 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does LLM Refinement Actually Improve? A Systematic Study on Document-Level Literary Translation
May 13, 2026Iterative self-refinement is a simple inference-time strategy for machine translation: an LLM revises its own translation over multiple inference-time passes. Yet document-scale refinement remains poorly understood: 1) which pipelines work best, 2) what quality dimensions improve, and 3) how refiners behave. In this paper, we present a systematic study of document-level literary translation, covering nine LLMs and seven language pairs. Across nine translation-refinement granularity combinations and five refinement strategies, we find a robust recipe: document-level MT followed by segment-level refinement yields strong and stable improvements. In contrast, document-level refinement often makes fewer edits and leads to smaller or less reliable gains. Beyond granularity, A simple general refinement prompt consistently outperforms error-specific prompting and evaluate-then-refine schemes. Our large-scale human evaluation shows that refinement gains come primarily from fluency, style, and terminology, with limited and less consistent improvements in adequacy. Experiments varying model strength reveal refinement projects outputs toward the refiner's distribution rather than performing targeted error repair. These findings clarify the mechanisms and limitations of current refinement approaches.
BERAG: Bayesian Ensemble Retrieval-Augmented Generation for Knowledge-based Visual Question Answering
Apr 24, 2026A common approach to question answering with retrieval-augmented generation (RAG) is to concatenate documents into a single context and pass it to a language model to generate an answer. While simple, this strategy can obscure the contribution of individual documents, making attribution difficult and contributing to the ``lost-in-the-middle'' effect, where relevant information in long contexts is overlooked. Concatenation also scales poorly: computational cost grows quadratically with context length, a problem that becomes especially severe when the context includes visual data, as in visual question answering. Attempts to mitigate these issues by limiting context length can further restrict performance by preventing models from benefiting from the improved recall offered by deeper retrieval. We propose Bayesian Ensemble Retrieval-Augmented Generation (BERAG), along with Bayesian Ensemble Fine-Tuning (BEFT), as a RAG framework in which language models are conditioned on individual retrieved documents rather than a single combined context. BERAG treats document posterior probabilities as ensemble weights and updates them token by token using Bayes' rule during generation. This approach enables probabilistic re-ranking, parallel memory usage, and clear attribution of document contribution, making it well-suited for large document collections. We evaluate BERAG and BEFT primarily on knowledge-based visual question answering tasks, where models must reason over long, imperfect retrieval lists. The results show substantial improvements over standard RAG, including strong gains on Document Visual Question Answering and multimodal needle-in-a-haystack benchmarks. We also demonstrate that BERAG mitigates the ``lost-in-the-middle'' effect. The document posterior can be used to detect insufficient grounding and trigger deflection, while document pruning enables faster decoding than standard RAG.
Benchmarking Deflection and Hallucination in Large Vision-Language Models
Apr 13, 2026Large Vision-Language Models (LVLMs) increasingly rely on retrieval to answer knowledge-intensive multimodal questions. Existing benchmarks overlook conflicts between visual and textual evidence and the importance of generating deflections (e.g., Sorry, I cannot answer...) when retrieved knowledge is incomplete. These benchmarks also suffer from rapid obsolescence, as growing LVLM training sets allow models to answer many questions without retrieval. We address these gaps with three contributions. First, we propose a dynamic data curation pipeline that preserves benchmark difficulty over time by filtering for genuinely retrieval-dependent samples. Second, we introduce VLM-DeflectionBench, a benchmark of 2,775 samples spanning diverse multimodal retrieval settings, designed to probe model behaviour under conflicting or insufficient evidence. Third, we define a fine-grained evaluation protocol with four scenarios that disentangle parametric memorization from retrieval robustness. Experiments across 20 state-of-the-art LVLMs indicate that models usually fail to deflect in the presence of noisy or misleading evidence. Our results highlight the need to evaluate not only what models know, but how they behave when they do not, and serve as a reusable and extensible benchmark for reliable KB-VQA evaluation. All resources will be publicly available upon publication.
