 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
Jan 22, 2024



The success of reinforcement learning from human feedback (RLHF) in language model alignment is strongly dependent on the quality of the underlying reward model. In this paper, we present a novel approach to improve reward model quality by generating synthetic preference data, thereby augmenting the training dataset with on-policy, high-quality preference pairs. Motivated by the promising results of Best-of-N sampling strategies in language model training, we extend their application to reward model training. This results in a self-training strategy to generate preference pairs by selecting the best and worst candidates in a pool of responses to a given query. Empirically, we find that this approach improves the performance of any reward model, with an effect comparable to the addition of a similar quantity of human preference data. This work opens up new avenues of research for improving RLHF for language model alignment, by offering synthetic preference generation as a solution to reward modeling challenges.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Text Generation with Text-Editing Models
Jun 14, 2022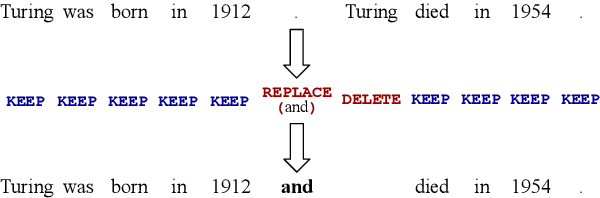

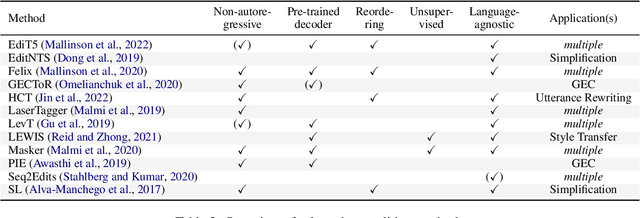
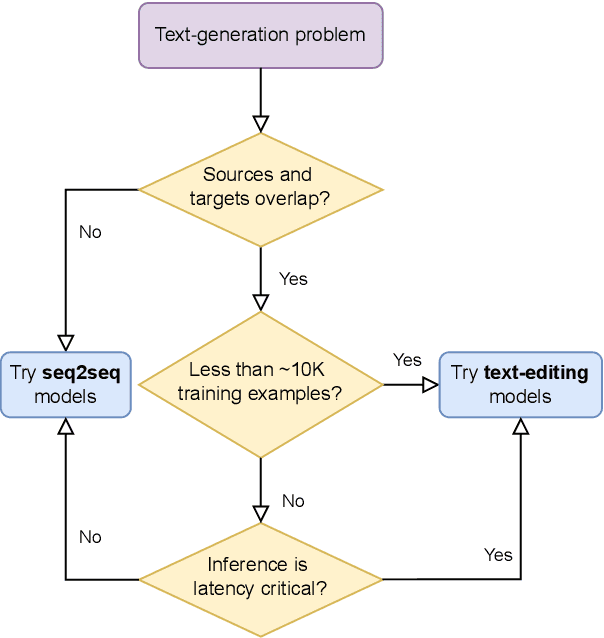
Text-editing models have recently become a prominent alternative to seq2seq models for monolingual text-generation tasks such as grammatical error correction, simplification, and style transfer. These tasks share a common trait - they exhibit a large amount of textual overlap between the source and target texts. Text-editing models take advantage of this observation and learn to generate the output by predicting edit operations applied to the source sequence. In contrast, seq2seq models generate outputs word-by-word from scratch thus making them slow at inference time. Text-editing models provide several benefits over seq2seq models including faster inference speed, higher sample efficiency, and better control and interpretability of the outputs. This tutorial provides a comprehensive overview of text-editing models and current state-of-the-art approaches, and analyzes their pros and cons. We discuss challenges related to productionization and how these models can be used to mitigate hallucination and bias, both pressing challenges in the field of text generation.
A Simple Recipe for Multilingual Grammatical Error Correction
Jun 07, 2021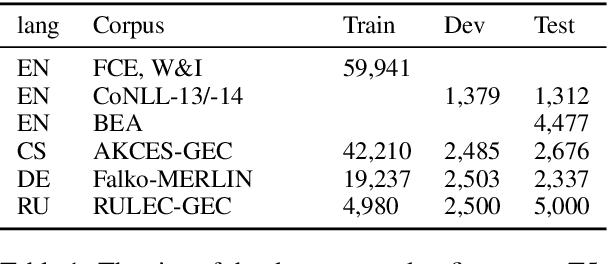

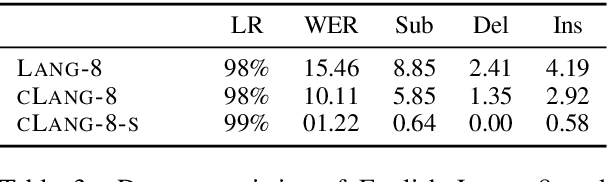

This paper presents a simple recipe to train state-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a cLang-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages -- we demonstrate that performing a single fine-tuning step on cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.
Encode, Tag, Realize: High-Precision Text Editing
Sep 03, 2019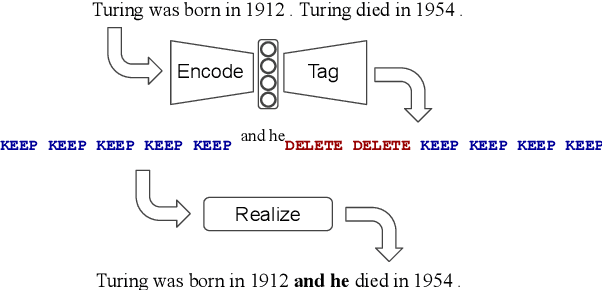

