 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-Paint: Faster Diffusion Inpainting Through Time Aware Pixel Conditioning
Oct 11, 2024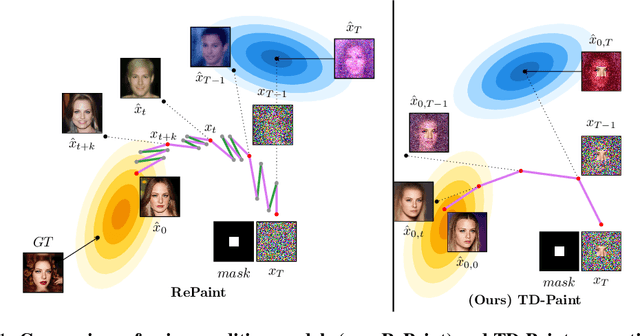



Diffusion models have emerged as highly effective techniques for inpainting, however, they remain constrained by slow sampling rates. While recent advances have enhanced generation quality, they have also increased sampling time, thereby limiting scalability in real-world applications. We investigate the generative sampling process of diffusion-based inpainting models and observe that these models make minimal use of the input condition during the initial sampling steps. As a result, the sampling trajectory deviates from the data manifold, requiring complex synchronization mechanisms to realign the generation process. To address this, we propose Time-aware Diffusion Paint (TD-Paint), a novel approach that adapts the diffusion process by modeling variable noise levels at the pixel level. This technique allows the model to efficiently use known pixel values from the start, guiding the generation process toward the target manifold. By embedding this information early in the diffusion process, TD-Paint significantly accelerates sampling without compromising image quality. Unlike conventional diffusion-based inpainting models, which require a dedicated architecture or an expensive generation loop, TD-Paint achieves faster sampling times without architectural modifications. Experimental results across three datasets show that TD-Paint outperforms state-of-the-art diffusion models while maintaining lower complexity.
Adversarial Semi-Supervised Domain Adaptation for Semantic Segmentation: A New Role for Labeled Target Samples
Dec 12, 2023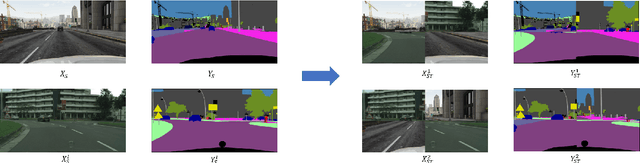
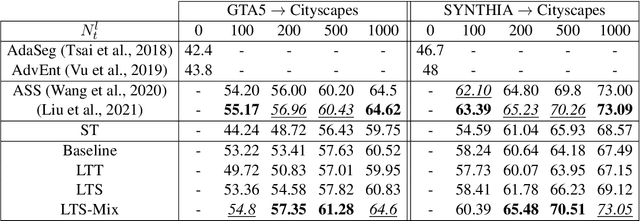
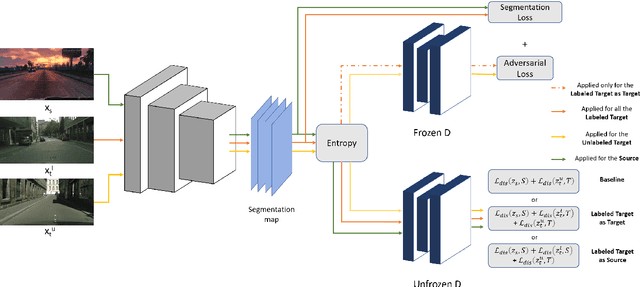
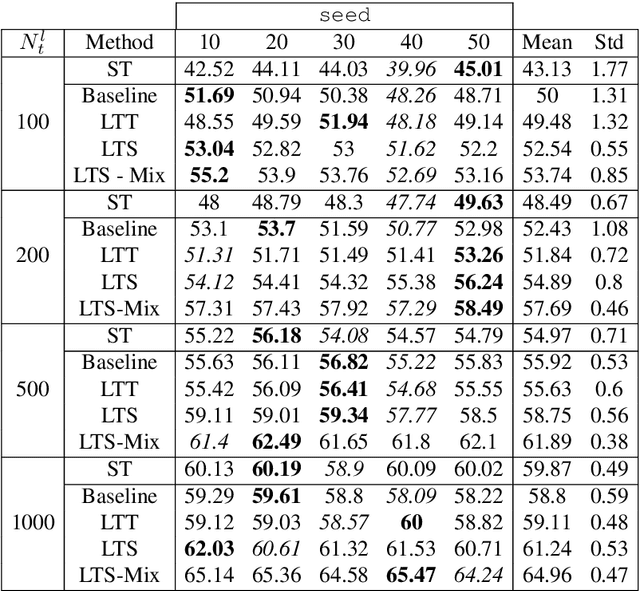
Adversarial learning baselines for domain adaptation (DA) approaches in the context of semantic segmentation are under explored in semi-supervised framework. These baselines involve solely the available labeled target samples in the supervision loss. In this work, we propose to enhance their usefulness on both semantic segmentation and the single domain classifier neural networks. We design new training objective losses for cases when labeled target data behave as source samples or as real target samples. The underlying rationale is that considering the set of labeled target samples as part of source domain helps reducing the domain discrepancy and, hence, improves the contribution of the adversarial loss. To support our approach, we consider a complementary method that mixes source and labeled target data, then applies the same adaptation process. We further propose an unsupervised selection procedure using entropy to optimize the choice of labeled target samples for adaptation. We illustrate our findings through extensive experiments on the benchmarks GTA5, SYNTHIA, and Cityscapes. The empirical evaluation highlights competitive performance of our proposed approach.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