According to Me: Long-Term Personalized Referential Memory QA
Mar 02, 2026Personalized AI assistants must recall and reason over long-term user memory, which naturally spans multiple modalities and sources such as images, videos, and emails. However, existing Long-term Memory benchmarks focus primarily on dialogue history, failing to capture realistic personalized references grounded in lived experience. We introduce ATM-Bench, the first benchmark for multimodal, multi-source personalized referential Memory QA. ATM-Bench contains approximately four years of privacy-preserving personal memory data and human-annotated question-answer pairs with ground-truth memory evidence, including queries that require resolving personal references, multi-evidence reasoning from multi-source and handling conflicting evidence. We propose Schema-Guided Memory (SGM) to structurally represent memory items originated from different sources. In experiments, we implement 5 state-of-the-art memory systems along with a standard RAG baseline and evaluate variants with different memory ingestion, retrieval, and answer generation techniques. We find poor performance (under 20\% accuracy) on the ATM-Bench-Hard set, and that SGM improves performance over Descriptive Memory commonly adopted in prior works. Code available at: https://github.com/JingbiaoMei/ATM-Bench
Exploring Fine-Tuning for In-Context Retrieval and Efficient KV-Caching in Long-Context Language Models
Jan 26, 2026With context windows of millions of tokens, Long-Context Language Models (LCLMs) can encode entire document collections, offering a strong alternative to conventional retrieval-augmented generation (RAG). However, it remains unclear whether fine-tuning strategies can improve long-context performance and translate to greater robustness under KV-cache compression techniques. In this work, we investigate which training strategies most effectively enhance LCLMs' ability to identify and use relevant information, as well as enhancing their robustness under KV-cache compression. Our experiments show substantial in-domain improvements, achieving gains of up to +20 points over the base model. However, out-of-domain generalization remains task dependent with large variance -- LCLMs excels on finance questions (+9 points), while RAG shows stronger performance on multiple-choice questions (+6 points) over the baseline models. Finally, we show that our fine-tuning approaches bring moderate improvements in robustness under KV-cache compression, with gains varying across tasks.
CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
Jan 05, 2026Current work on robot failure detection and correction typically operate in a post hoc manner, analyzing errors and applying corrections only after failures occur. This work introduces CycleVLA, a system that equips Vision-Language-Action models (VLAs) with proactive self-correction, the capability to anticipate incipient failures and recover before they fully manifest during execution. CycleVLA achieves this by integrating a progress-aware VLA that flags critical subtask transition points where failures most frequently occur, a VLM-based failure predictor and planner that triggers subtask backtracking upon predicted failure, and a test-time scaling strategy based on Minimum Bayes Risk (MBR) decoding to improve retry success after backtracking. Extensive experiments show that CycleVLA improves performance for both well-trained and under-trained VLAs, and that MBR serves as an effective zero-shot test-time scaling strategy for VLAs. Project Page: https://dannymcy.github.io/cyclevla/
XRAG: Cross-lingual Retrieval-Augmented Generation
May 15, 2025We propose XRAG, a novel benchmark designed to evaluate the generation abilities of LLMs in cross-lingual Retrieval-Augmented Generation (RAG) settings where the user language does not match the retrieval results. XRAG is constructed from recent news articles to ensure that its questions require external knowledge to be answered. It covers the real-world scenarios of monolingual and multilingual retrieval, and provides relevancy annotations for each retrieved document. Our novel dataset construction pipeline results in questions that require complex reasoning, as evidenced by the significant gap between human and LLM performance. Consequently, XRAG serves as a valuable benchmark for studying LLM reasoning abilities, even before considering the additional cross-lingual complexity. Experimental results on five LLMs uncover two previously unreported challenges in cross-lingual RAG: 1) in the monolingual retrieval setting, all evaluated models struggle with response language correctness; 2) in the multilingual retrieval setting, the main challenge lies in reasoning over retrieved information across languages rather than generation of non-English text.
