 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic quantification of breast cancer biomarkers from multiple 18F-FDG PET image segmentation
Feb 06, 2025



Neoadjuvant chemotherapy (NAC) has become a standard clinical practice for tumor downsizing in breast cancer with 18F-FDG Positron Emission Tomography (PET). Our work aims to leverage PET imaging for the segmentation of breast lesions. The focus is on developing an automated system that accurately segments primary tumor regions and extracts key biomarkers from these areas to provide insights into the evolution of breast cancer following the first course of NAC. 243 baseline 18F-FDG PET scans (PET_Bl) and 180 follow-up 18F-FDG PET scans (PET_Fu) were acquired before and after the first course of NAC, respectively. Firstly, a deep learning-based breast tumor segmentation method was developed. The optimal baseline model (model trained on baseline exams) was fine-tuned on 15 follow-up exams and adapted using active learning to segment tumor areas in PET_Fu. The pipeline computes biomarkers such as maximum standardized uptake value (SUVmax), metabolic tumor volume (MTV), and total lesion glycolysis (TLG) to evaluate tumor evolution between PET_Fu and PET_Bl. Quality control measures were employed to exclude aberrant outliers. The nnUNet deep learning model outperformed in tumor segmentation on PET_Bl, achieved a Dice similarity coefficient (DSC) of 0.89 and a Hausdorff distance (HD) of 3.52 mm. After fine-tuning, the model demonstrated a DSC of 0.78 and a HD of 4.95 mm on PET_Fu exams. Biomarkers analysis revealed very strong correlations whatever the biomarker between manually segmented and automatically predicted regions. The significant average decrease of SUVmax, MTV and TLG were 5.22, 11.79 cm3 and 19.23 cm3, respectively. The presented approach demonstrates an automated system for breast tumor segmentation from 18F-FDG PET. Thanks to the extracted biomarkers, our method enables the automatic assessment of cancer progression.
HiDAnet: RGB-D Salient Object Detection via Hierarchical Depth Awareness
Jan 18, 2023RGB-D saliency detection aims to fuse multi-modal cues to accurately localize salient regions. Existing works often adopt attention modules for feature modeling, with few methods explicitly leveraging fine-grained details to merge with semantic cues. Thus, despite the auxiliary depth information, it is still challenging for existing models to distinguish objects with similar appearances but at distinct camera distances. In this paper, from a new perspective, we propose