 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEET: A Framework for Evaluating Embedding Techniques
Nov 02, 2024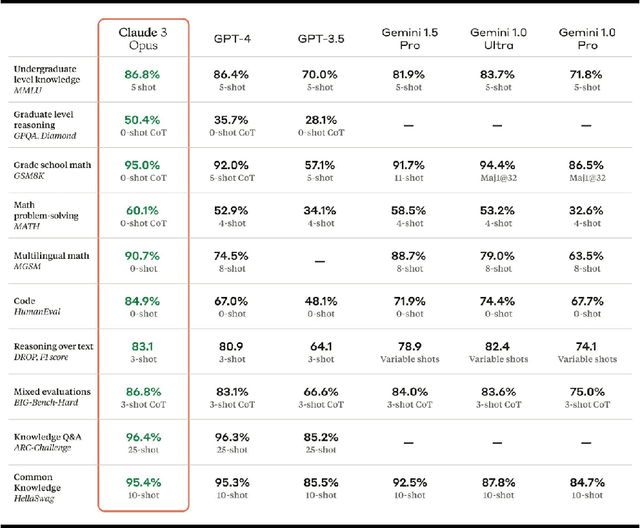
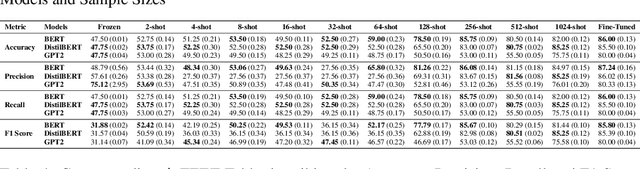
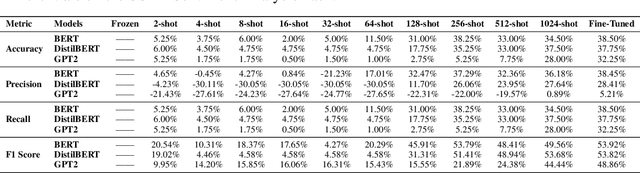
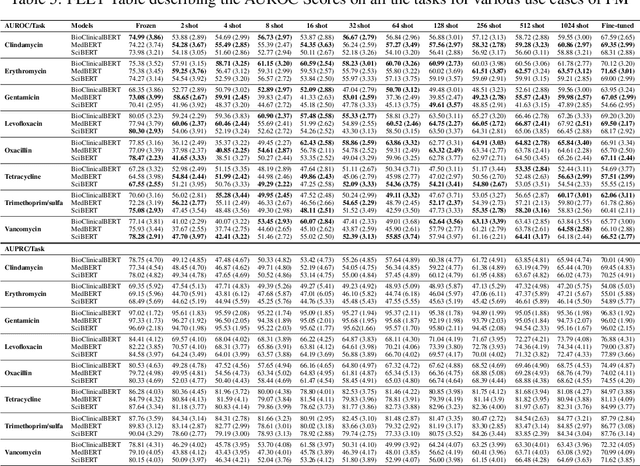
In this study, we introduce FEET, a standardized protocol designed to guide the development and benchmarking of foundation models. While numerous benchmark datasets exist for evaluating these models, we propose a structured evaluation protocol across three distinct scenarios to gain a comprehensive understanding of their practical performance. We define three primary use cases: frozen embeddings, few-shot embeddings, and fully fine-tuned embeddings. Each scenario is detailed and illustrated through two case studies: one in sentiment analysis and another in the medical domain, demonstrating how these evaluations provide a thorough assessment of foundation models' effectiveness in research applications. We recommend this protocol as a standard for future research aimed at advancing representation learning models.