Learning to Reason Over Time: Timeline Self-Reflection for Improved Temporal Reasoning in Language Models
Apr 07, 2025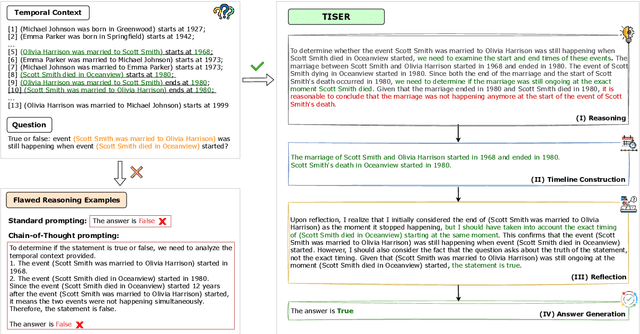
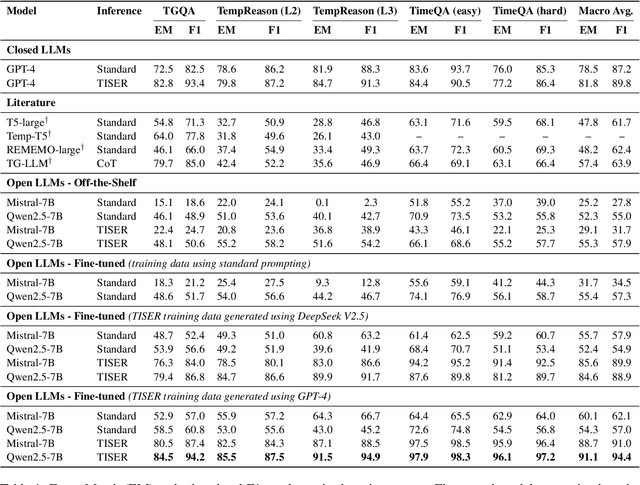
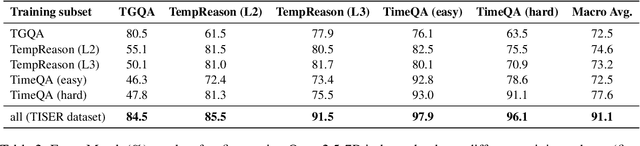
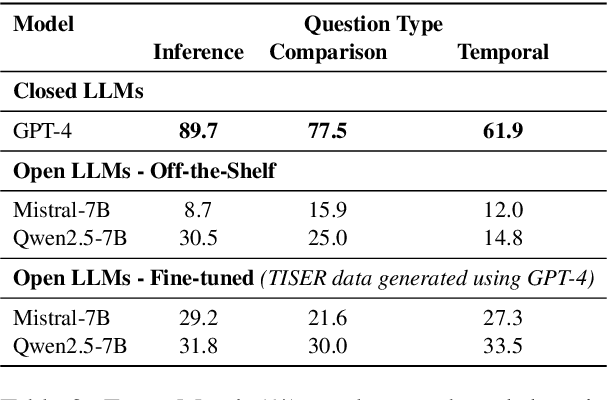
Large Language Models (LLMs) have emerged as powerful tools for generating coherent text, understanding context, and performing reasoning tasks. However, they struggle with temporal reasoning, which requires processing time-related information such as event sequencing, durations, and inter-temporal relationships. These capabilities are critical for applications including question answering, scheduling, and historical analysis. In this paper, we introduce TISER, a novel framework that enhances the temporal reasoning abilities of LLMs through a multi-stage process that combines timeline construction with iterative self-reflection. Our approach leverages test-time scaling to extend the length of reasoning traces, enabling models to capture complex temporal dependencies more effectively. This strategy not only boosts reasoning accuracy but also improves the traceability of the inference process. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, including out-of-distribution test sets, and reveal that TISER enables smaller open-source models to surpass larger closed-weight models on challenging temporal reasoning tasks.
Improved Fine-Tuning of Large Multimodal Models for Hateful Meme Detection
Feb 18, 2025Hateful memes have become a significant concern on the Internet, necessitating robust automated detection systems. While large multimodal models have shown strong generalization across various tasks, they exhibit poor generalization to hateful meme detection due to the dynamic nature of memes tied to emerging social trends and breaking news. Recent work further highlights the limitations of conventional supervised fine-tuning for large multimodal models in this context. To address these challenges, we propose Large Multimodal Model Retrieval-Guided Contrastive Learning (LMM-RGCL), a novel two-stage fine-tuning framework designed to improve both in-domain accuracy and cross-domain generalization. Experimental results on six widely used meme classification datasets demonstrate that LMM-RGCL achieves state-of-the-art performance, outperforming agent-based systems such as VPD-PALI-X-55B. Furthermore, our method effectively generalizes to out-of-domain memes under low-resource settings, surpassing models like GPT-4o.
Retrieving Contextual Information for Long-Form Question Answering using Weak Supervision
Oct 11, 2024Long-form question answering (LFQA) aims at generating in-depth answers to end-user questions, providing relevant information beyond the direct answer. However, existing retrievers are typically optimized towards information that directly targets the question, missing out on such contextual information. Furthermore, there is a lack of training data for relevant context. To this end, we propose and compare different weak supervision techniques to optimize retrieval for contextual information. Experiments demonstrate improvements on the end-to-end QA performance on ASQA, a dataset for long-form question answering. Importantly, as more contextual information is retrieved, we improve the relevant page recall for LFQA by 14.7% and the groundedness of generated long-form answers by 12.5%. Finally, we show that long-form answers often anticipate likely follow-up questions, via experiments on a conversational QA dataset.