 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-admissible polarimetric data augmentation for road-scene analysis
Jun 15, 2022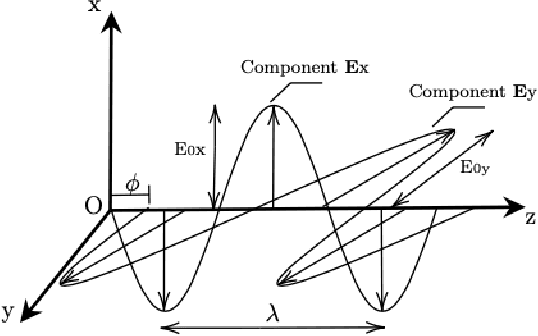
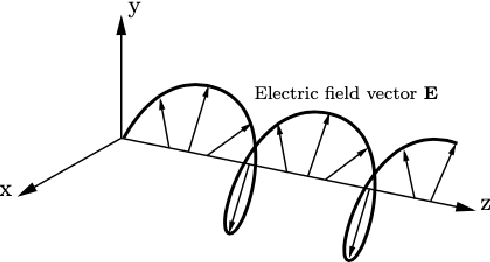
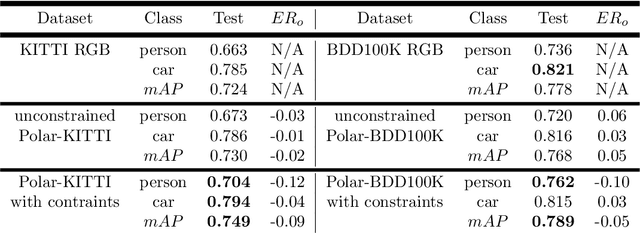
Polarimetric imaging, along with deep learning, has shown improved performances on different tasks including scene analysis. However, its robustness may be questioned because of the small size of the training datasets. Though the issue could be solved by data augmentation, polarization modalities are subject to physical feasibility constraints unaddressed by classical data augmentation techniques. To address this issue, we propose to use CycleGAN, an image translation technique based on deep generative models that solely relies on unpaired data, to transfer large labeled road scene datasets to the polarimetric domain. We design several auxiliary loss terms that, alongside the CycleGAN losses, deal with the physical constraints of polarimetric images. The efficiency of this solution is demonstrated on road scene object detection tasks where generated realistic polarimetric images allow to improve performances on cars and pedestrian detection up to 9%. The resulting constrained CycleGAN is publicly released, allowing anyone to generate their own polarimetric images.
Pixel-wise Conditioned Generative Adversarial Networks for Image Synthesis and Completion
Feb 04, 2020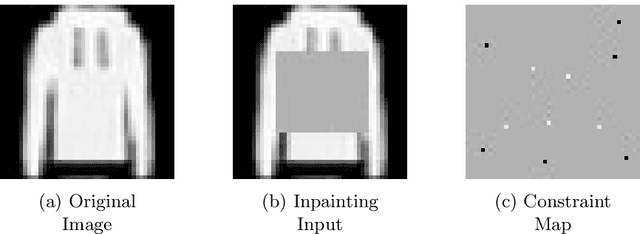
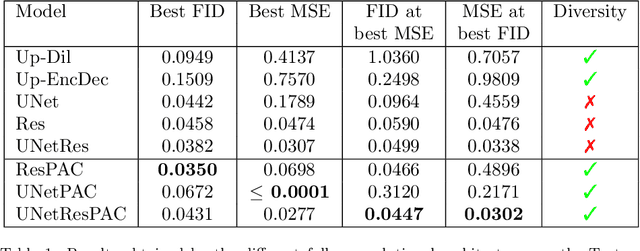
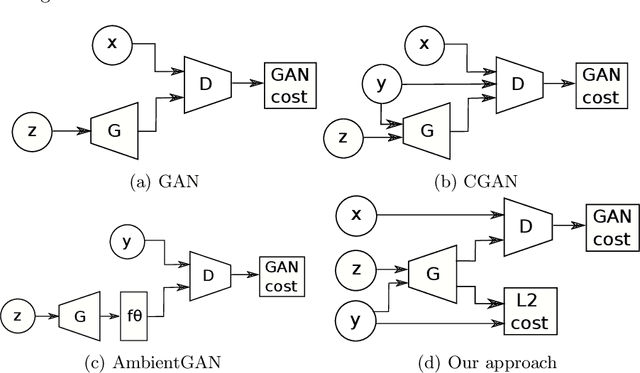
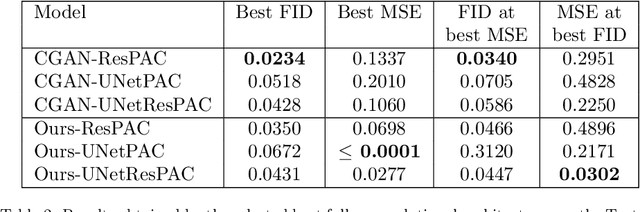
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works have extended GANs to image inpainting by conditioning the generation with parts of the image to be reconstructed. Despite their success, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper we investigate the effectiveness of conditioning GANs when very few pixel values are provided. We propose