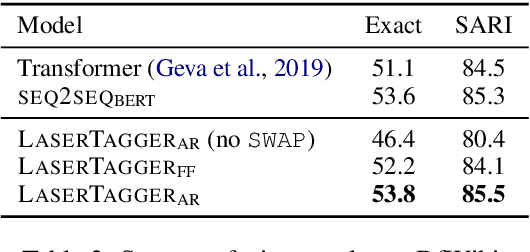
We propose LaserTagger - a sequence tagging approach that casts text generation as a text editing task. Target texts are reconstructed from the inputs using three main edit operations: keeping a token, deleting it, and adding a phrase before the token. To predict the edit operations, we propose a novel model, which combines a BERT encoder with an autoregressive Transformer decoder. This approach is evaluated on English text on four tasks: sentence fusion, sentence splitting, abstractive summarization, and grammar correction. LaserTagger achieves new state-of-the-art results on three of these tasks, performs comparably to a set of strong seq2seq baselines with a large number of training examples, and outperforms them when the number of examples is limited. Furthermore, we show that at inference time tagging can be more than two orders of magnitude faster than comparable seq2seq models, making it more attractive for running in a live environment.
Automatic Prediction of Discourse Connectives
Feb 01, 2018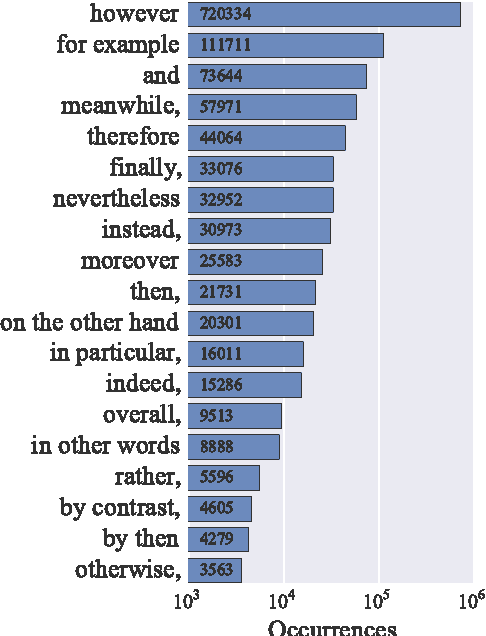

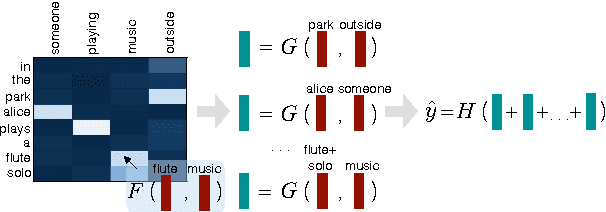
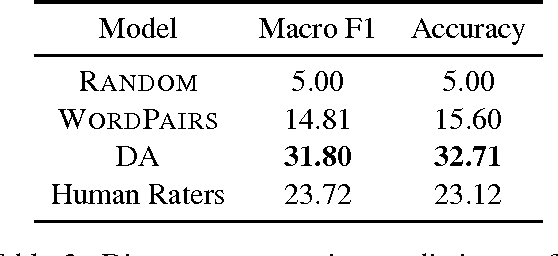
Accurate prediction of suitable discourse connectives (however, furthermore, etc.) is a key component of any system aimed at building coherent and fluent discourses from shorter sentences and passages. As an example, a dialog system might assemble a long and informative answer by sampling passages extracted from different documents retrieved from the Web. We formulate the task of discourse connective prediction and release a dataset of 2.9M sentence pairs separated by discourse connectives for this task. Then, we evaluate the hardness of the task for human raters, apply a recently proposed decomposable attention (DA) model to this task and observe that the automatic predictor has a higher F1 than human raters (32 vs. 30). Nevertheless, under specific conditions the raters still outperform the DA model, suggesting that there is headroom for future improvements.
SynsetRank: Degree-adjusted Random Walk for Relation Identification
Sep 15, 2016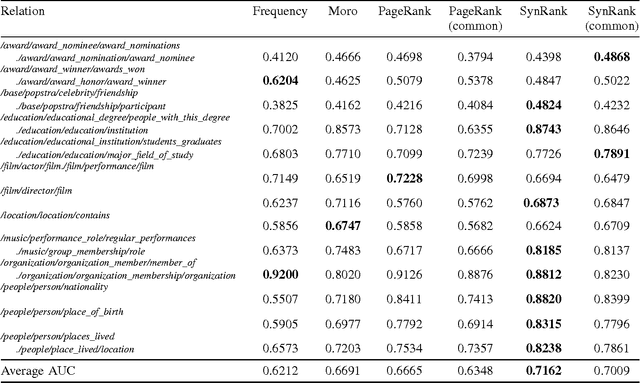

In relation extraction, a key process is to obtain good detectors that find relevant sentences describing the target relation. To minimize the necessity of labeled data for refining detectors, previous work successfully made use of BabelNet, a semantic graph structure expressing relationships between synsets, as side information or prior knowledge. The goal of this paper is to enhance the use of graph structure in the framework of random walk with a few adjustable parameters. Actually, a straightforward application of random walk degrades the performance even after parameter optimization. With the insight from this unsuccessful trial, we propose SynsetRank, which adjusts the initial probability so that high degree nodes influence the neighbors as strong as low degree nodes. In our experiment on 13 relations in the FB15K-237 dataset, SynsetRank significantly outperforms baselines and the plain random walk approach.