a novel Hierarchical Depth Awareness network (HiDAnet) for RGB-D saliency detection. Our motivation comes from the observation that the multi-granularity properties of geometric priors correlate well with the neural network hierarchies. To realize multi-modal and multi-level fusion, we first use a granularity-based attention scheme to strengthen the discriminatory power of RGB and depth features separately. Then we introduce a unified cross dual-attention module for multi-modal and multi-level fusion in a coarse-to-fine manner. The encoded multi-modal features are gradually aggregated into a shared decoder. Further, we exploit a multi-scale loss to take full advantage of the hierarchical information. Extensive experiments on challenging benchmark datasets demonstrate that our HiDAnet performs favorably over the state-of-the-art methods by large margins.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022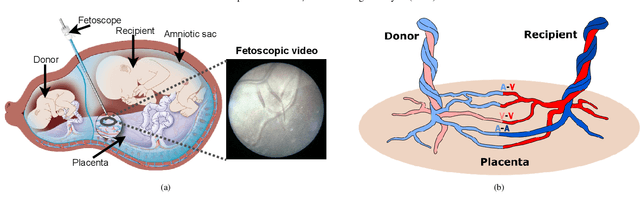
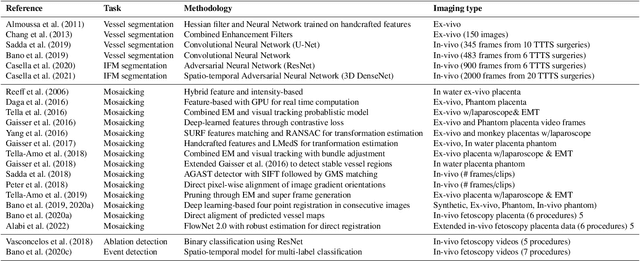
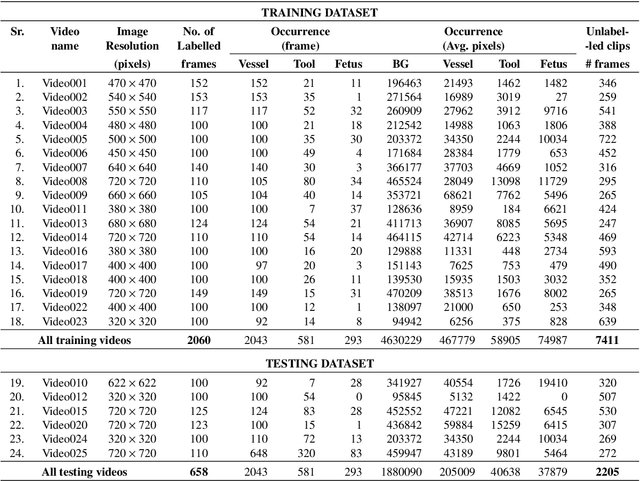
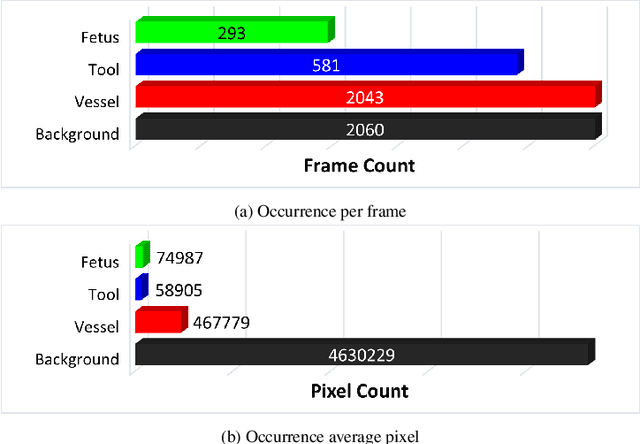
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
Physically-admissible polarimetric data augmentation for road-scene analysis
Jun 15, 2022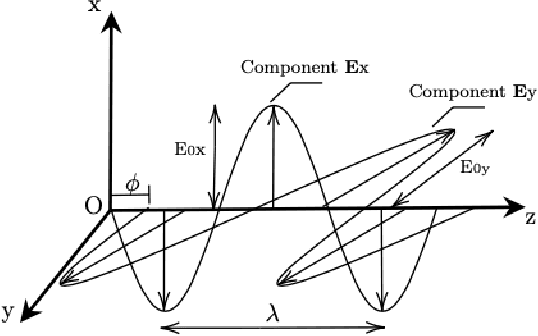
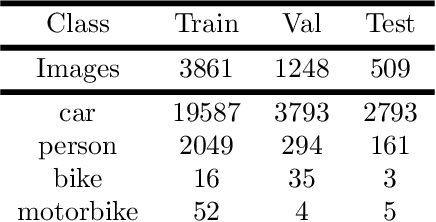
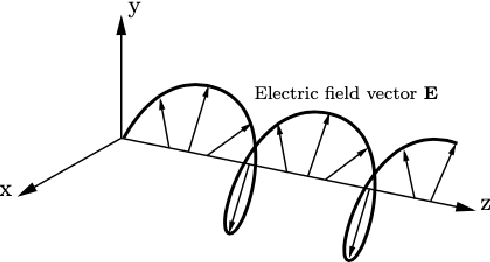
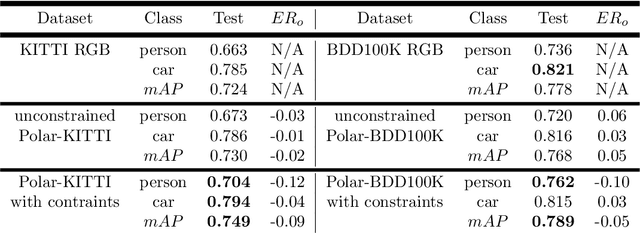
Polarimetric imaging, along with deep learning, has shown improved performances on different tasks including scene analysis. However, its robustness may be questioned because of the small size of the training datasets. Though the issue could be solved by data augmentation, polarization modalities are subject to physical feasibility constraints unaddressed by classical data augmentation techniques. To address this issue, we propose to use CycleGAN, an image translation technique based on deep generative models that solely relies on unpaired data, to transfer large labeled road scene datasets to the polarimetric domain. We design several auxiliary loss terms that, alongside the CycleGAN losses, deal with the physical constraints of polarimetric images. The efficiency of this solution is demonstrated on road scene object detection tasks where generated realistic polarimetric images allow to improve performances on cars and pedestrian detection up to 9%. The resulting constrained CycleGAN is publicly released, allowing anyone to generate their own polarimetric images.
Deep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021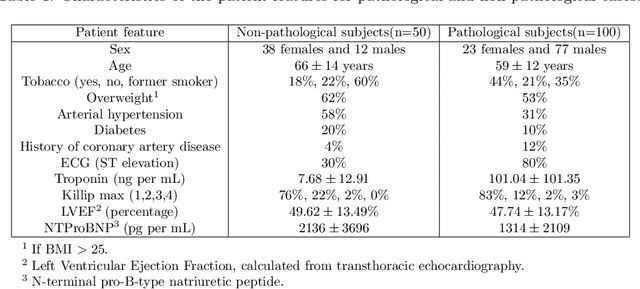

