 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing Reasoning Gaps in Clinical Agents with Differential Reasoning Learning
Feb 10, 2026Clinical decision support requires not only correct answers but also clinically valid reasoning. We propose Differential Reasoning Learning (DRL), a framework that improves clinical agents by learning from reasoning discrepancies. From reference reasoning rationales (e.g., physician-authored clinical rationale, clinical guidelines, or outputs from more capable models) and the agent's free-form chain-of-thought (CoT), DRL extracts reasoning graphs as directed acyclic graphs (DAGs) and performs a clinically weighted graph edit distance (GED)-based discrepancy analysis. An LLM-as-a-judge aligns semantically equivalent nodes and diagnoses discrepancies between graphs. These graph-level discrepancy diagnostics are converted into natural-language instructions and stored in a Differential Reasoning Knowledge Base (DR-KB). At inference, we retrieve top-$k$ instructions via Retrieval-Augmented Generation (RAG) to augment the agent prompt and patch likely logic gaps. Evaluation on open medical question answering (QA) benchmarks and a Return Visit Admissions (RVA) prediction task from internal clinical data demonstrates gains over baselines, improving both final-answer accuracy and reasoning fidelity. Ablation studies confirm gains from infusing reference reasoning rationales and the top-$k$ retrieval strategy. Clinicians' review of the output provides further assurance of the approach. Together, results suggest that DRL supports more reliable clinical decision-making in complex reasoning scenarios and offers a practical mechanism for deployment under limited token budgets.
Machine Learning Applications Related to Suicide in Military and Veterans: A Scoping Literature Review
May 18, 2025Suicide remains one of the main preventable causes of death among active service members and veterans. Early detection and prediction are crucial in suicide prevention. Machine learning techniques have yielded promising results in this area recently. This study aims to assess and summarize current research and provides a comprehensive review regarding the application of machine learning techniques in assessing and predicting suicidal ideation, attempts, and mortality among members of military and veteran populations. A keyword search using PubMed, IEEE, ACM, and Google Scholar was conducted, and the PRISMA protocol was adopted for relevant study selection. Thirty-two articles met the inclusion criteria. These studies consistently identified risk factors relevant to mental health issues such as depression, post-traumatic stress disorder (PTSD), suicidal ideation, prior attempts, physical health problems, and demographic characteristics. Machine learning models applied in this area have demonstrated reasonable predictive accuracy. However, additional research gaps still exist. First, many studies have overlooked metrics that distinguish between false positives and negatives, such as positive predictive value and negative predictive value, which are crucial in the context of suicide prevention policies. Second, more dedicated approaches to handling survival and longitudinal data should be explored. Lastly, most studies focused on machine learning methods, with limited discussion of their connection to clinical rationales. In summary, machine learning analyses have identified a wide range of risk factors associated with suicide in military populations. The diversity and complexity of these factors also demonstrates that effective prevention strategies must be comprehensive and flexible.
Toward Improving Health Literacy in Patient Education Materials with Neural Machine Translation Models
Sep 14, 2022
Health literacy is the central focus of Healthy People 2030, the fifth iteration of the U.S. national goals and objectives. People with low health literacy usually have trouble understanding health information, following post-visit instructions, and using prescriptions, which results in worse health outcomes and serious health disparities. In this study, we propose to leverage natural language processing techniques to improve health literacy in patient education materials by automatically translating illiterate languages in a given sentence. We scraped patient education materials from four online health information websites: MedlinePlus.gov, Drugs.com, Mayoclinic.org and Reddit.com. We trained and tested the state-of-the-art neural machine translation (NMT) models on a silver standard training dataset and a gold standard testing dataset, respectively. The experimental results showed that the Bidirectional Long Short-Term Memory (BiLSTM) NMT model outperformed Bidirectional Encoder Representations from Transformers (BERT)-based NMT models. We also verified the effectiveness of NMT models in translating health illiterate languages by comparing the ratio of health illiterate language in the sentence. The proposed NMT models were able to identify the correct complicated words and simplify into layman language while at the same time the models suffer from sentence completeness, fluency, readability, and have difficulty in translating certain medical terms.
