 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Dense Retrieval for Open-Domain Question Answering: A Comprehensive Survey
Paper and Code
Aug 05, 2022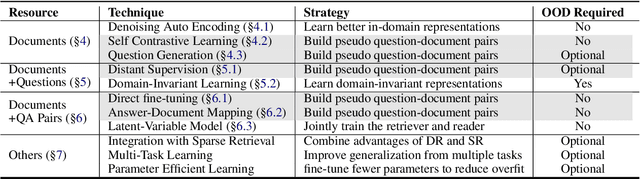
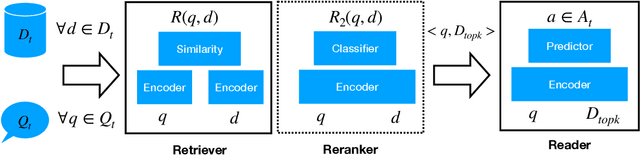
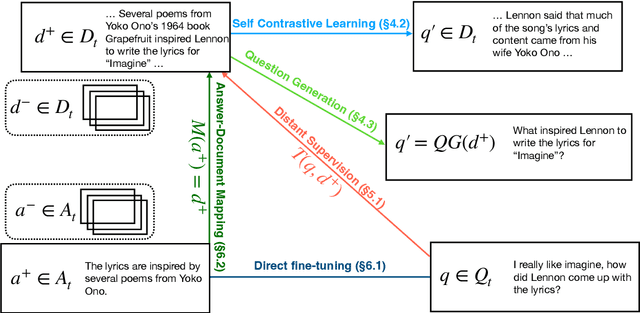

Dense retrieval (DR) approaches based on powerful pre-trained language models (PLMs) achieved significant advances and have become a key component for modern open-domain question-answering systems. However, they require large amounts of manual annotations to perform competitively, which is infeasible to scale. To address this, a growing body of research works have recently focused on improving DR performance under low-resource scenarios. These works differ in what resources they require for training and employ a diverse set of techniques. Understanding such differences is crucial for choosing the right technique under a specific low-resource scenario. To facilitate this understanding, we provide a thorough structured overview of mainstream techniques for low-resource DR. Based on their required resources, we divide the techniques into three main categories: (1) only documents are needed; (2) documents and questions are needed; and (3) documents and question-answer pairs are needed. For every technique, we introduce its general-form algorithm, highlight the open issues and pros and cons. Promising directions are outlined for future research.