Sep 03, 2023



We present COMEDIAN, a novel pipeline to initialize spatio-temporal transformers for action spotting, which involves self-supervised learning and knowledge distillation. Action spotting is a timestamp-level temporal action detection task. Our pipeline consists of three steps, with two initialization stages. First, we perform self-supervised initialization of a spatial transformer using short videos as input. Additionally, we initialize a temporal transformer that enhances the spatial transformer's outputs with global context through knowledge distillation from a pre-computed feature bank aligned with each short video segment. In the final step, we fine-tune the transformers to the action spotting task. The experiments, conducted on the SoccerNet-v2 dataset, demonstrate state-of-the-art performance and validate the effectiveness of COMEDIAN's pretraining paradigm. Our results highlight several advantages of our pretraining pipeline, including improved performance and faster convergence compared to non-pretrained models.
Similarity Contrastive Estimation for Image and Video Soft Contrastive Self-Supervised Learning
Dec 21, 2022Contrastive representation learning has proven to be an effective self-supervised learning method for images and videos. Most successful approaches are based on Noise Contrastive Estimation (NCE) and use different views of an instance as positives that should be contrasted with other instances, called negatives, that are considered as noise. However, several instances in a dataset are drawn from the same distribution and share underlying semantic information. A good data representation should contain relations between the instances, or semantic similarity and dissimilarity, that contrastive learning harms by considering all negatives as noise. To circumvent this issue, we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective is a soft contrastive one that brings the positives closer and estimates a continuous distribution to push or pull negative instances based on their learned similarities. We validate empirically our approach on both image and video representation learning. We show that SCE performs competitively with the state of the art on the ImageNet linear evaluation protocol for fewer pretraining epochs and that it generalizes to several downstream image tasks. We also show that SCE reaches state-of-the-art results for pretraining video representation and that the learned representation can generalize to video downstream tasks.
