 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Few-shot Learning for Multi-label Classification of Scientific Documents with Many Classes
Oct 08, 2024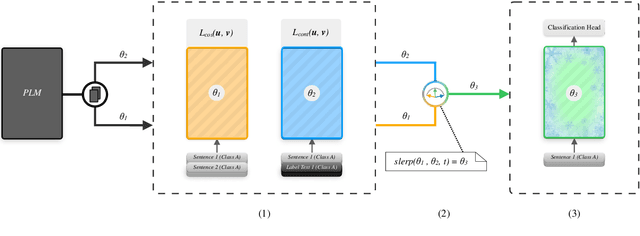
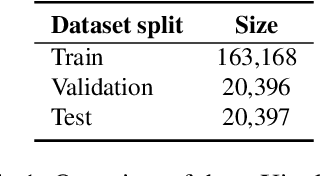
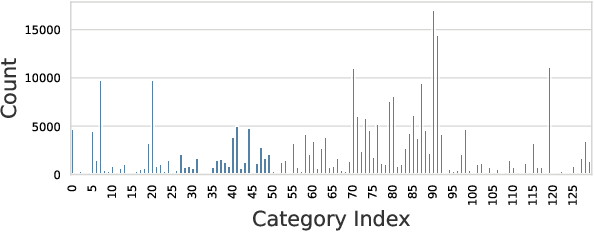
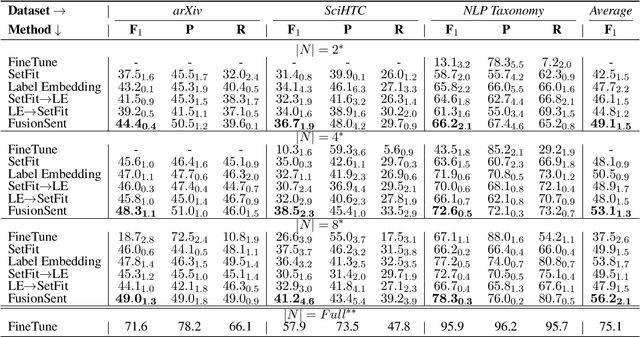
Scientific document classification is a critical task and often involves many classes. However, collecting human-labeled data for many classes is expensive and usually leads to label-scarce scenarios. Moreover, recent work has shown that sentence embedding model fine-tuning for few-shot classification is efficient, robust, and effective. In this work, we propose FusionSent (Fusion-based Sentence Embedding Fine-tuning), an efficient and prompt-free approach for few-shot classification of scientific documents with many classes. FusionSent uses available training examples and their respective label texts to contrastively fine-tune two different sentence embedding models. Afterward, the parameters of both fine-tuned models are fused to combine the complementary knowledge from the separate fine-tuning steps into a single model. Finally, the resulting sentence embedding model is frozen to embed the training instances, which are then used as input features to train a classification head. Our experiments show that FusionSent significantly outperforms strong baselines by an average of $6.0$ $F_{1}$ points across multiple scientific document classification datasets. In addition, we introduce a new dataset for multi-label classification of scientific documents, which contains 183,565 scientific articles and 130 classes from the arXiv category taxonomy. Code and data are available at https://github.com/sebischair/FusionSent.
An Improved Method for Class-specific Keyword Extraction: A Case Study in the German Business Registry
Jul 19, 2024

The task of $\textit{keyword extraction}$ is often an important initial step in unsupervised information extraction, forming the basis for tasks such as topic modeling or document classification. While recent methods have proven to be quite effective in the extraction of keywords, the identification of $\textit{class-specific}$ keywords, or only those pertaining to a predefined class, remains challenging. In this work, we propose an improved method for class-specific keyword extraction, which builds upon the popular $\textbf{KeyBERT}$ library to identify only keywords related to a class described by $\textit{seed keywords}$. We test this method using a dataset of German business registry entries, where the goal is to classify each business according to an economic sector. Our results reveal that our method greatly improves upon previous approaches, setting a new standard for $\textit{class-specific}$ keyword extraction.
NLP-KG: A System for Exploratory Search of Scientific Literature in Natural Language Processing
Jun 21, 2024Scientific literature searches are often exploratory, whereby users are not yet familiar with a particular field or concept but are interested in learning more about it. However, existing systems for scientific literature search are typically tailored to keyword-based lookup searches, limiting the possibilities for exploration. We propose NLP-KG, a feature-rich system designed to support the exploration of research literature in unfamiliar natural language processing (NLP) fields. In addition to a semantic search, NLP-KG allows users to easily find survey papers that provide a quick introduction to a field of interest. Further, a Fields of Study hierarchy graph enables users to familiarize themselves with a field and its related areas. Finally, a chat interface allows users to ask questions about unfamiliar concepts or specific articles in NLP and obtain answers grounded in knowledge retrieved from scientific publications. Our system provides users with comprehensive exploration possibilities, supporting them in investigating the relationships between different fields, understanding unfamiliar concepts in NLP, and finding relevant research literature. Demo, video, and code are available at: https://github.com/NLP-Knowledge-Graph/NLP-KG-WebApp.
Enterprise Use Cases Combining Knowledge Graphs and Natural Language Processing
Apr 01, 2024Knowledge management is a critical challenge for enterprises in today's digital world, as the volume and complexity of data being generated and collected continue to grow incessantly. Knowledge graphs (KG) emerged as a promising solution to this problem by providing a flexible, scalable, and semantically rich way to organize and make sense of data. This paper builds upon a recent survey of the research literature on combining KGs and Natural Language Processing (NLP). Based on selected application scenarios from enterprise context, we discuss synergies that result from such a combination. We cover various approaches from the three core areas of KG construction, reasoning as well as KG-based NLP tasks. In addition to explaining innovative enterprise use cases, we assess their maturity in terms of practical applicability and conclude with an outlook on emergent application areas for the future.
Efficient Domain Adaptation of Sentence Embeddings using Adapters
Jul 22, 2023