Can input reconstruction be used to directly estimate uncertainty of a regression U-Net model? -- Application to proton therapy dose prediction for head and neck cancer patients
Oct 30, 2023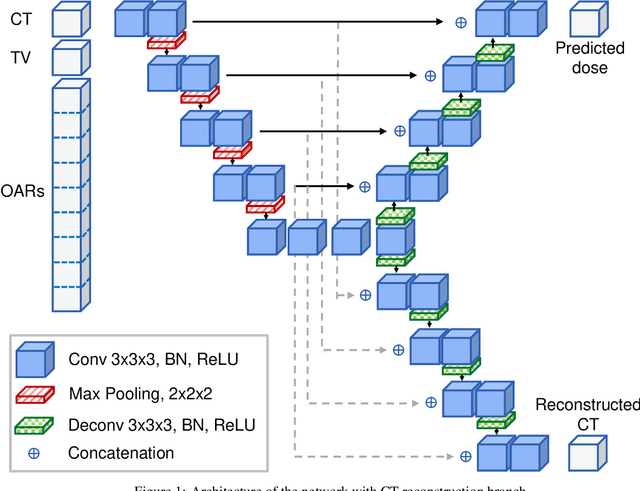


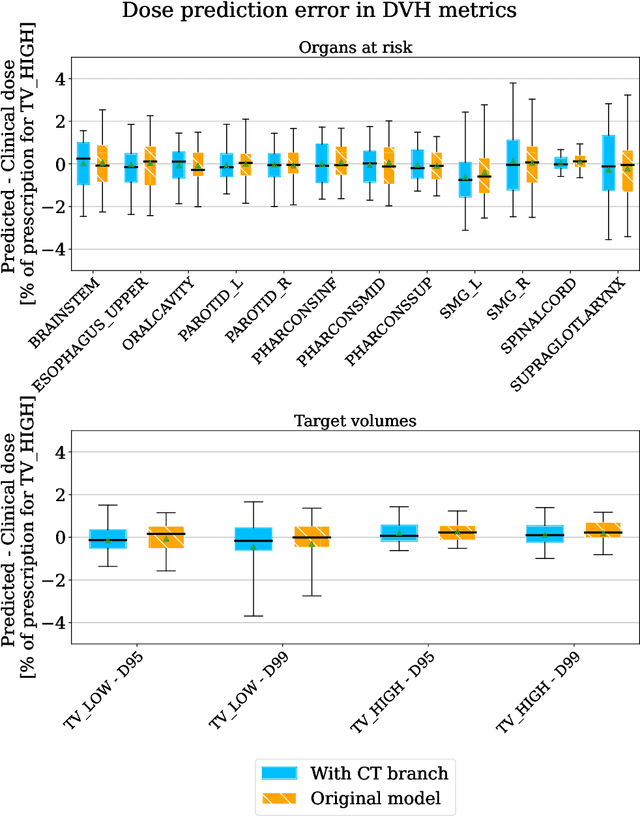
Estimating the uncertainty of deep learning models in a reliable and efficient way has remained an open problem, where many different solutions have been proposed in the literature. Most common methods are based on Bayesian approximations, like Monte Carlo dropout (MCDO) or Deep ensembling (DE), but they have a high inference time (i.e. require multiple inference passes) and might not work for out-of-distribution detection (OOD) data (i.e. similar uncertainty for in-distribution (ID) and OOD). In safety critical environments, like medical applications, accurate and fast uncertainty estimation methods, able to detect OOD data, are crucial, since wrong predictions can jeopardize patients safety. In this study, we present an alternative direct uncertainty estimation method and apply it for a regression U-Net architecture. The method consists in the addition of a branch from the bottleneck which reconstructs the input. The input reconstruction error can be used as a surrogate of the model uncertainty. For the proof-of-concept, our method is applied to proton therapy dose prediction in head and neck cancer patients. Accuracy, time-gain, and OOD detection are analyzed for our method in this particular application and compared with the popular MCDO and DE. The input reconstruction method showed a higher Pearson correlation coefficient with the prediction error (0.620) than DE and MCDO (between 0.447 and 0.612). Moreover, our method allows an easier identification of OOD (Z-score of 34.05). It estimates the uncertainty simultaneously to the regression task, therefore requires less time or computational resources.
