 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fine-Tuning for In-Context Retrieval and Efficient KV-Caching in Long-Context Language Models
Jan 26, 2026With context windows of millions of tokens, Long-Context Language Models (LCLMs) can encode entire document collections, offering a strong alternative to conventional retrieval-augmented generation (RAG). However, it remains unclear whether fine-tuning strategies can improve long-context performance and translate to greater robustness under KV-cache compression techniques. In this work, we investigate which training strategies most effectively enhance LCLMs' ability to identify and use relevant information, as well as enhancing their robustness under KV-cache compression. Our experiments show substantial in-domain improvements, achieving gains of up to +20 points over the base model. However, out-of-domain generalization remains task dependent with large variance -- LCLMs excels on finance questions (+9 points), while RAG shows stronger performance on multiple-choice questions (+6 points) over the baseline models. Finally, we show that our fine-tuning approaches bring moderate improvements in robustness under KV-cache compression, with gains varying across tasks.
GaRAGe: A Benchmark with Grounding Annotations for RAG Evaluation
Jun 09, 2025We present GaRAGe, a large RAG benchmark with human-curated long-form answers and annotations of each grounding passage, allowing a fine-grained evaluation of whether LLMs can identify relevant grounding when generating RAG answers. Our benchmark contains 2366 questions of diverse complexity, dynamism, and topics, and includes over 35K annotated passages retrieved from both private document sets and the Web, to reflect real-world RAG use cases. This makes it an ideal test bed to evaluate an LLM's ability to identify only the relevant information necessary to compose a response, or provide a deflective response when there is insufficient information. Evaluations of multiple state-of-the-art LLMs on GaRAGe show that the models tend to over-summarise rather than (a) ground their answers strictly on the annotated relevant passages (reaching at most a Relevance-Aware Factuality Score of 60%), or (b) deflect when no relevant grounding is available (reaching at most 31% true positive rate in deflections). The F1 in attribution to relevant sources is at most 58.9%, and we show that performance is particularly reduced when answering time-sensitive questions and when having to draw knowledge from sparser private grounding sources.
Learning to Reason Over Time: Timeline Self-Reflection for Improved Temporal Reasoning in Language Models
Apr 07, 2025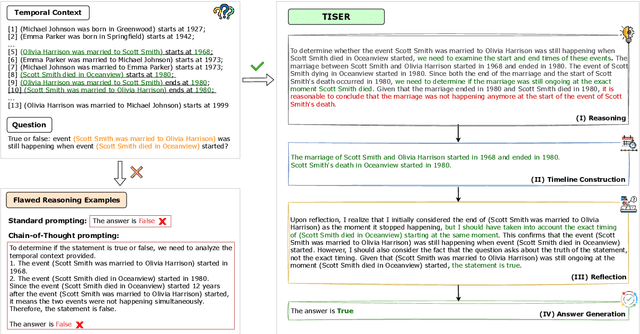
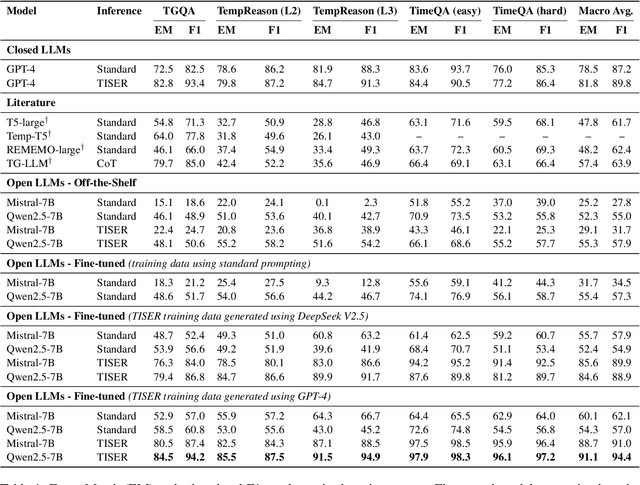
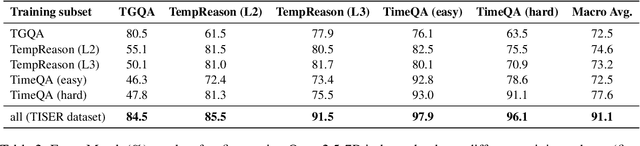
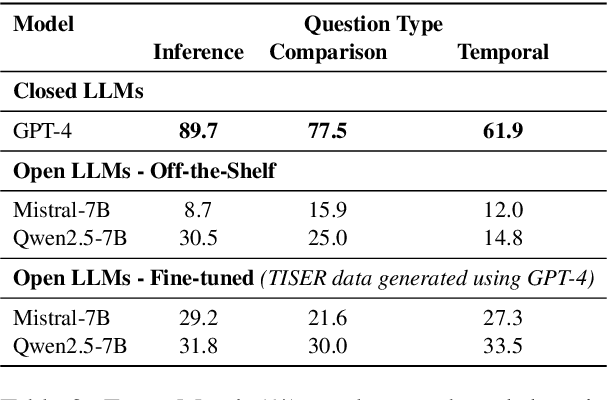