Sentence embeddings enable us to capture the semantic similarity of short texts. Most sentence embedding models are trained for general semantic textual similarity (STS) tasks. Therefore, to use sentence embeddings in a particular domain, the model must be adapted to it in order to achieve good results. Usually, this is done by fine-tuning the entire sentence embedding model for the domain of interest. While this approach yields state-of-the-art results, all of the model's weights are updated during fine-tuning, making this method resource-intensive. Therefore, instead of fine-tuning entire sentence embedding models for each target domain individually, we propose to train lightweight adapters. These domain-specific adapters do not require fine-tuning all underlying sentence embedding model parameters. Instead, we only train a small number of additional parameters while keeping the weights of the underlying sentence embedding model fixed. Training domain-specific adapters allows always using the same base model and only exchanging the domain-specific adapters to adapt sentence embeddings to a specific domain. We show that using adapters for parameter-efficient domain adaptation of sentence embeddings yields competitive performance within 1% of a domain-adapted, entirely fine-tuned sentence embedding model while only training approximately 3.6% of the parameters.
AspectCSE: Sentence Embeddings for Aspect-based Semantic Textual Similarity using Contrastive Learning and Structured Knowledge
Jul 22, 2023Generic sentence embeddings provide a coarse-grained approximation of semantic textual similarity but ignore specific aspects that make texts similar. Conversely, aspect-based sentence embeddings provide similarities between texts based on certain predefined aspects. Thus, similarity predictions of texts are more targeted to specific requirements and more easily explainable. In this paper, we present AspectCSE, an approach for aspect-based contrastive learning of sentence embeddings. Results indicate that AspectCSE achieves an average improvement of 3.97% on information retrieval tasks across multiple aspects compared to the previous best results. We also propose using Wikidata knowledge graph properties to train models of multi-aspect sentence embeddings in which multiple specific aspects are simultaneously considered during similarity predictions. We demonstrate that multi-aspect embeddings outperform single-aspect embeddings on aspect-specific information retrieval tasks. Finally, we examine the aspect-based sentence embedding space and demonstrate that embeddings of semantically similar aspect labels are often close, even without explicit similarity training between different aspect labels.
Exploring the Landscape of Natural Language Processing Research
Jul 20, 2023



As an efficient approach to understand, generate, and process natural language texts, research in natural language processing (NLP) has exhibited a rapid spread and wide adoption in recent years. Given the increasing amount of research work in this area, several NLP-related approaches have been surveyed in the research community. However, a comprehensive study that categorizes established topics, identifies trends, and outlines areas for future research remains absent to this day. Contributing to closing this gap, we have systematically classified and analyzed research papers included in the ACL Anthology. As a result, we present a structured overview of the research landscape, provide a taxonomy of fields-of-study in NLP, analyze recent developments in NLP, summarize our findings, and highlight directions for future work.
Evaluating Unsupervised Text Classification: Zero-shot and Similarity-based Approaches
Nov 29, 2022



