 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise Extractive Summarization and Planning with Structured Transformers
Oct 06, 2020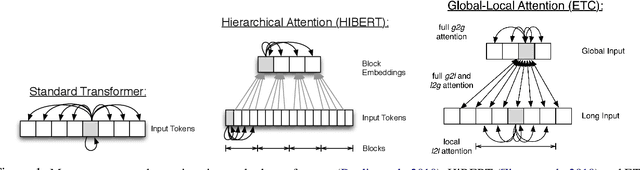
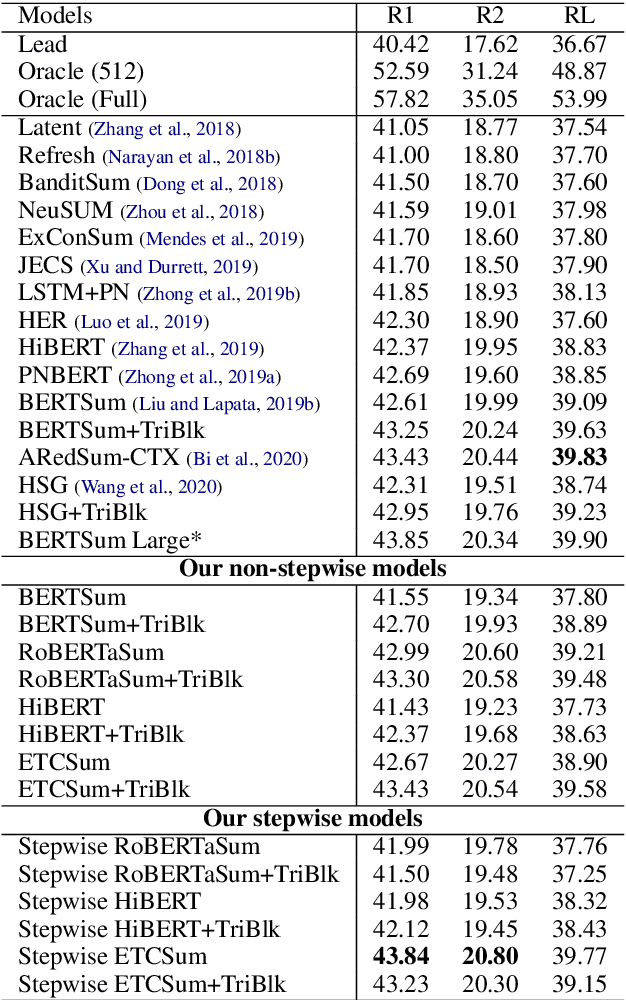

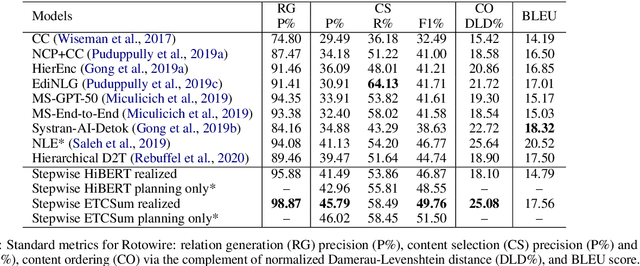
We propose encoder-centric stepwise models for extractive summarization using structured transformers -- HiBERT and Extended Transformers. We enable stepwise summarization by injecting the previously generated summary into the structured transformer as an auxiliary sub-structure. Our models are not only efficient in modeling the structure of long inputs, but they also do not rely on task-specific redundancy-aware modeling, making them a general purpose extractive content planner for different tasks. When evaluated on CNN/DailyMail extractive summarization, stepwise models achieve state-of-the-art performance in terms of Rouge without any redundancy aware modeling or sentence filtering. This also holds true for Rotowire table-to-text generation, where our models surpass previously reported metrics for content selection, planning and ordering, highlighting the strength of stepwise modeling. Amongst the two structured transformers we test, stepwise Extended Transformers provides the best performance across both datasets and sets a new standard for these challenges.
Automatic Prediction of Discourse Connectives
Feb 01, 2018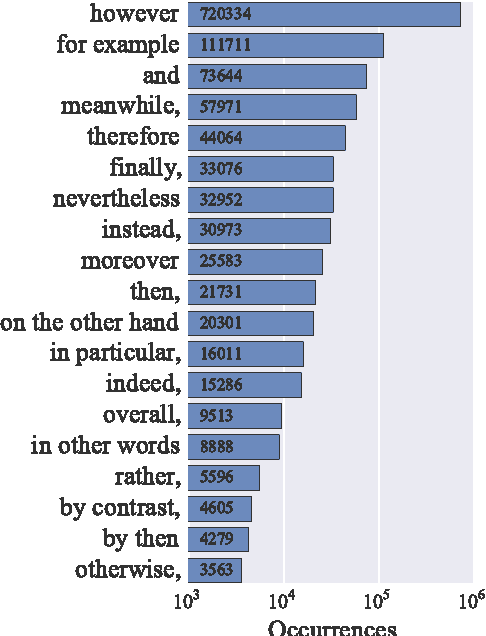

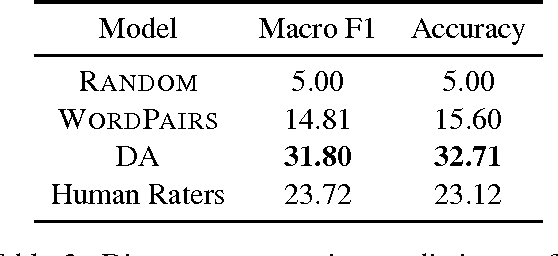
Accurate prediction of suitable discourse connectives (however, furthermore, etc.) is a key component of any system aimed at building coherent and fluent discourses from shorter sentences and passages. As an example, a dialog system might assemble a long and informative answer by sampling passages extracted from different documents retrieved from the Web. We formulate the task of discourse connective prediction and release a dataset of 2.9M sentence pairs separated by discourse connectives for this task. Then, we evaluate the hardness of the task for human raters, apply a recently proposed decomposable attention (DA) model to this task and observe that the automatic predictor has a higher F1 than human raters (32 vs. 30). Nevertheless, under specific conditions the raters still outperform the DA model, suggesting that there is headroom for future improvements.