A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
Towards urban scenes understanding through polarization cues
Jun 03, 2021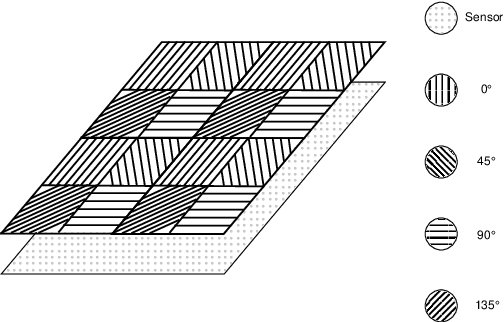

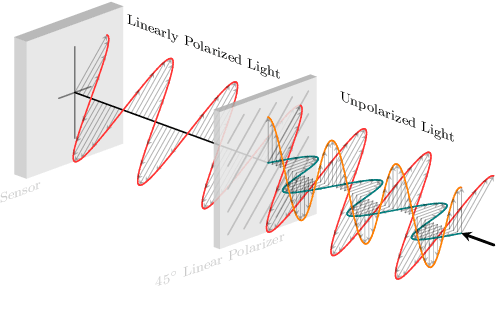
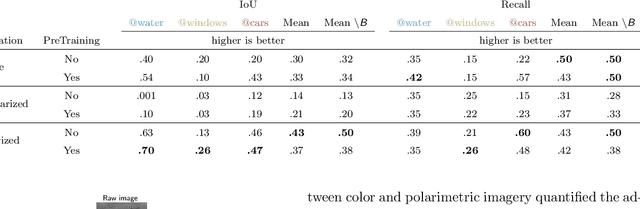
Autonomous robotics is critically affected by the robustness of its scene understanding algorithms. We propose a two-axis pipeline based on polarization indices to analyze dynamic urban scenes. As robots evolve in unknown environments, they are prone to encountering specular obstacles. Usually, specular phenomena are rarely taken into account by algorithms which causes misinterpretations and erroneous estimates. By exploiting all the light properties, systems can greatly increase their robustness to events. In addition to the conventional photometric characteristics, we propose to include polarization sensing. We demonstrate in this paper that the contribution of polarization measurement increases both the performances of segmentation and the quality of depth estimation. Our polarimetry-based approaches are compared here with other state-of-the-art RGB-centric methods showing interest of using polarization imaging.
P2D: a self-supervised method for depth estimation from polarimetry
Jul 15, 2020

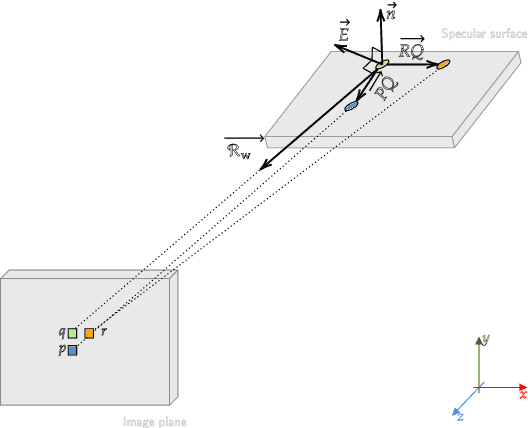
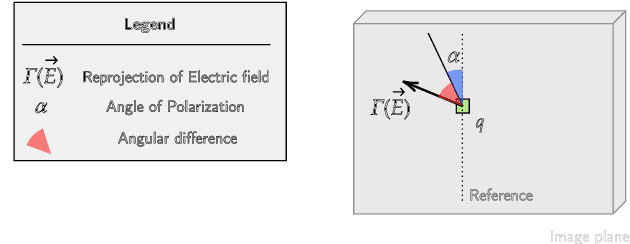
Monocular depth estimation is a recurring subject in the field of computer vision. Its ability to describe scenes via a depth map while reducing the constraints related to the formulation of perspective geometry tends to favor its use. However, despite the constant improvement of algorithms, most methods exploit only colorimetric information. Consequently, robustness to events to which the modality is not sensitive to, like specularity or transparency, is neglected. In response to this phenomenon, we propose using polarimetry as an input for a self-supervised monodepth network. Therefore, we propose exploiting polarization cues to encourage accurate reconstruction of scenes. Furthermore, we include a term of polarimetric regularization to state-of-the-art method to take specific advantage of the data. Our method is evaluated both qualitatively and quantitatively demonstrating that the contribution of this new information as well as an enhanced loss function improves depth estimation results, especially for specular areas.
Segmentation of the Myocardium on Late-Gadolinium Enhanced MRI based on 2.5 D Residual Squeeze and Excitation Deep Learning Model
May 27, 2020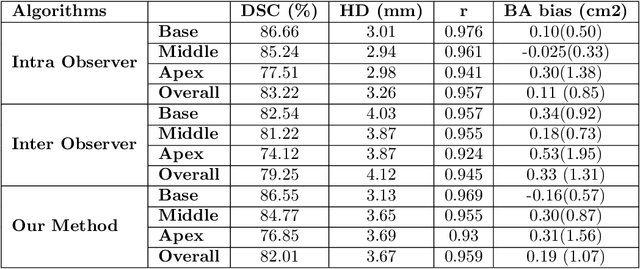
Cardiac left ventricular (LV) segmentation from short-axis MRI acquired 10 minutes after the injection of a contrast agent (LGE-MRI) is a necessary step in the processing allowing the identification and diagnosis of cardiac diseases such as myocardial infarction. However, this segmentation is challenging due to high variability across subjects and the potential lack of contrast between structures. Then, the main objective of this work is to develop an accurate automatic segmentation method based on deep learning models for the myocardial borders on LGE-MRI. To this end, 2.5 D residual neural network integrated with a squeeze and excitation blocks in encoder side with specialized convolutional has been proposed. Late fusion has been used to merge the output of the best trained proposed models from a different set of hyperparameters. A total number of 320 exams (with a mean number of 6 slices per exam) were used for training and 28 exams used for testing. The performance analysis of the proposed ensemble model in the basal and middle slices was similar as compared to intra-observer study and slightly lower at apical slices. The overall Dice score was 82.01% by our proposed method as compared to Dice score of 83.22% obtained from the intra observer study. The proposed model could be used for the automatic segmentation of myocardial border that is a very important step for accurate quantification of no-reflow, myocardial infarction, myocarditis, and hypertrophic cardiomyopathy, among others.
Polarimetric image augmentation
May 22, 2020


