 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Compact Phrasal Rewrites with Large Language Models for ASR Post Editing
Jan 23, 2025



Large Language Models (LLMs) excel at rewriting tasks such as text style transfer and grammatical error correction. While there is considerable overlap between the inputs and outputs in these tasks, the decoding cost still increases with output length, regardless of the amount of overlap. By leveraging the overlap between the input and the output, Kaneko and Okazaki (2023) proposed model-agnostic edit span representations to compress the rewrites to save computation. They reported an output length reduction rate of nearly 80% with minimal accuracy impact in four rewriting tasks. In this paper, we propose alternative edit phrase representations inspired by phrase-based statistical machine translation. We systematically compare our phrasal representations with their span representations. We apply the LLM rewriting model to the task of Automatic Speech Recognition (ASR) post editing and show that our target-phrase-only edit representation has the best efficiency-accuracy trade-off. On the LibriSpeech test set, our method closes 50-60% of the WER gap between the edit span model and the full rewrite model while losing only 10-20% of the length reduction rate of the edit span model.
Dynamic Subset Tuning: Expanding the Operational Range of Parameter-Efficient Training for Large Language Models
Nov 13, 2024



We propose a novel parameter-efficient training (PET) method for large language models that adapts models to downstream tasks by optimizing a small subset of the existing model parameters. Unlike prior methods, this subset is not fixed in location but rather which parameters are modified evolves over the course of training. This dynamic parameter selection can yield good performance with many fewer parameters than extant methods. Our method enables a seamless scaling of the subset size across an arbitrary proportion of the total model size, while popular PET approaches like prompt tuning and LoRA cover only a small part of this spectrum. We match or outperform prompt tuning and LoRA in most cases on a variety of NLP tasks (MT, QA, GSM8K, SuperGLUE) for a given parameter budget across different model families and sizes.
Long-Form Speech Translation through Segmentation with Finite-State Decoding Constraints on Large Language Models
Oct 23, 2023



One challenge in speech translation is that plenty of spoken content is long-form, but short units are necessary for obtaining high-quality translations. To address this mismatch, we adapt large language models (LLMs) to split long ASR transcripts into segments that can be independently translated so as to maximize the overall translation quality. We overcome the tendency of hallucination in LLMs by incorporating finite-state constraints during decoding; these eliminate invalid outputs without requiring additional training. We discover that LLMs are adaptable to transcripts containing ASR errors through prompt-tuning or fine-tuning. Relative to a state-of-the-art automatic punctuation baseline, our best LLM improves the average BLEU by 2.9 points for English-German, English-Spanish, and English-Arabic TED talk translation in 9 test sets, just by improving segmentation.
Towards an On-device Agent for Text Rewriting
Aug 22, 2023



Large Language Models (LLMs) have demonstrated impressive capabilities for text rewriting. Nonetheless, the large sizes of these models make them impractical for on-device inference, which would otherwise allow for enhanced privacy and economical inference. Creating a smaller yet potent language model for text rewriting presents a formidable challenge because it requires balancing the need for a small size with the need to retain the emergent capabilities of the LLM, that requires costly data collection. To address the above challenge, we introduce a new instruction tuning approach for building a mobile-centric text rewriting model. Our strategies enable the generation of high quality training data without any human labeling. In addition, we propose a heuristic reinforcement learning framework which substantially enhances performance without requiring preference data. To further bridge the performance gap with the larger server-side model, we propose an effective approach that combines the mobile rewrite agent with the server model using a cascade. To tailor the text rewriting tasks to mobile scenarios, we introduce MessageRewriteEval, a benchmark that focuses on text rewriting for messages through natural language instructions. Through empirical experiments, we demonstrate that our on-device model surpasses the current state-of-the-art LLMs in text rewriting while maintaining a significantly reduced model size. Notably, we show that our proposed cascading approach improves model performance.
Improved Long-Form Spoken Language Translation with Large Language Models
Dec 19, 2022



A challenge in spoken language translation is that plenty of spoken content is long-form, but short units are necessary for obtaining high-quality translations. To address this mismatch, we fine-tune a general-purpose, large language model to split long ASR transcripts into segments that can be independently translated so as to maximize the overall translation quality. We compare to several segmentation strategies and find that our approach improves BLEU score on three languages by an average of 2.7 BLEU overall compared to an automatic punctuation baseline. Further, we demonstrate the effectiveness of two constrained decoding strategies to improve well-formedness of the model output from above 99% to 100%.
Conciseness: An Overlooked Language Task
Nov 08, 2022



