 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquiescence Bias in Large Language Models
Sep 10, 2025Acquiescence bias, i.e. the tendency of humans to agree with statements in surveys, independent of their actual beliefs, is well researched and documented. Since Large Language Models (LLMs) have been shown to be very influenceable by relatively small changes in input and are trained on human-generated data, it is reasonable to assume that they could show a similar tendency. We present a study investigating the presence of acquiescence bias in LLMs across different models, tasks, and languages (English, German, and Polish). Our results indicate that, contrary to humans, LLMs display a bias towards answering no, regardless of whether it indicates agreement or disagreement.
A Retail-Corpus for Aspect-Based Sentiment Analysis with Large Language Models
Aug 25, 2025



Aspect-based sentiment analysis enhances sentiment detection by associating it with specific aspects, offering deeper insights than traditional sentiment analysis. This study introduces a manually annotated dataset of 10,814 multilingual customer reviews covering brick-and-mortar retail stores, labeled with eight aspect categories and their sentiment. Using this dataset, the performance of GPT-4 and LLaMA-3 in aspect based sentiment analysis is evaluated to establish a baseline for the newly introduced data. The results show both models achieving over 85% accuracy, while GPT-4 outperforms LLaMA-3 overall with regard to all relevant metrics.
The Impact of Annotator Personas on LLM Behavior Across the Perspectivism Spectrum
Aug 23, 2025In this work, we explore the capability of Large Language Models (LLMs) to annotate hate speech and abusiveness while considering predefined annotator personas within the strong-to-weak data perspectivism spectra. We evaluated LLM-generated annotations against existing annotator modeling techniques for perspective modeling. Our findings show that LLMs selectively use demographic attributes from the personas. We identified prototypical annotators, with persona features that show varying degrees of alignment with the original human annotators. Within the data perspectivism paradigm, annotator modeling techniques that do not explicitly rely on annotator information performed better under weak data perspectivism compared to both strong data perspectivism and human annotations, suggesting LLM-generated views tend towards aggregation despite subjective prompting. However, for more personalized datasets tailored to strong perspectivism, the performance of LLM annotator modeling approached, but did not exceed, human annotators.
Position: Editing Large Language Models Poses Serious Safety Risks
Feb 05, 2025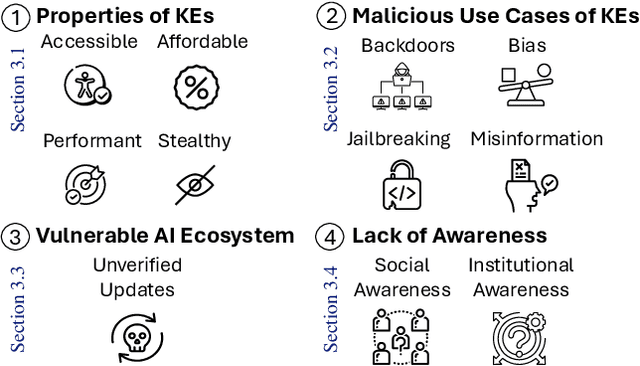



Large Language Models (LLMs) contain large amounts of facts about the world. These facts can become outdated over time, which has led to the development of knowledge editing methods (KEs) that can change specific facts in LLMs with limited side effects. This position paper argues that editing LLMs poses serious safety risks that have been largely overlooked. First, we note the fact that KEs are widely available, computationally inexpensive, highly performant, and stealthy makes them an attractive tool for malicious actors. Second, we discuss malicious use cases of KEs, showing how KEs can be easily adapted for a variety of malicious purposes. Third, we highlight vulnerabilities in the AI ecosystem that allow unrestricted uploading and downloading of updated models without verification. Fourth, we argue that a lack of social and institutional awareness exacerbates this risk, and discuss the implications for different stakeholders. We call on the community to (i) research tamper-resistant models and countermeasures against malicious model editing, and (ii) actively engage in securing the AI ecosystem.
Leveraging Annotator Disagreement for Text Classification
Sep 26, 2024



It is common practice in text classification to only use one majority label for model training even if a dataset has been annotated by multiple annotators. Doing so can remove valuable nuances and diverse perspectives inherent in the annotators' assessments. This paper proposes and compares three different strategies to leverage annotator disagreement for text classification: a probability-based multi-label method, an ensemble system, and instruction tuning. All three approaches are evaluated on the tasks of hate speech and abusive conversation detection, which inherently entail a high degree of subjectivity. Moreover, to evaluate the effectiveness of embracing annotation disagreements for model training, we conduct an online survey that compares the performance of the multi-label model against a baseline model, which is trained with the majority label. The results show that in hate speech detection, the multi-label method outperforms the other two approaches, while in abusive conversation detection, instruction tuning achieves the best performance. The results of the survey also show that the outputs from the multi-label models are considered a better representation of the texts than the single-label model.
Beware of Validation by Eye: Visual Validation of Linear Trends in Scatterplots
Jul 16, 2024