Physically-admissible polarimetric data augmentation for road-scene analysis
Jun 15, 2022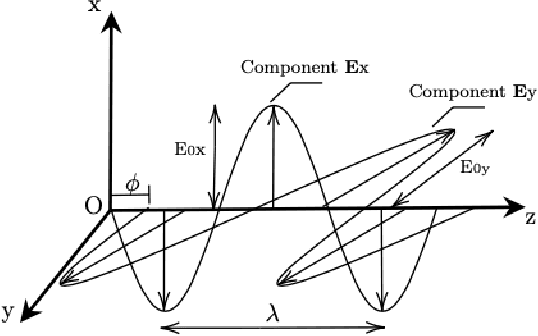
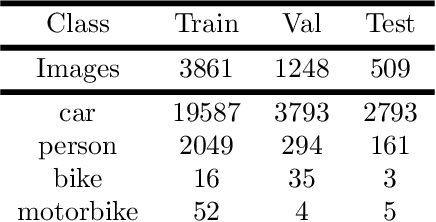
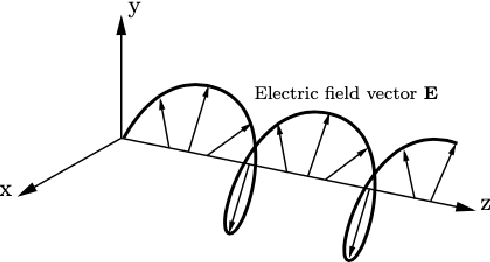
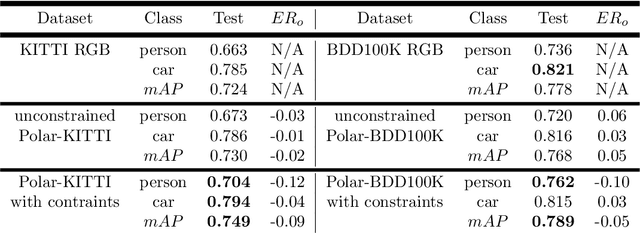
Polarimetric imaging, along with deep learning, has shown improved performances on different tasks including scene analysis. However, its robustness may be questioned because of the small size of the training datasets. Though the issue could be solved by data augmentation, polarization modalities are subject to physical feasibility constraints unaddressed by classical data augmentation techniques. To address this issue, we propose to use CycleGAN, an image translation technique based on deep generative models that solely relies on unpaired data, to transfer large labeled road scene datasets to the polarimetric domain. We design several auxiliary loss terms that, alongside the CycleGAN losses, deal with the physical constraints of polarimetric images. The efficiency of this solution is demonstrated on road scene object detection tasks where generated realistic polarimetric images allow to improve performances on cars and pedestrian detection up to 9%. The resulting constrained CycleGAN is publicly released, allowing anyone to generate their own polarimetric images.
Similarity Contrastive Estimation for Self-Supervised Soft Contrastive Learning
Nov 29, 2021



Contrastive representation learning has proven to be an effective self-supervised learning method. Most successful approaches are based on the Noise Contrastive Estimation (NCE) paradigm and consider different views of an instance as positives and other instances as noise that positives should be contrasted with. However, all instances in a dataset are drawn from the same distribution and share underlying semantic information that should not be considered as noise. We argue that a good data representation contains the relations, or semantic similarity, between the instances. Contrastive learning implicitly learns relations but considers the negatives as noise which is harmful to the quality of the learned relations and therefore the quality of the representation. To circumvent this issue we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective can be considered as soft contrastive learning. Instead of hard classifying positives and negatives, we propose a continuous distribution to push or pull instances based on their semantic similarities. The target similarity distribution is computed from weak augmented instances and sharpened to eliminate irrelevant relations. Each weak augmented instance is paired with a strong augmented instance that contrasts its positive while maintaining the target similarity distribution. Experimental results show that our proposed SCE outperforms its baselines MoCov2 and ReSSL on various datasets and is competitive with state-of-the-art algorithms on the ImageNet linear evaluation protocol.