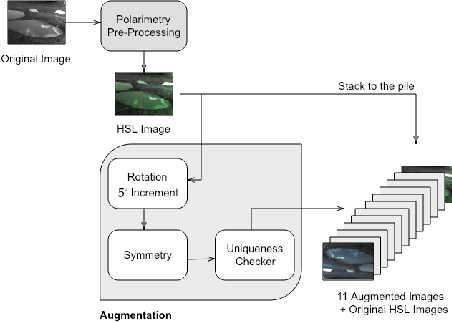
Robotics applications in urban environments are subject to obstacles that exhibit specular reflections hampering autonomous navigation. On the other hand, these reflections are highly polarized and this extra information can successfully be used to segment the specular areas. In nature, polarized light is obtained by reflection or scattering. Deep Convolutional Neural Networks (DCNNs) have shown excellent segmentation results, but require a significant amount of data to achieve best performances. The lack of data is usually overcomed by using augmentation methods. However, unlike RGB images, polarization images are not only scalar (intensity) images and standard augmentation techniques cannot be applied straightforwardly. We propose to enhance deep learning models through a regularized augmentation procedure applied to polarimetric data in order to characterize scenes more effectively under challenging conditions. We subsequently observe an average of 18.1% improvement in IoU between non augmented and regularized training procedures on real world data.
Road scenes analysis in adverse weather conditions by polarization-encoded images and adapted deep learning
Oct 02, 2019

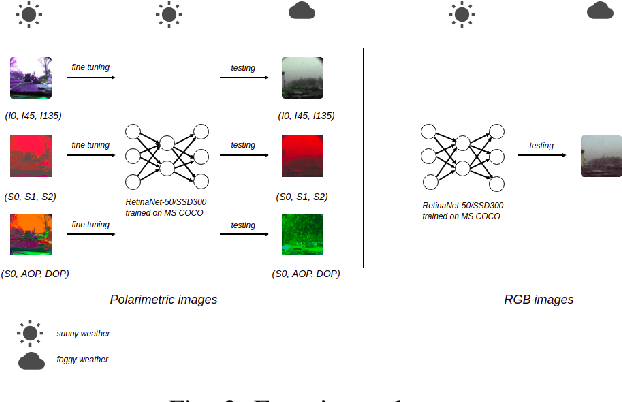

Object detection in road scenes is necessary to develop both autonomous vehicles and driving assistance systems. Even if deep neural networks for recognition task have shown great performances using conventional images, they fail to detect objects in road scenes in complex acquisition situations. In contrast, polarization images, characterizing the light wave, can robustly describe important physical properties of the object even under poor illumination or strong reflections. This paper shows how non-conventional polarimetric imaging modality overcomes the classical methods for object detection especially in adverse weather conditions. The efficiency of the proposed method is mostly due to the high power of the polarimetry to discriminate any object by its reflective properties and on the use of deep neural networks for object detection. Our goal by this work, is to prove that polarimetry brings a real added value compared with RGB images for object detection. Experimental results on our own dataset composed of road scene images taken during adverse weather conditions show that polarimetry together with deep learning can improve the state-of-the-art by about 20% to 50% on different detection tasks.