Large Language Models (LLMs) have emerged as powerful tools for generating coherent text, understanding context, and performing reasoning tasks. However, they struggle with temporal reasoning, which requires processing time-related information such as event sequencing, durations, and inter-temporal relationships. These capabilities are critical for applications including question answering, scheduling, and historical analysis. In this paper, we introduce TISER, a novel framework that enhances the temporal reasoning abilities of LLMs through a multi-stage process that combines timeline construction with iterative self-reflection. Our approach leverages test-time scaling to extend the length of reasoning traces, enabling models to capture complex temporal dependencies more effectively. This strategy not only boosts reasoning accuracy but also improves the traceability of the inference process. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, including out-of-distribution test sets, and reveal that TISER enables smaller open-source models to surpass larger closed-weight models on challenging temporal reasoning tasks.
Retrieving Contextual Information for Long-Form Question Answering using Weak Supervision
Oct 11, 2024Long-form question answering (LFQA) aims at generating in-depth answers to end-user questions, providing relevant information beyond the direct answer. However, existing retrievers are typically optimized towards information that directly targets the question, missing out on such contextual information. Furthermore, there is a lack of training data for relevant context. To this end, we propose and compare different weak supervision techniques to optimize retrieval for contextual information. Experiments demonstrate improvements on the end-to-end QA performance on ASQA, a dataset for long-form question answering. Importantly, as more contextual information is retrieved, we improve the relevant page recall for LFQA by 14.7% and the groundedness of generated long-form answers by 12.5%. Finally, we show that long-form answers often anticipate likely follow-up questions, via experiments on a conversational QA dataset.
Strong and Efficient Baselines for Open Domain Conversational Question Answering
Oct 23, 2023Unlike the Open Domain Question Answering (ODQA) setting, the conversational (ODConvQA) domain has received limited attention when it comes to reevaluating baselines for both efficiency and effectiveness. In this paper, we study the State-of-the-Art (SotA) Dense Passage Retrieval (DPR) retriever and Fusion-in-Decoder (FiD) reader pipeline, and show that it significantly underperforms when applied to ODConvQA tasks due to various limitations. We then propose and evaluate strong yet simple and efficient baselines, by introducing a fast reranking component between the retriever and the reader, and by performing targeted finetuning steps. Experiments on two ODConvQA tasks, namely TopiOCQA and OR-QuAC, show that our method improves the SotA results, while reducing reader's latency by 60%. Finally, we provide new and valuable insights into the development of challenging baselines that serve as a reference for future, more intricate approaches, including those that leverage Large Language Models (LLMs).