Open Set Domain Adaptation using Optimal Transport
Oct 02, 2020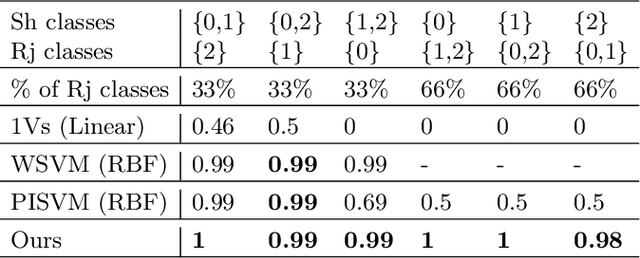
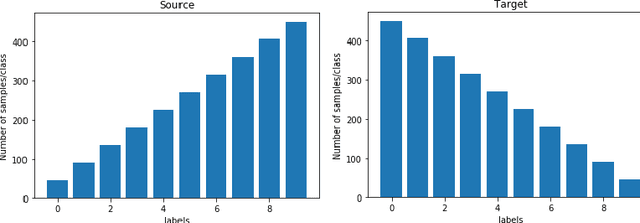
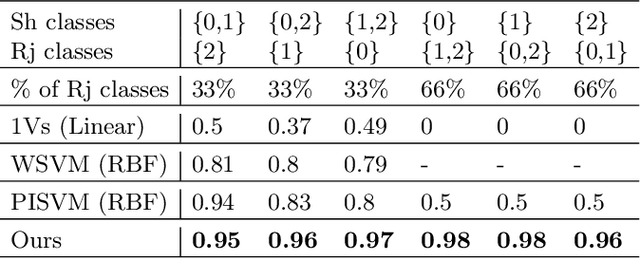
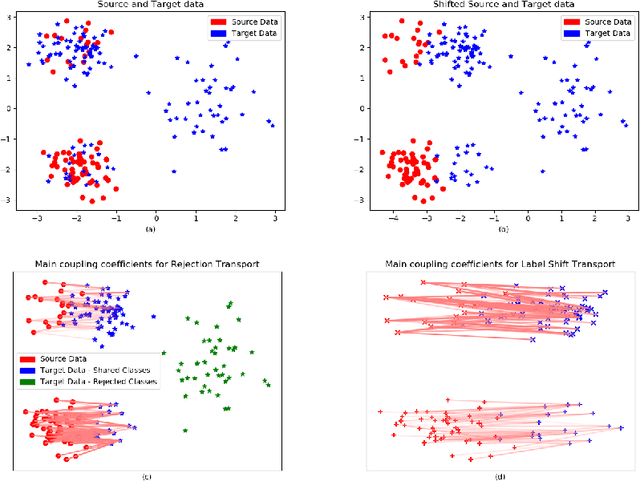
We present a 2-step optimal transport approach that performs a mapping from a source distribution to a target distribution. Here, the target has the particularity to present new classes not present in the source domain. The first step of the approach aims at rejecting the samples issued from these new classes using an optimal transport plan. The second step solves the target (class ratio) shift still as an optimal transport problem. We develop a dual approach to solve the optimization problem involved at each step and we prove that our results outperform recent state-of-the-art performances. We further apply the approach to the setting where the source and target distributions present both a label-shift and an increasing covariate (features) shift to show its robustness.
Pixel-wise Conditioned Generative Adversarial Networks for Image Synthesis and Completion
Feb 04, 2020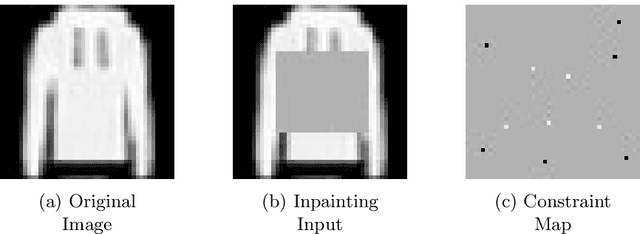
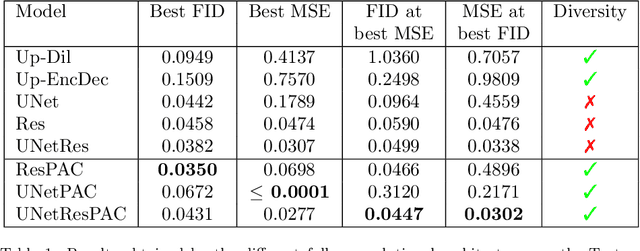
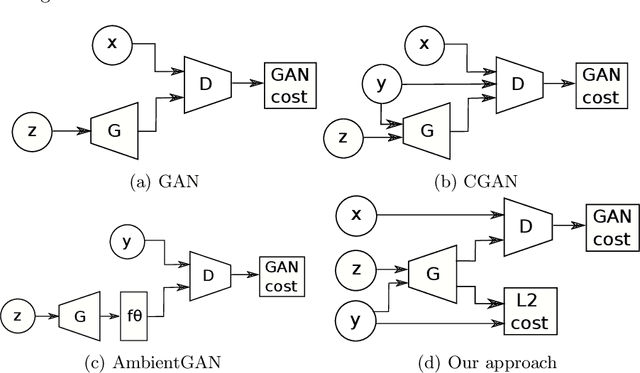
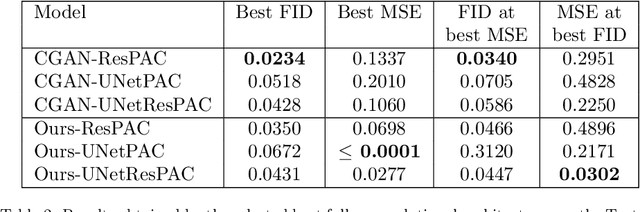
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works have extended GANs to image inpainting by conditioning the generation with parts of the image to be reconstructed. Despite their success, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper we investigate the effectiveness of conditioning GANs when very few pixel values are provided. We propose a modelling framework which results in adding an explicit cost term to the GAN objective function to enforce pixel-wise conditioning. We investigate