Visual validation of regression models in scatterplots is a common practice for assessing model quality, yet its efficacy remains unquantified. We conducted two empirical experiments to investigate individuals' ability to visually validate linear regression models (linear trends) and to examine the impact of common visualization designs on validation quality. The first experiment showed that the level of accuracy for visual estimation of slope (i.e., fitting a line to data) is higher than for visual validation of slope (i.e., accepting a shown line). Notably, we found bias toward slopes that are "too steep" in both cases. This lead to novel insights that participants naturally assessed regression with orthogonal distances between the points and the line (i.e., ODR regression) rather than the common vertical distances (OLS regression). In the second experiment, we investigated whether incorporating common designs for regression visualization (error lines, bounding boxes, and confidence intervals) would improve visual validation. Even though error lines reduced validation bias, results failed to show the desired improvements in accuracy for any design. Overall, our findings suggest caution in using visual model validation for linear trends in scatterplots.
AGB-DE: A Corpus for the Automated Legal Assessment of Clauses in German Consumer Contracts
Jun 10, 2024Legal tasks and datasets are often used as benchmarks for the capabilities of language models. However, openly available annotated datasets are rare. In this paper, we introduce AGB-DE, a corpus of 3,764 clauses from German consumer contracts that have been annotated and legally assessed by legal experts. Together with the data, we present a first baseline for the task of detecting potentially void clauses, comparing the performance of an SVM baseline with three fine-tuned open language models and the performance of GPT-3.5. Our results show the challenging nature of the task, with no approach exceeding an F1-score of 0.54. While the fine-tuned models often performed better with regard to precision, GPT-3.5 outperformed the other approaches with regard to recall. An analysis of the errors indicates that one of the main challenges could be the correct interpretation of complex clauses, rather than the decision boundaries of what is permissible and what is not.
Efficient Black-Box Adversarial Attacks on Neural Text Detectors
Nov 03, 2023



Neural text detectors are models trained to detect whether a given text was generated by a language model or written by a human. In this paper, we investigate three simple and resource-efficient strategies (parameter tweaking, prompt engineering, and character-level mutations) to alter texts generated by GPT-3.5 that are unsuspicious or unnoticeable for humans but cause misclassification by neural text detectors. The results show that especially parameter tweaking and character-level mutations are effective strategies.
Visual Validation versus Visual Estimation: A Study on the Average Value in Scatterplots
Jul 18, 2023



We investigate the ability of individuals to visually validate statistical models in terms of their fit to the data. While visual model estimation has been studied extensively, visual model validation remains under-investigated. It is unknown how well people are able to visually validate models, and how their performance compares to visual and computational estimation. As a starting point, we conducted a study across two populations (crowdsourced and volunteers). Participants had to both visually estimate (i.e, draw) and visually validate (i.e., accept or reject) the frequently studied model of averages. Across both populations, the level of accuracy of the models that were considered valid was lower than the accuracy of the estimated models. We find that participants' validation and estimation were unbiased. Moreover, their natural critical point between accepting and rejecting a given mean value is close to the boundary of its 95% confidence interval, indicating that the visually perceived confidence interval corresponds to a common statistical standard. Our work contributes to the understanding of visual model validation and opens new research opportunities.
Reclaiming the Horizon: Novel Visualization Designs for Time-Series Data with Large Value Ranges
Jul 18, 2023We introduce two novel visualization designs to support practitioners in performing identification and discrimination tasks on large value ranges (i.e., several orders of magnitude) in time-series data: (1) The order of magnitude horizon graph, which extends the classic horizon graph; and (2) the order of magnitude line chart, which adapts the log-line chart. These new visualization designs visualize large value ranges by explicitly splitting the mantissa m and exponent e of a value v = m * 10e . We evaluate our novel designs against the most relevant state-of-the-art visualizations in an empirical user study. It focuses on four main tasks commonly employed in the analysis of time-series and large value ranges visualization: identification, discrimination, estimation, and trend detection. For each task we analyse error, confidence, and response time. The new order of magnitude horizon graph performs better or equal to all other designs in identification, discrimination, and estimation tasks. Only for trend detection tasks, the more traditional horizon graphs reported better performance. Our results are domain-independent, only requiring time-series data with large value ranges.