xPQA: Cross-Lingual Product Question Answering across 12 Languages
May 16, 2023Product Question Answering (PQA) systems are key in e-commerce applications to provide responses to customers' questions as they shop for products. While existing work on PQA focuses mainly on English, in practice there is need to support multiple customer languages while leveraging product information available in English. To study this practical industrial task, we present xPQA, a large-scale annotated cross-lingual PQA dataset in 12 languages across 9 branches, and report results in (1) candidate ranking, to select the best English candidate containing the information to answer a non-English question; and (2) answer generation, to generate a natural-sounding non-English answer based on the selected English candidate. We evaluate various approaches involving machine translation at runtime or offline, leveraging multilingual pre-trained LMs, and including or excluding xPQA training data. We find that (1) In-domain data is essential as cross-lingual rankers trained on other domains perform poorly on the PQA task; (2) Candidate ranking often prefers runtime-translation approaches while answer generation prefers multilingual approaches; (3) Translating offline to augment multilingual models helps candidate ranking mainly on languages with non-Latin scripts; and helps answer generation mainly on languages with Latin scripts. Still, there remains a significant performance gap between the English and the cross-lingual test sets.
Low-Resource Dense Retrieval for Open-Domain Question Answering: A Comprehensive Survey
Aug 05, 2022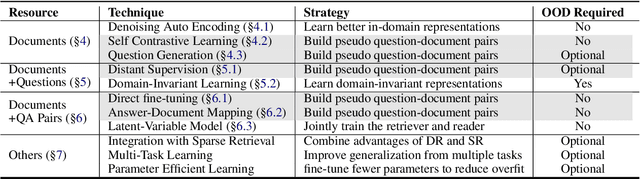
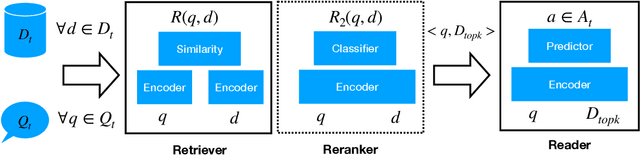
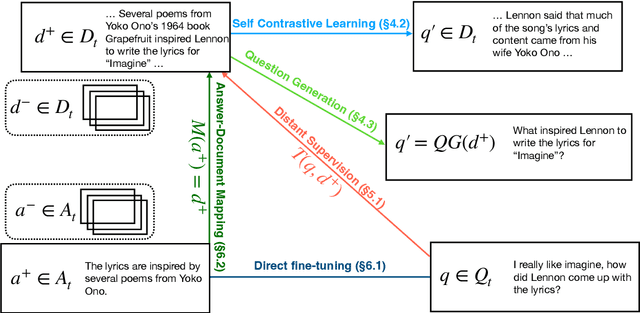

Dense retrieval (DR) approaches based on powerful pre-trained language models (PLMs) achieved significant advances and have become a key component for modern open-domain question-answering systems. However, they require large amounts of manual annotations to perform competitively, which is infeasible to scale. To address this, a growing body of research works have recently focused on improving DR performance under low-resource scenarios. These works differ in what resources they require for training and employ a diverse set of techniques. Understanding such differences is crucial for choosing the right technique under a specific low-resource scenario. To facilitate this understanding, we provide a thorough structured overview of mainstream techniques for low-resource DR. Based on their required resources, we divide the techniques into three main categories: (1) only documents are needed; (2) documents and questions are needed; and (3) documents and question-answer pairs are needed. For every technique, we introduce its general-form algorithm, highlight the open issues and pros and cons. Promising directions are outlined for future research.