SQuadMDS: a lean Stochastic Quartet MDS improving global structure preservation in neighbor embedding like t-SNE and UMAP
Feb 24, 2022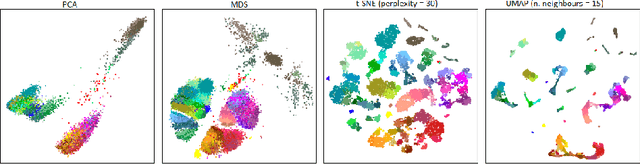
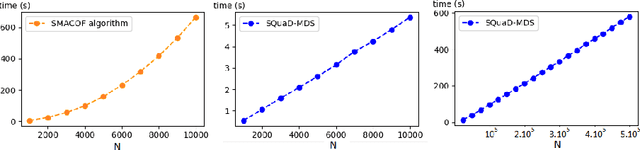
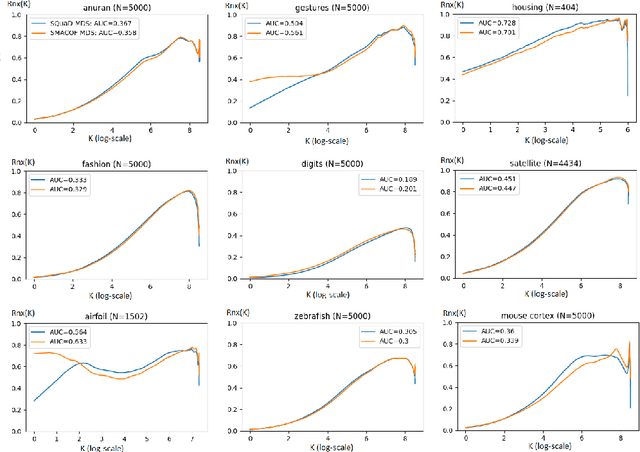
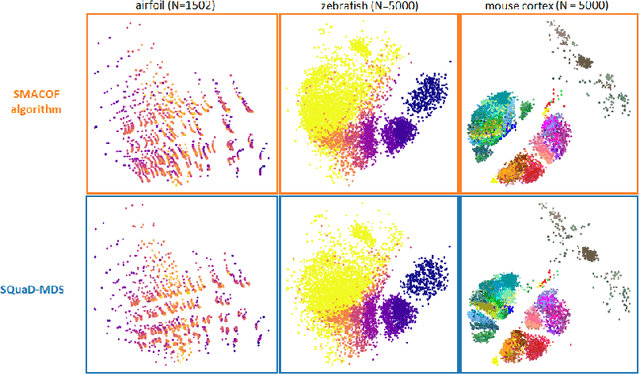
Multidimensional scaling is a statistical process that aims to embed high dimensional data into a lower-dimensional space; this process is often used for the purpose of data visualisation. Common multidimensional scaling algorithms tend to have high computational complexities, making them inapplicable on large data sets. This work introduces a stochastic, force directed approach to multidimensional scaling with a time and space complexity of O(N), with N data points. The method can be combined with force directed layouts of the family of neighbour embedding such as t-SNE, to produce embeddings that preserve both the global and the local structures of the data. Experiments assess the quality of the embeddings produced by the standalone version and its hybrid extension both quantitatively and qualitatively, showing competitive results outperforming state-of-the-art approaches. Codes are available at https://github.com/PierreLambert3/SQuaD-MDS-and-FItSNE-hybrid.
