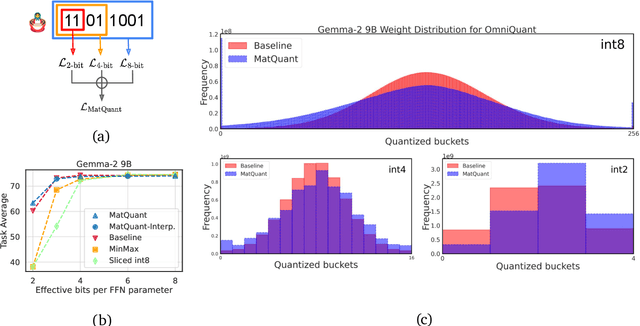
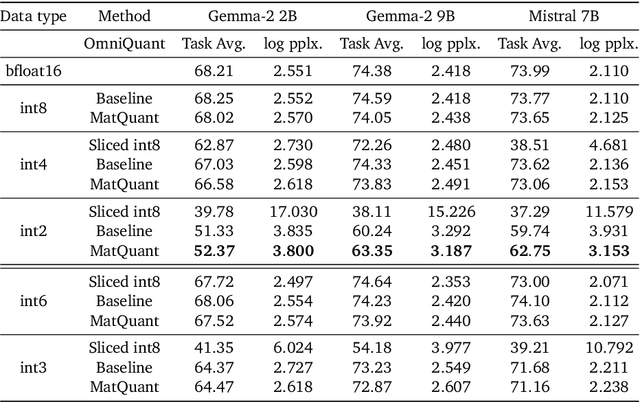
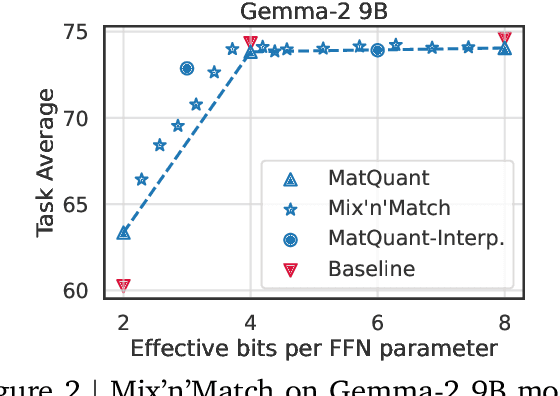
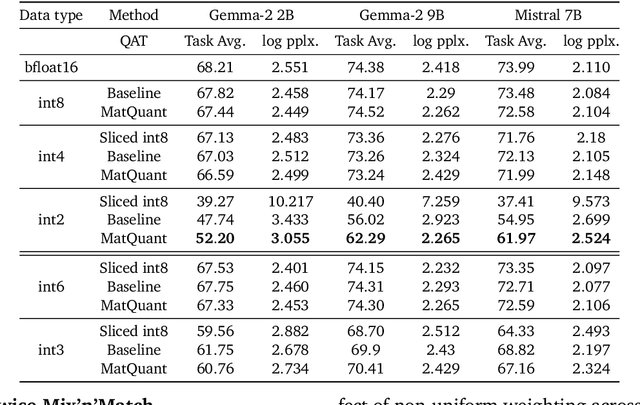
Quantizing model weights is critical for reducing the communication and inference costs of large models. However, quantizing models -- especially to low precisions like int4 or int2 -- requires a trade-off in model quality; int2, in particular, is known to severely degrade model quality. Consequently, practitioners are often forced to maintain multiple models with different quantization levels or serve a single model that best satisfies the quality-latency trade-off. On the other hand, integer data types, such as int8, inherently possess a nested (Matryoshka) structure where smaller bit-width integers, like int4 or int2, are nested within the most significant bits. This paper proposes Matryoshka Quantization (MatQuant), a novel multi-scale quantization technique that addresses the challenge of needing multiple quantized models. It allows training and maintaining just one model, which can then be served at different precision levels. Furthermore, due to the co-training and co-distillation regularization provided by MatQuant, the int2 precision models extracted by MatQuant can be up to $10\%$ more accurate than standard int2 quantization (using techniques like QAT or OmniQuant). This represents significant progress in model quantization, demonstrated by the fact that, with the same recipe, an int2 FFN-quantized Gemma-2 9B model is more accurate than an int8 FFN-quantized Gemma-2 2B model.