a modelling framework which results in adding an explicit cost term to the GAN objective function to enforce pixel-wise conditioning. We investigate the influence of this regularization term on the quality of the generated images and the fulfillment of the given pixel constraints. Using the recent PacGAN technique, we ensure that we keep diversity in the generated samples. Conducted experiments on FashionMNIST show that the regularization term effectively controls the trade-off between quality of the generated images and the conditioning. Experimental evaluation on the CIFAR-10 and CelebA datasets evidences that our method achieves accurate results both visually and quantitatively in term of Fr\'echet Inception Distance, while still enforcing the pixel conditioning. We also evaluate our method on a texture image generation task using fully-convolutional networks. As a final contribution, we apply the method to a classical geological simulation application.
Pixel-wise Conditioning of Generative Adversarial Networks
Nov 02, 2019
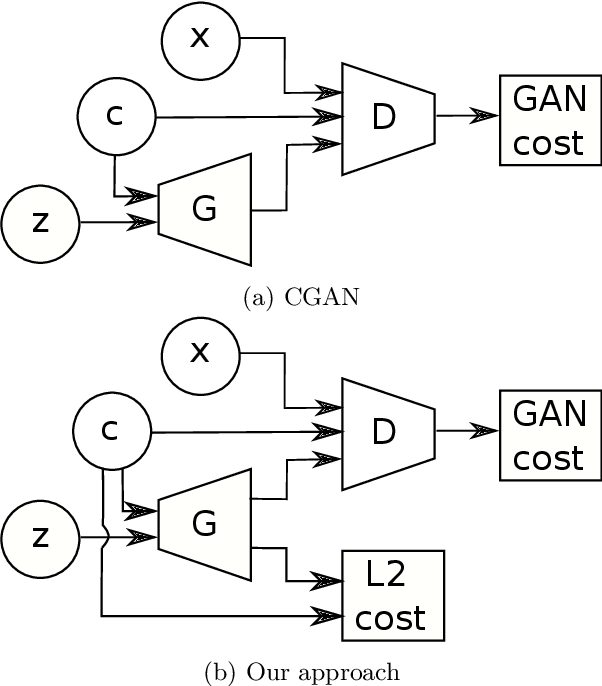
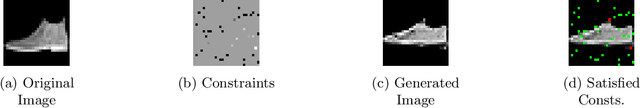
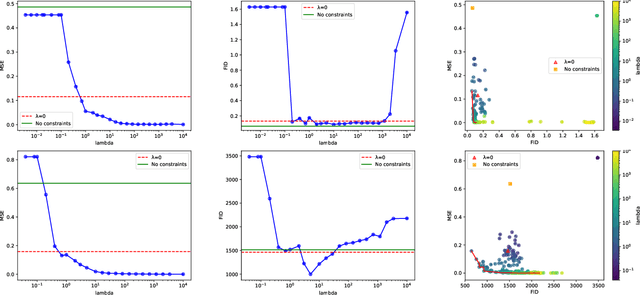
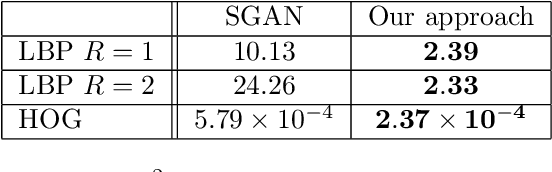
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works extended GANs to image inpainting by conditioning the generation with parts of the image one wants to reconstruct. However, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper, we study the effectiveness of conditioning GANs by adding an explicit regularization term to enforce pixel-wise conditions when very few pixel values are provided. In addition, we also investigate the influence of this regularization term on the quality of the generated images and the satisfaction of the conditions. Conducted experiments on MNIST and FashionMNIST show evidence that this regularization term allows for controlling the trade-off between quality of the generated images and constraint satisfaction.