DICE: Deep Significance Clustering for Outcome-Aware Stratification
Jan 07, 2021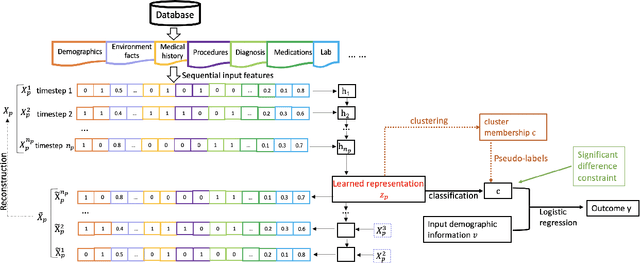
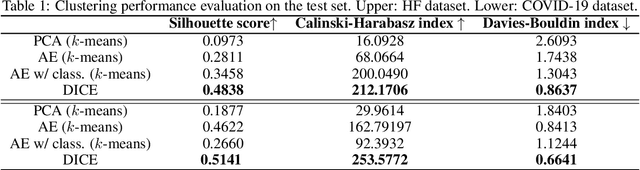
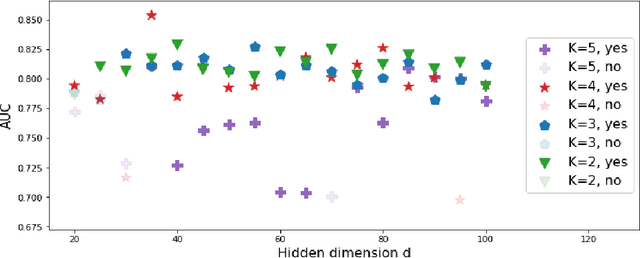
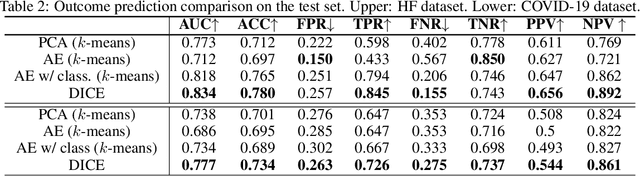
We present deep significance clustering (DICE), a framework for jointly performing representation learning and clustering for "outcome-aware" stratification. DICE is intended to generate cluster membership that may be used to categorize a population by individual risk level for a targeted outcome. Following the representation learning and clustering steps, we embed the objective function in DICE with a constraint which requires a statistically significant association between the outcome and cluster membership of learned representations. DICE further includes a neural architecture search step to maximize both the likelihood of representation learning and outcome classification accuracy with cluster membership as the predictor. To demonstrate its utility in medicine for patient risk-stratification, the performance of DICE was evaluated using two datasets with different outcome ratios extracted from real-world electronic health records. Outcomes are defined as acute kidney injury (30.4\%) among a cohort of COVID-19 patients, and discharge disposition (36.8\%) among a cohort of heart failure patients, respectively. Extensive results demonstrate that DICE has superior performance as measured by the difference in outcome distribution across clusters, Silhouette score, Calinski-Harabasz index, and Davies-Bouldin index for clustering, and Area under the ROC Curve (AUC) for outcome classification compared to several baseline approaches.
Hierarchical Optimal Transport for Multimodal Distribution Alignment
Jun 27, 2019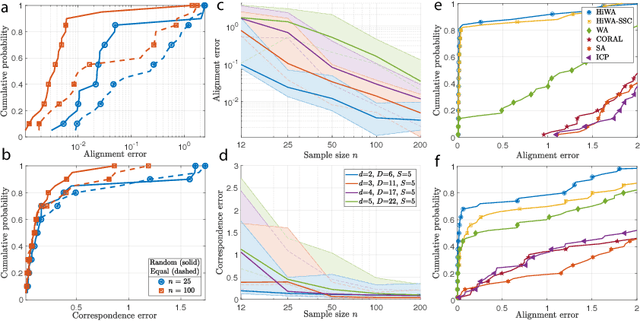
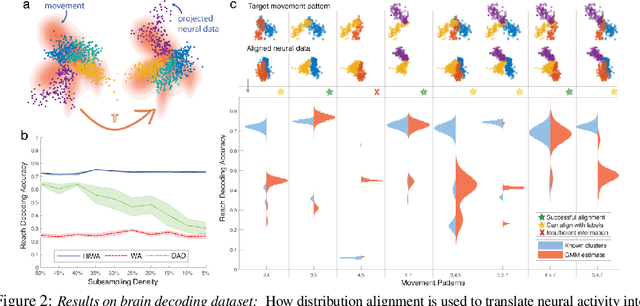
In many machine learning applications, it is necessary to meaningfully aggregate, through alignment, different but related datasets. Optimal transport (OT)-based approaches pose alignment as a divergence minimization problem: the aim is to transform a source dataset to match a target dataset using the Wasserstein distance as a divergence measure. We introduce a hierarchical formulation of OT which leverages clustered structure in data to improve alignment in noisy, ambiguous, or multimodal settings. To solve this numerically, we propose a distributed ADMM algorithm that also exploits the Sinkhorn distance, thus it has an efficient computational complexity that scales quadratically with the size of the largest cluster. When the transformation between two datasets is unitary, we provide performance guarantees that describe when and how well aligned cluster correspondences can be recovered with our formulation, as well as provide worst-case dataset geometry for such a strategy. We apply this method to synthetic datasets that model data as mixtures of low-rank Gaussians and study the impact that different geometric properties of the data have on alignment. Next, we applied our approach to a neural decoding application where the goal is to predict movement directions and instantaneous velocities from populations of neurons in the macaque primary motor cortex. Our results demonstrate that when clustered structure exists in datasets, and is consistent across trials or time points, a hierarchical alignment strategy that leverages such structure can provide significant improvements in cross-domain alignment.