We report on novel investigations into training models that make sentences concise. We define the task and show that it is different from related tasks such as summarization and simplification. For evaluation, we release two test sets, consisting of 2000 sentences each, that were annotated by two and five human annotators, respectively. We demonstrate that conciseness is a difficult task for which zero-shot setups with large neural language models often do not perform well. Given the limitations of these approaches, we propose a synthetic data generation method based on round-trip translations. Using this data to either train Transformers from scratch or fine-tune T5 models yields our strongest baselines that can be further improved by fine-tuning on an artificial conciseness dataset that we derived from multi-annotator machine translation test sets.
Text Generation with Text-Editing Models
Jun 14, 2022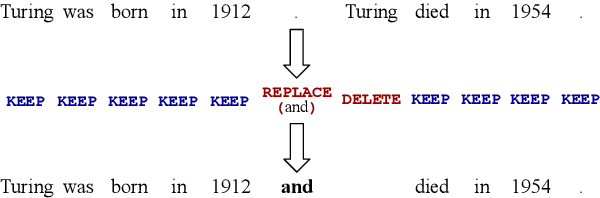

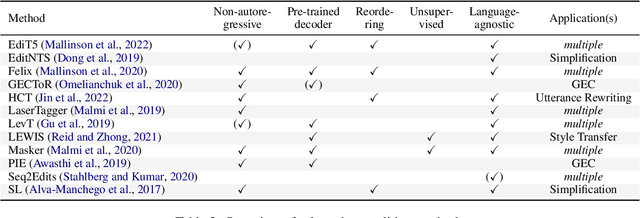
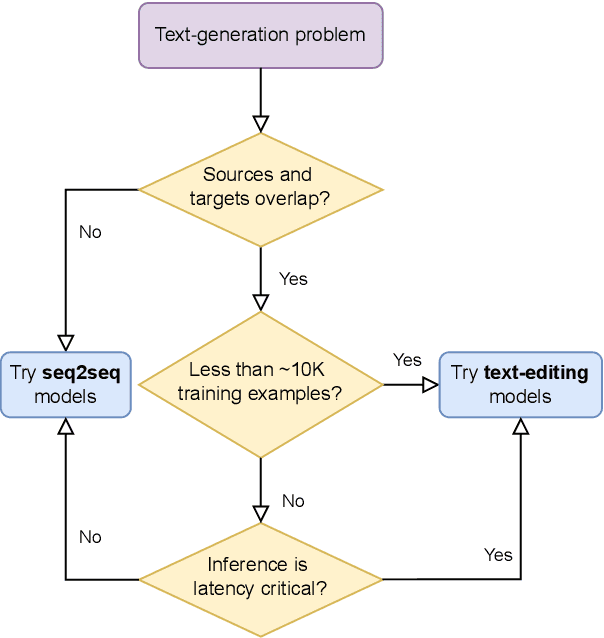
Text-editing models have recently become a prominent alternative to seq2seq models for monolingual text-generation tasks such as grammatical error correction, simplification, and style transfer. These tasks share a common trait - they exhibit a large amount of textual overlap between the source and target texts. Text-editing models take advantage of this observation and learn to generate the output by predicting edit operations applied to the source sequence. In contrast, seq2seq models generate outputs word-by-word from scratch thus making them slow at inference time. Text-editing models provide several benefits over seq2seq models including faster inference speed, higher sample efficiency, and better control and interpretability of the outputs. This tutorial provides a comprehensive overview of text-editing models and current state-of-the-art approaches, and analyzes their pros and cons. We discuss challenges related to productionization and how these models can be used to mitigate hallucination and bias, both pressing challenges in the field of text generation.
Jam or Cream First? Modeling Ambiguity in Neural Machine Translation with SCONES
May 02, 2022
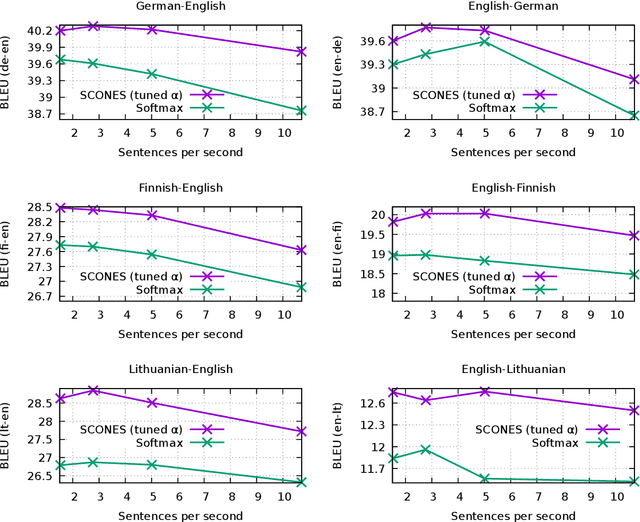
The softmax layer in neural machine translation is designed to model the distribution over mutually exclusive tokens. Machine translation, however, is intrinsically uncertain: the same source sentence can have multiple semantically equivalent translations. Therefore, we propose to replace the softmax activation with a multi-label classification layer that can model ambiguity more effectively. We call our loss function Single-label Contrastive Objective for Non-Exclusive Sequences (SCONES). We show that the multi-label output layer can still be trained on single reference training data using the SCONES loss function. SCONES yields consistent BLEU score gains across six translation directions, particularly for medium-resource language pairs and small beam sizes. By using smaller beam sizes we can speed up inference by a factor of 3.9x and still match or improve the BLEU score obtained using softmax. Furthermore, we demonstrate that SCONES can be used to train NMT models that assign the highest probability to adequate translations, thus mitigating the "beam search curse". Additional experiments on synthetic language pairs with varying levels of uncertainty suggest that the improvements from SCONES can be attributed to better handling of ambiguity.
Uncertainty Determines the Adequacy of the Mode and the Tractability of Decoding in Sequence-to-Sequence Models
Apr 01, 2022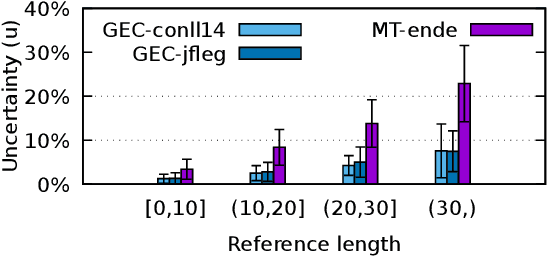