Dilated Spatial Generative Adversarial Networks for Ergodic Image Generation
May 15, 2019


Generative models have recently received renewed attention as a result of adversarial learning. Generative adversarial networks consist of samples generation model and a discrimination model able to distinguish between genuine and synthetic samples. In combination with convolutional (for the discriminator) and de-convolutional (for the generator) layers, they are particularly suitable for image generation, especially of natural scenes. However, the presence of fully connected layers adds global dependencies in the generated images. This may lead to high and global variations in the generated sample for small local variations in the input noise. In this work we propose to use architec-tures based on fully convolutional networks (including among others dilated layers), architectures specifically designed to generate globally ergodic images, that is images without global dependencies. Conducted experiments reveal that these architectures are well suited for generating natural textures such as geologic structures .
CTCModel: a Keras Model for Connectionist Temporal Classification
Jan 23, 2019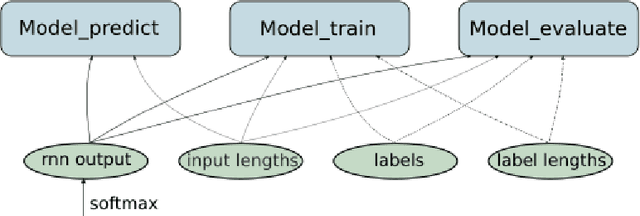
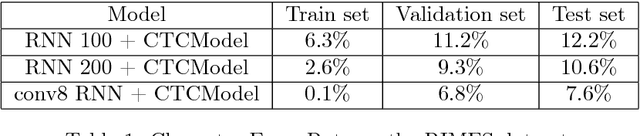
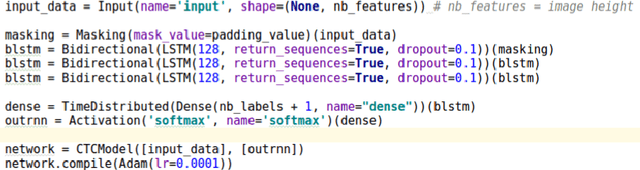
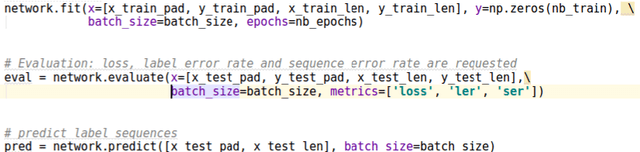
We report an extension of a Keras Model, called CTCModel, to perform the Connectionist Temporal Classification (CTC) in a transparent way. Combined with Recurrent Neural Networks, the Connectionist Temporal Classification is the reference method for dealing with unsegmented input sequences, i.e. with data that are a couple of observation and label sequences where each label is related to a subset of observation frames. CTCModel makes use of the CTC implementation in the Tensorflow backend for training and predicting sequences of labels using Keras. It consists of three branches made of Keras models: one for training, computing the CTC loss function; one for predicting, providing sequences of labels; and one for evaluating that returns standard metrics for analyzing sequences of predictions.