Inversion using a new low-dimensional representation of complex binary geological media based on a deep neural network
Oct 25, 2017
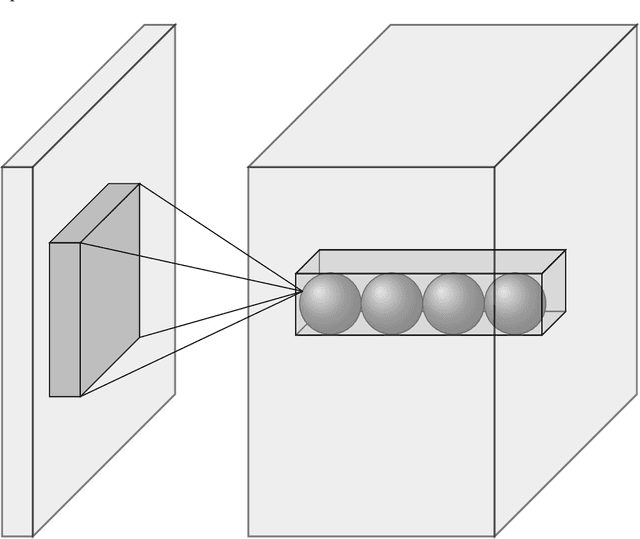

Efficient and high-fidelity prior sampling and inversion for complex geological media is still a largely unsolved challenge. Here, we use a deep neural network of the variational autoencoder type to construct a parametric low-dimensional base model parameterization of complex binary geological media. For inversion purposes, it has the attractive feature that random draws from an uncorrelated standard normal distribution yield model realizations with spatial characteristics that are in agreement with the training set. In comparison with the most commonly used parametric representations in probabilistic inversion, we find that our dimensionality reduction (DR) approach outperforms principle component analysis (PCA), optimization-PCA (OPCA) and discrete cosine transform (DCT) DR techniques for unconditional geostatistical simulation of a channelized prior model. For the considered examples, important compression ratios (200 - 500) are achieved. Given that the construction of our parameterization requires a training set of several tens of thousands of prior model realizations, our DR approach is more suited for probabilistic (or deterministic) inversion than for unconditional (or point-conditioned) geostatistical simulation. Probabilistic inversions of 2D steady-state and 3D transient hydraulic tomography data are used to demonstrate the DR-based inversion. For the 2D case study, the performance is superior compared to current state-of-the-art multiple-point statistics inversion by sequential geostatistical resampling (SGR). Inversion results for the 3D application are also encouraging.
Blue Sky Ideas in Artificial Intelligence Education from the EAAI 2017 New and Future AI Educator Program
Feb 01, 2017The 7th Symposium on Educational Advances in Artificial Intelligence (EAAI'17, co-chaired by Sven Koenig and Eric Eaton) launched the EAAI New and Future AI Educator Program to support the training of early-career university faculty, secondary school faculty, and future educators (PhD candidates or postdocs who intend a career in academia). As part of the program, awardees were asked to address one of the following "blue sky" questions: * How could/should Artificial Intelligence (AI) courses incorporate ethics into the curriculum? * How could we teach AI topics at an early undergraduate or a secondary school level? * AI has the potential for broad impact to numerous disciplines. How could we make AI education more interdisciplinary, specifically to benefit non-engineering fields? This paper is a collection of their responses, intended to help motivate discussion around these issues in AI education.