 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Adversarial Autoencoders for Unsupervised Text Style Transfer
Oct 02, 2020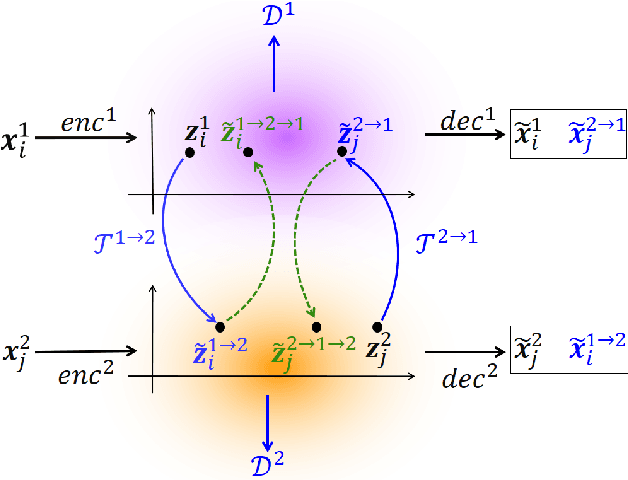

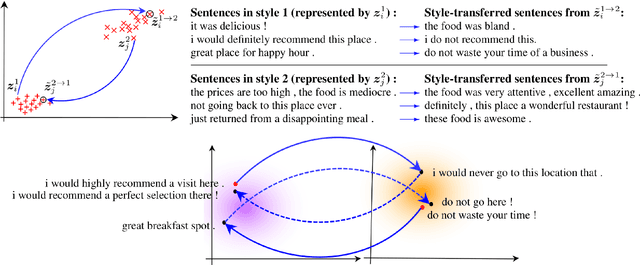
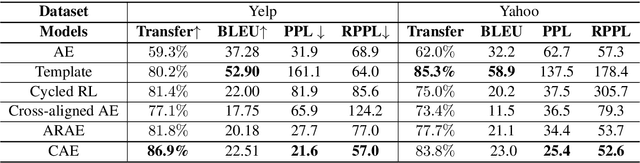
Unsupervised text style transfer is full of challenges due to the lack of parallel data and difficulties in content preservation. In this paper, we propose a novel neural approach to unsupervised text style transfer, which we refer to as Cycle-consistent Adversarial autoEncoders (CAE) trained from non-parallel data. CAE consists of three essential components: (1) LSTM autoencoders that encode a text in one style into its latent representation and decode an encoded representation into its original text or a transferred representation into a style-transferred text, (2) adversarial style transfer networks that use an adversarially trained generator to transform a latent representation in one style into a representation in another style, and (3) a cycle-consistent constraint that enhances the capacity of the adversarial style transfer networks in content preservation. The entire CAE with these three components can be trained end-to-end. Extensive experiments and in-depth analyses on two widely-used public datasets consistently validate the effectiveness of proposed CAE in both style transfer and content preservation against several strong baselines in terms of four automatic evaluation metrics and human evaluation.
Efficient Automatic Meta Optimization Search for Few-Shot Learning
Sep 06, 2019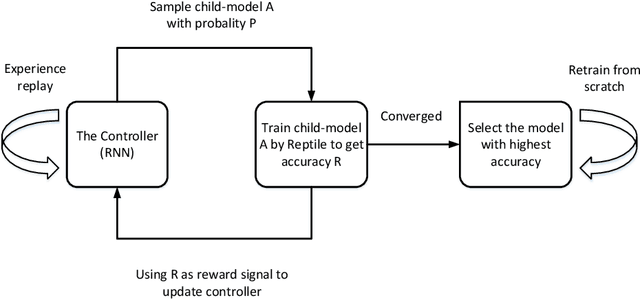
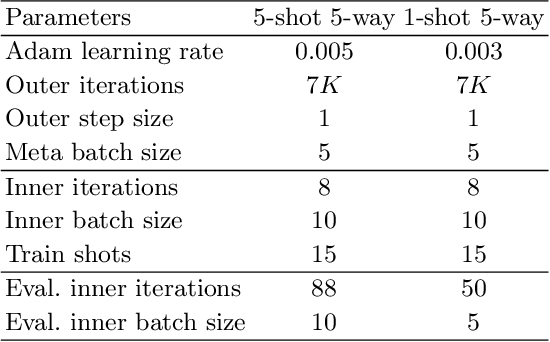
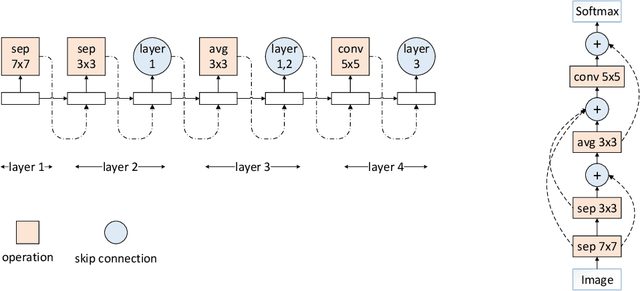
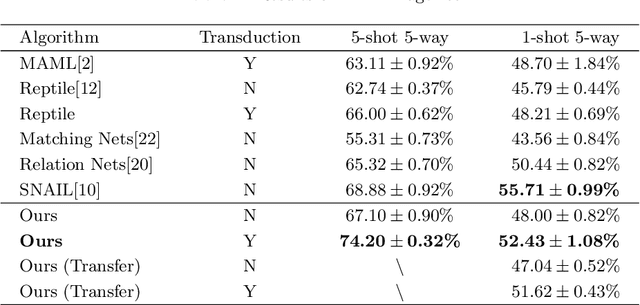
Previous works on meta-learning either relied on elaborately hand-designed network structures or adopted specialized learning rules to a particular domain. We propose a universal framework to optimize the meta-learning process automatically by adopting neural architecture search technique (NAS). NAS automatically generates and evaluates meta-learner's architecture for few-shot learning problems, while the meta-learner uses meta-learning algorithm to optimize its parameters based on the distribution of learning tasks. Parameter sharing and experience replay are adopted to accelerate the architectures searching process, so it takes only 1-2 GPU days to find good architectures. Extensive experiments on Mini-ImageNet and Omniglot show that our algorithm excels in few-shot learning tasks. The best architecture found on Mini-ImageNet achieves competitive results when transferred to Omniglot, which shows the high transferability of architectures among different computer vision problems.
Creation of an Annotated Corpus of Spanish Radiology Reports
Oct 30, 2017