Text classification of unseen classes is a challenging Natural Language Processing task and is mainly attempted using two different types of approaches. Similarity-based approaches attempt to classify instances based on similarities between text document representations and class description representations. Zero-shot text classification approaches aim to generalize knowledge gained from a training task by assigning appropriate labels of unknown classes to text documents. Although existing studies have already investigated individual approaches to these categories, the experiments in literature do not provide a consistent comparison. This paper addresses this gap by conducting a systematic evaluation of different similarity-based and zero-shot approaches for text classification of unseen classes. Different state-of-the-art approaches are benchmarked on four text classification datasets, including a new dataset from the medical domain. Additionally, novel SimCSE and SBERT-based baselines are proposed, as other baselines used in existing work yield weak classification results and are easily outperformed. Finally, the novel similarity-based Lbl2TransformerVec approach is presented, which outperforms previous state-of-the-art approaches in unsupervised text classification. Our experiments show that similarity-based approaches significantly outperform zero-shot approaches in most cases. Additionally, using SimCSE or SBERT embeddings instead of simpler text representations increases similarity-based classification results even further.
Lbl2Vec: An Embedding-Based Approach for Unsupervised Document Retrieval on Predefined Topics
Oct 12, 2022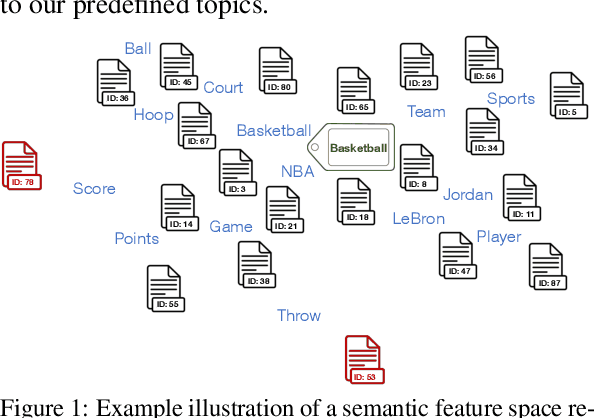


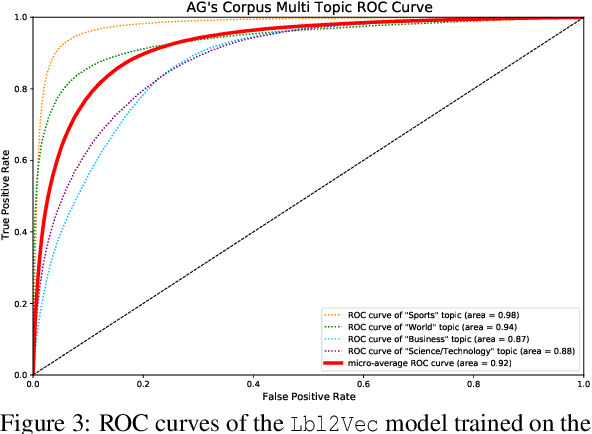
In this paper, we consider the task of retrieving documents with predefined topics from an unlabeled document dataset using an unsupervised approach. The proposed unsupervised approach requires only a small number of keywords describing the respective topics and no labeled document. Existing approaches either heavily relied on a large amount of additionally encoded world knowledge or on term-document frequencies. Contrariwise, we introduce a method that learns jointly embedded document and word vectors solely from the unlabeled document dataset in order to find documents that are semantically similar to the topics described by the keywords. The proposed method requires almost no text preprocessing but is simultaneously effective at retrieving relevant documents with high probability. When successively retrieving documents on different predefined topics from publicly available and commonly used datasets, we achieved an average area under the receiver operating characteristic curve value of 0.95 on one dataset and 0.92 on another. Further, our method can be used for multiclass document classification, without the need to assign labels to the dataset in advance. Compared with an unsupervised classification baseline, we increased F1 scores from 76.6 to 82.7 and from 61.0 to 75.1 on the respective datasets. For easy replication of our approach, we make the developed Lbl2Vec code publicly available as a ready-to-use tool under the 3-Clause BSD license.
PatternRank: Leveraging Pretrained Language Models and Part of Speech for Unsupervised Keyphrase Extraction
Oct 12, 2022
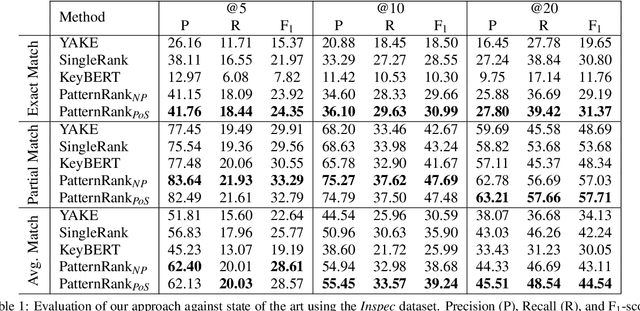
Keyphrase extraction is the process of automatically selecting a small set of most relevant phrases from a given text. Supervised keyphrase extraction approaches need large amounts of labeled training data and perform poorly outside the domain of the training data. In this paper, we present PatternRank, which leverages pretrained language models and part-of-speech for unsupervised keyphrase extraction from single documents. Our experiments show PatternRank achieves higher precision, recall and F1-scores than previous state-of-the-art approaches. In addition, we present the KeyphraseVectorizers package, which allows easy modification of part-of-speech patterns for candidate keyphrase selection, and hence adaptation of our approach to any domain.