 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Recipe for Multilingual Grammatical Error Correction
Paper and Code
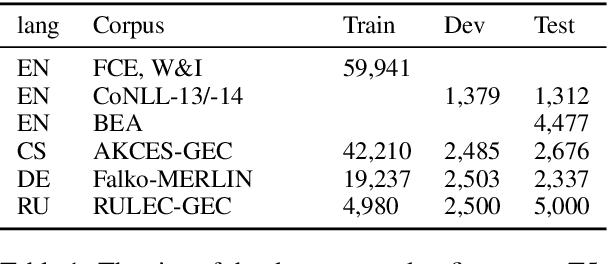

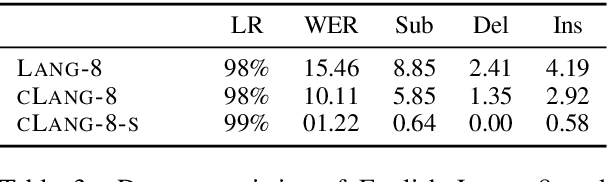

This paper presents a simple recipe to train state-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a cLang-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages -- we demonstrate that performing a single fine-tuning step on cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.