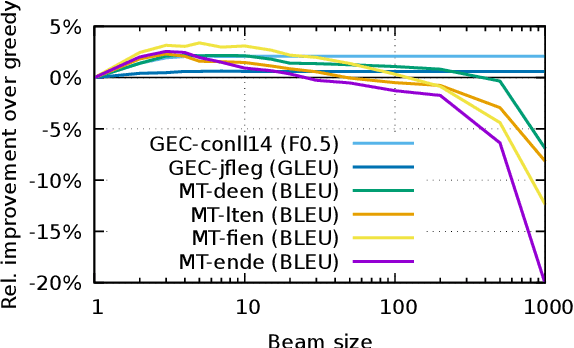
In many natural language processing (NLP) tasks the same input (e.g. source sentence) can have multiple possible outputs (e.g. translations). To analyze how this ambiguity (also known as intrinsic uncertainty) shapes the distribution learned by neural sequence models we measure sentence-level uncertainty by computing the degree of overlap between references in multi-reference test sets from two different NLP tasks: machine translation (MT) and grammatical error correction (GEC). At both the sentence- and the task-level, intrinsic uncertainty has major implications for various aspects of search such as the inductive biases in beam search and the complexity of exact search. In particular, we show that well-known pathologies such as a high number of beam search errors, the inadequacy of the mode, and the drop in system performance with large beam sizes apply to tasks with high level of ambiguity such as MT but not to less uncertain tasks such as GEC. Furthermore, we propose a novel exact $n$-best search algorithm for neural sequence models, and show that intrinsic uncertainty affects model uncertainty as the model tends to overly spread out the probability mass for uncertain tasks and sentences.
Transformer-based Models of Text Normalization for Speech Applications
Feb 01, 2022



Text normalization, or the process of transforming text into a consistent, canonical form, is crucial for speech applications such as text-to-speech synthesis (TTS). In TTS, the system must decide whether to verbalize "1995" as "nineteen ninety five" in "born in 1995" or as "one thousand nine hundred ninety five" in "page 1995". We present an experimental comparison of various Transformer-based sequence-to-sequence (seq2seq) models of text normalization for speech and evaluate them on a variety of datasets of written text aligned to its normalized spoken form. These models include variants of the 2-stage RNN-based tagging/seq2seq architecture introduced by Zhang et al. (2019), where we replace the RNN with a Transformer in one or more stages, as well as vanilla Transformers that output string representations of edit sequences. Of our approaches, using Transformers for sentence context encoding within the 2-stage model proved most effective, with the fine-tuned BERT encoder yielding the best performance.