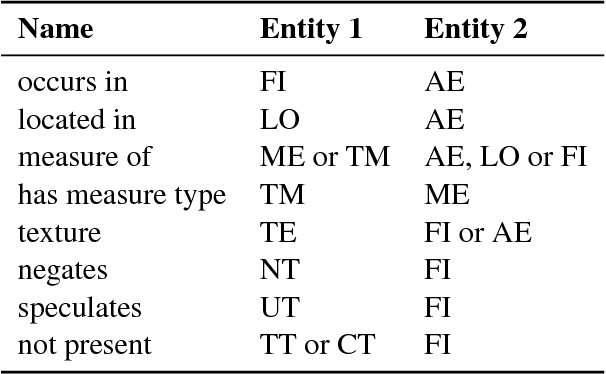

This paper presents a new annotated corpus of 513 anonymized radiology reports written in Spanish. Reports were manually annotated with entities, negation and uncertainty terms and relations. The corpus was conceived as an evaluation resource for named entity recognition and relation extraction algorithms, and as input for the use of supervised methods. Biomedical annotated resources are scarce due to confidentiality issues and associated costs. This work provides some guidelines that could help other researchers to undertake similar tasks.
SynsetRank: Degree-adjusted Random Walk for Relation Identification
Sep 15, 2016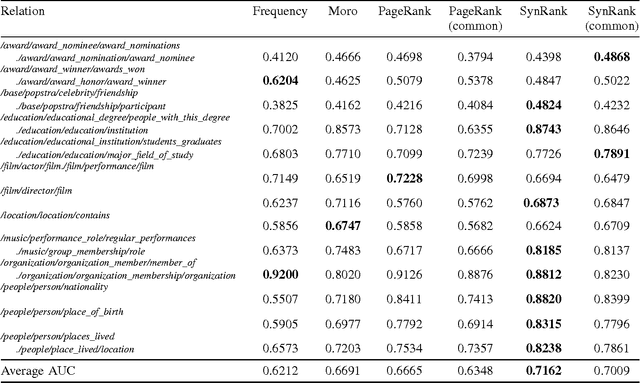

In relation extraction, a key process is to obtain good detectors that find relevant sentences describing the target relation. To minimize the necessity of labeled data for refining detectors, previous work successfully made use of BabelNet, a semantic graph structure expressing relationships between synsets, as side information or prior knowledge. The goal of this paper is to enhance the use of graph structure in the framework of random walk with a few adjustable parameters. Actually, a straightforward application of random walk degrades the performance even after parameter optimization. With the insight from this unsuccessful trial, we propose SynsetRank, which adjusts the initial probability so that high degree nodes influence the neighbors as strong as low degree nodes. In our experiment on 13 relations in the FB15K-237 dataset, SynsetRank significantly outperforms baselines and the plain random walk approach.