Shaping AI's Impact on Billions of Lives
Dec 03, 2024
Artificial Intelligence (AI), like any transformative technology, has the potential to be a double-edged sword, leading either toward significant advancements or detrimental outcomes for society as a whole. As is often the case when it comes to widely-used technologies in market economies (e.g., cars and semiconductor chips), commercial interest tends to be the predominant guiding factor. The AI community is at risk of becoming polarized to either take a laissez-faire attitude toward AI development, or to call for government overregulation. Between these two poles we argue for the community of AI practitioners to consciously and proactively work for the common good. This paper offers a blueprint for a new type of innovation infrastructure including 18 concrete milestones to guide AI research in that direction. Our view is that we are still in the early days of practical AI, and focused efforts by practitioners, policymakers, and other stakeholders can still maximize the upsides of AI and minimize its downsides. We talked to luminaries such as recent Nobelist John Jumper on science, President Barack Obama on governance, former UN Ambassador and former National Security Advisor Susan Rice on security, philanthropist Eric Schmidt on several topics, and science fiction novelist Neal Stephenson on entertainment. This ongoing dialogue and collaborative effort has produced a comprehensive, realistic view of what the actual impact of AI could be, from a diverse assembly of thinkers with deep understanding of this technology and these domains. From these exchanges, five recurring guidelines emerged, which form the cornerstone of a framework for beginning to harness AI in service of the public good. They not only guide our efforts in discovery but also shape our approach to deploying this transformative technology responsibly and ethically.
That Chip Has Sailed: A Critique of Unfounded Skepticism Around AI for Chip Design
Nov 15, 2024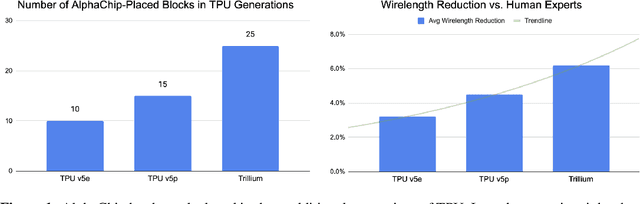
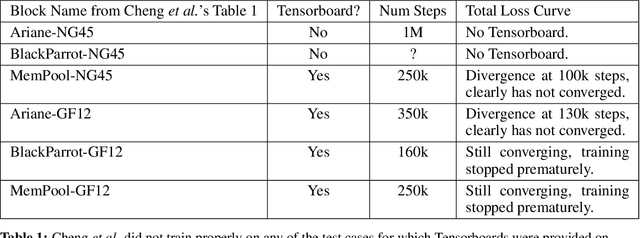

In 2020, we introduced a deep reinforcement learning method capable of generating superhuman chip layouts, which we then published in Nature and open-sourced on GitHub. AlphaChip has inspired an explosion of work on AI for chip design, and has been deployed in state-of-the-art chips across Alphabet and extended by external chipmakers. Even so, a non-peer-reviewed invited paper at ISPD 2023 questioned its performance claims, despite failing to run our method as described in Nature. For example, it did not pre-train the RL method (removing its ability to learn from prior experience), used substantially fewer compute resources (20x fewer RL experience collectors and half as many GPUs), did not train to convergence (standard practice in machine learning), and evaluated on test cases that are not representative of modern chips. Recently, Igor Markov published a meta-analysis of three papers: our peer-reviewed Nature paper, the non-peer-reviewed ISPD paper, and Markov's own unpublished paper (though he does not disclose that he co-authored it). Although AlphaChip has already achieved widespread adoption and impact, we publish this response to ensure that no one is wrongly discouraged from innovating in this impactful area.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Brainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
Efficiently Scaling Transformer Inference
Nov 09, 2022



We study the problem of efficient generative inference for Transformer models, in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Better understanding of the engineering tradeoffs for inference for large Transformer-based models is important as use cases of these models are growing rapidly throughout application areas. We develop a simple analytical model for inference efficiency to select the best multi-dimensional partitioning techniques optimized for TPU v4 slices based on the application requirements. We combine these with a suite of low-level optimizations to achieve a new Pareto frontier on the latency and model FLOPS utilization (MFU) tradeoffs on 500B+ parameter models that outperforms the FasterTransformer suite of benchmarks. We further show that with appropriate partitioning, the lower memory requirements of multiquery attention (i.e. multiple query heads share single key/value head) enables scaling up to 32x larger context lengths. Finally, we achieve a low-batch-size latency of 29ms per token during generation (using int8 weight quantization) and a 76% MFU during large-batch-size processing of input tokens, while supporting a long 2048-token context length on the PaLM 540B parameter model.