From Rewriting to Remembering: Common Ground for Conversational QA Models
Apr 08, 2022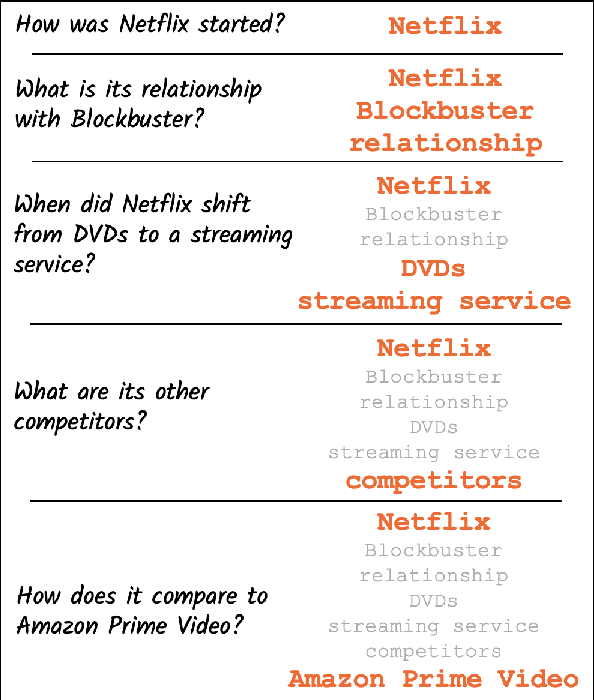
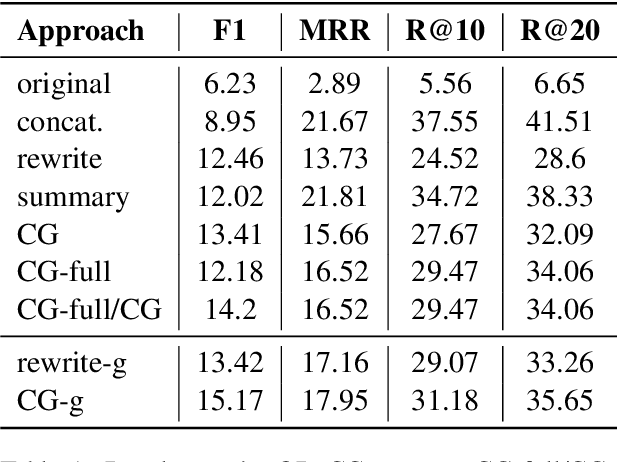


In conversational QA, models have to leverage information in previous turns to answer upcoming questions. Current approaches, such as Question Rewriting, struggle to extract relevant information as the conversation unwinds. We introduce the Common Ground (CG), an approach to accumulate conversational information as it emerges and select the relevant information at every turn. We show that CG offers a more efficient and human-like way to exploit conversational information compared to existing approaches, leading to improvements on Open Domain Conversational QA.
Neural Machine Translation by Minimising the Bayes-risk with Respect to Syntactic Translation Lattices
Feb 13, 2017


We present a novel scheme to combine neural machine translation (NMT) with traditional statistical machine translation (SMT). Our approach borrows ideas from linearised lattice minimum Bayes-risk decoding for SMT. The NMT score is combined with the Bayes-risk of the translation according the SMT lattice. This makes our approach much more flexible than $n$-best list or lattice rescoring as the neural decoder is not restricted to the SMT search space. We show an efficient and simple way to integrate risk estimation into the NMT decoder which is suitable for word-level as well as subword-unit-level NMT. We test our method on English-German and Japanese-English and report significant gains over lattice rescoring on several data sets for both single and ensembled NMT. The MBR decoder produces entirely new hypotheses far beyond simply rescoring the SMT search space or fixing UNKs in the NMT output.
