 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEET: A Framework for Evaluating Embedding Techniques
Paper and Code
Nov 02, 2024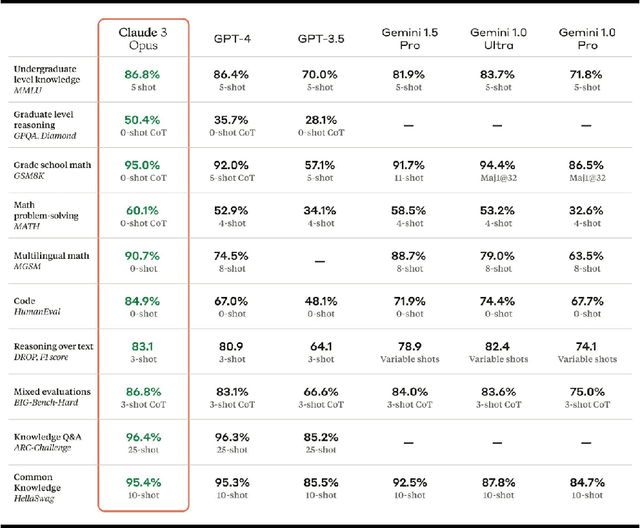
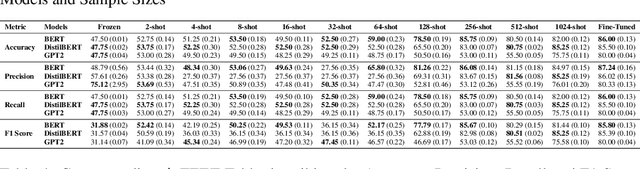
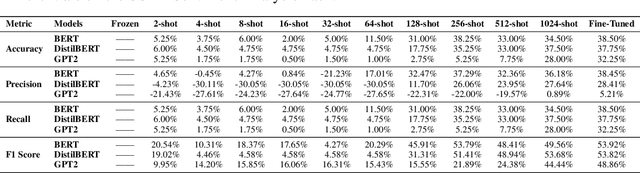
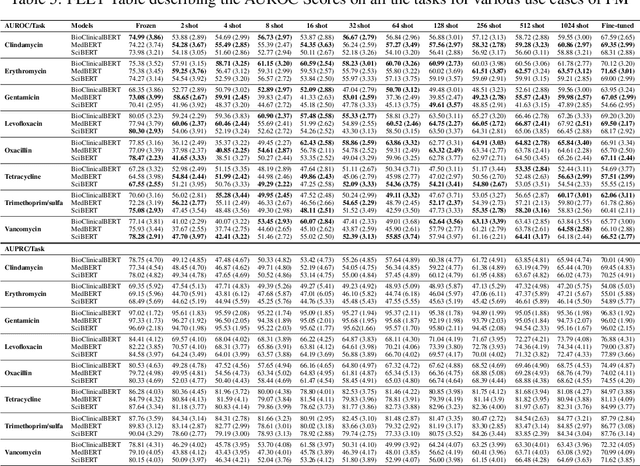
In this study, we introduce FEET, a standardized protocol designed to guide the development and benchmarking of foundation models. While numerous benchmark datasets exist for evaluating these models, we propose a structured evaluation protocol across three distinct scenarios to gain a comprehensive understanding of their practical performance. We define three primary use cases: frozen embeddings, few-shot embeddings, and fully fine-tuned embeddings. Each scenario is detailed and illustrated through two case studies: one in sentiment analysis and another in the medical domain, demonstrating how these evaluations provide a thorough assessment of foundation models' effectiveness in research applications. We recommend this protocol as a standard for future research aimed at advancing representation learning models.