DICE: Deep Significance Clustering for Outcome-Aware Stratification
Jan 07, 2021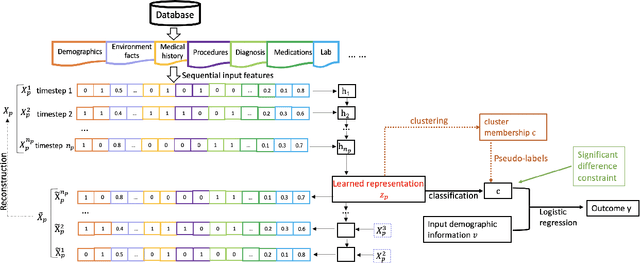
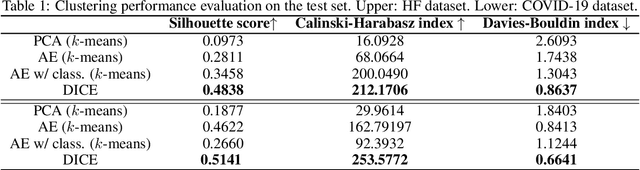
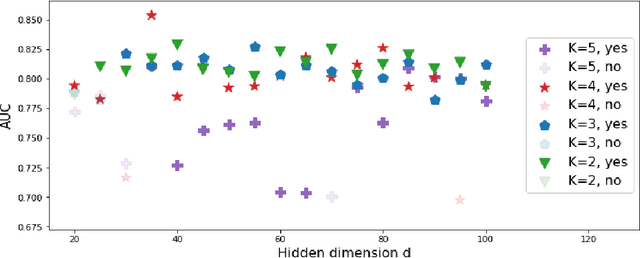
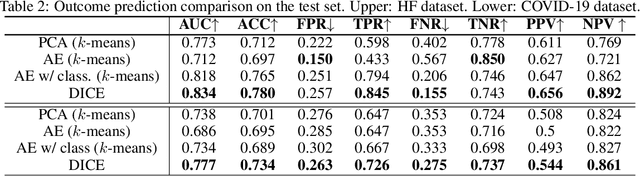
We present deep significance clustering (DICE), a framework for jointly performing representation learning and clustering for "outcome-aware" stratification. DICE is intended to generate cluster membership that may be used to categorize a population by individual risk level for a targeted outcome. Following the representation learning and clustering steps, we embed the objective function in DICE with a constraint which requires a statistically significant association between the outcome and cluster membership of learned representations. DICE further includes a neural architecture search step to maximize both the likelihood of representation learning and outcome classification accuracy with cluster membership as the predictor. To demonstrate its utility in medicine for patient risk-stratification, the performance of DICE was evaluated using two datasets with different outcome ratios extracted from real-world electronic health records. Outcomes are defined as acute kidney injury (30.4\%) among a cohort of COVID-19 patients, and discharge disposition (36.8\%) among a cohort of heart failure patients, respectively. Extensive results demonstrate that DICE has superior performance as measured by the difference in outcome distribution across clusters, Silhouette score, Calinski-Harabasz index, and Davies-Bouldin index for clustering, and Area under the ROC Curve (AUC) for outcome classification compared to several baseline approaches.
Cycle-Consistent Adversarial Autoencoders for Unsupervised Text Style Transfer
Oct 02, 2020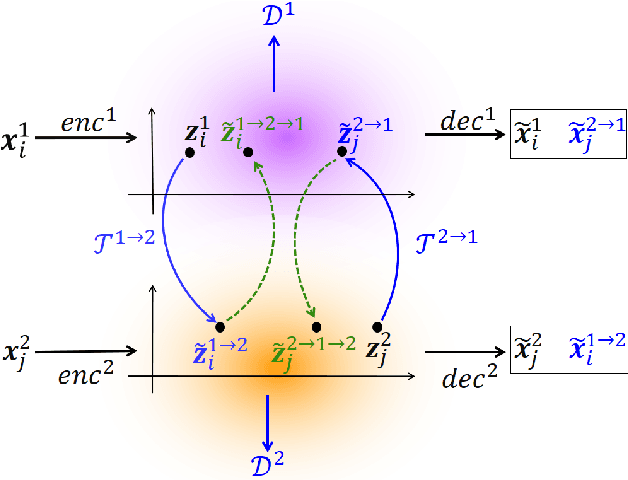

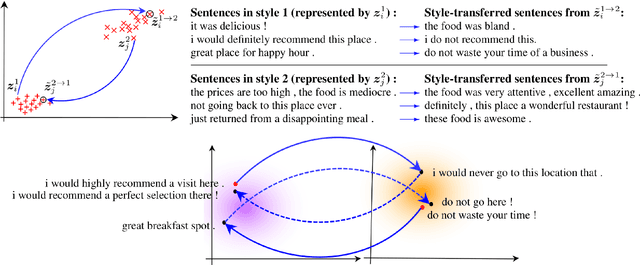
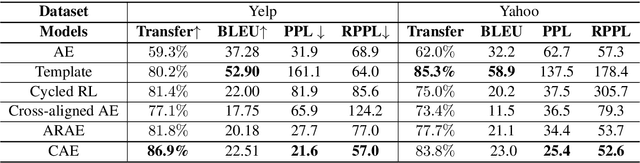
Unsupervised text style transfer is full of challenges due to the lack of parallel data and difficulties in content preservation. In this paper, we propose a novel neural approach to unsupervised text style transfer, which we refer to as Cycle-consistent Adversarial autoEncoders (CAE) trained from non-parallel data. CAE consists of three essential components: (1) LSTM autoencoders that encode a text in one style into its latent representation and decode an encoded representation into its original text or a transferred representation into a style-transferred text, (2) adversarial style transfer networks that use an adversarially trained generator to transform a latent representation in one style into a representation in another style, and (3) a cycle-consistent constraint that enhances the capacity of the adversarial style transfer networks in content preservation. The entire CAE with these three components can be trained end-to-end. Extensive experiments and in-depth analyses on two widely-used public datasets consistently validate the effectiveness of proposed CAE in both style transfer and content preservation against several strong baselines in terms of four automatic evaluation metrics and human evaluation.