Speed-Constrained Tuning for Statistical Machine Translation Using Bayesian Optimization
Apr 18, 2016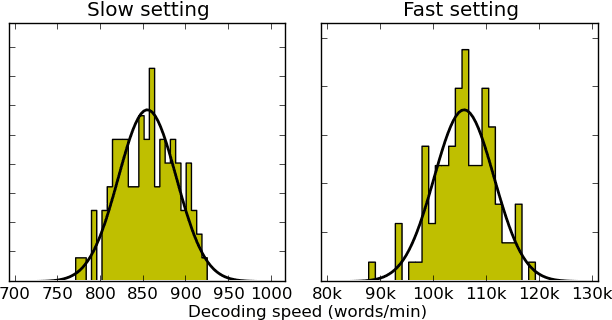
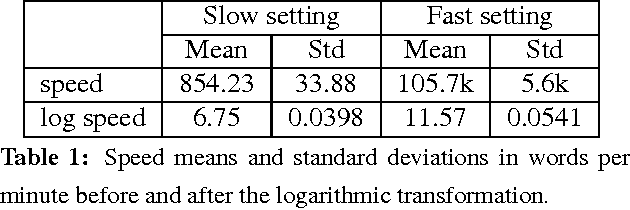
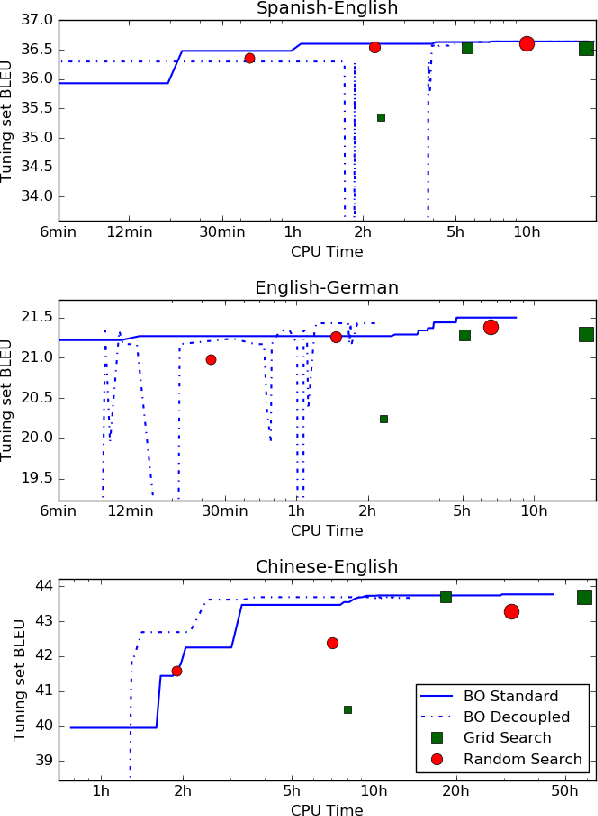
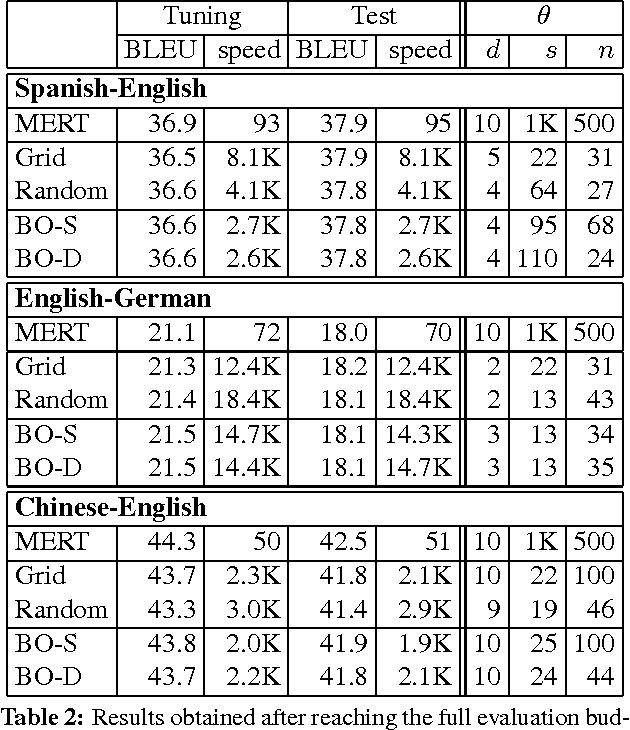
We address the problem of automatically finding the parameters of a statistical machine translation system that maximize BLEU scores while ensuring that decoding speed exceeds a minimum value. We propose the use of Bayesian Optimization to efficiently tune the speed-related decoding parameters by easily incorporating speed as a noisy constraint function. The obtained parameter values are guaranteed to satisfy the speed constraint with an associated confidence margin. Across three language pairs and two speed constraint values, we report overall optimization time reduction compared to grid and random search. We also show that Bayesian Optimization can decouple speed and BLEU measurements, resulting in a further reduction of overall optimization time as speed is measured over a small subset of sentences.