 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
Dec 27, 2020
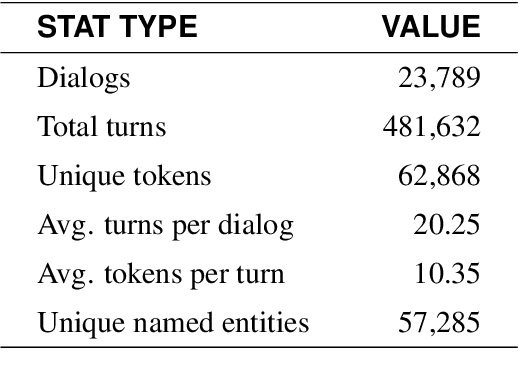


We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The movie ticketing conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to "make sense" 86.5 percent of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model's API call predictions were rated to be correct 93.9 percent of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. We are publicly releasing the TicketTalk dataset with this paper to facilitate future work on transaction-based dialogs.
Multilingual Synthetic Question and Answer Generation for Cross-Lingual Reading Comprehension
Oct 22, 2020

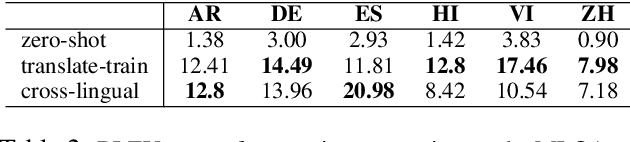

We propose a simple method to generate large amounts of multilingual question and answer pairs by a single generative model. These synthetic samples are then applied to augment the available gold multilingual ones to improve the performance of multilingual QA models on target languages. Our approach only requires existence of automatically translated samples from English to the target domain, thus removing the need for human annotations in the target languages. Experimental results show our proposed approach achieves significant gains in a number of multilingual datasets.