the influence of this regularization term on the quality of the generated images and the fulfillment of the given pixel constraints. Using the recent PacGAN technique, we ensure that we keep diversity in the generated samples. Conducted experiments on FashionMNIST show that the regularization term effectively controls the trade-off between quality of the generated images and the conditioning. Experimental evaluation on the CIFAR-10 and CelebA datasets evidences that our method achieves accurate results both visually and quantitatively in term of Fr\'echet Inception Distance, while still enforcing the pixel conditioning. We also evaluate our method on a texture image generation task using fully-convolutional networks. As a final contribution, we apply the method to a classical geological simulation application.
Pixel-wise Conditioning of Generative Adversarial Networks
Nov 02, 2019
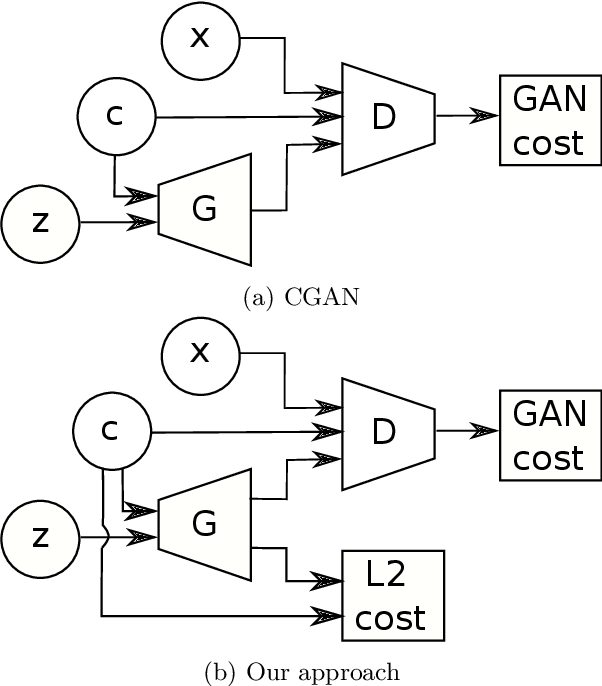
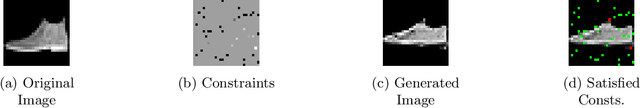
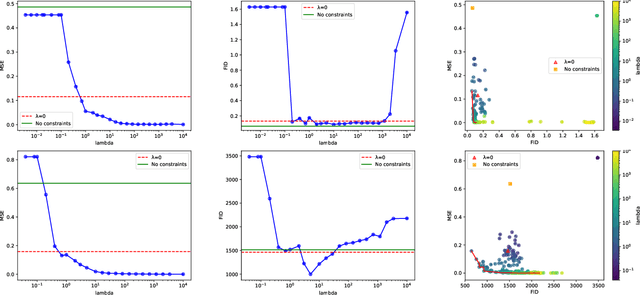
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works extended GANs to image inpainting by conditioning the generation with parts of the image one wants to reconstruct. However, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper, we study the effectiveness of conditioning GANs by adding an explicit regularization term to enforce pixel-wise conditions when very few pixel values are provided. In addition, we also investigate the influence of this regularization term on the quality of the generated images and the satisfaction of the conditions. Conducted experiments on MNIST and FashionMNIST show evidence that this regularization term allows for controlling the trade-off between quality of the generated images and constraint satisfaction.