 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatternRank: Leveraging Pretrained Language Models and Part of Speech for Unsupervised Keyphrase Extraction
Paper and Code

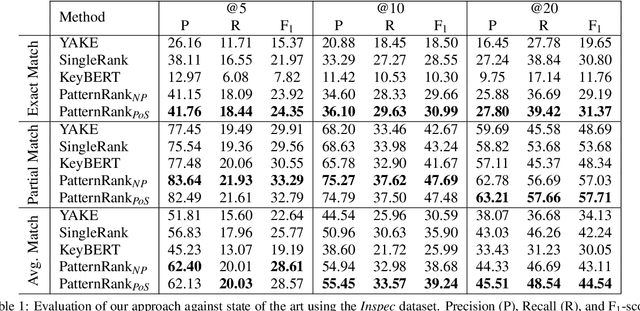
Keyphrase extraction is the process of automatically selecting a small set of most relevant phrases from a given text. Supervised keyphrase extraction approaches need large amounts of labeled training data and perform poorly outside the domain of the training data. In this paper, we present PatternRank, which leverages pretrained language models and part-of-speech for unsupervised keyphrase extraction from single documents. Our experiments show PatternRank achieves higher precision, recall and F1-scores than previous state-of-the-art approaches. In addition, we present the KeyphraseVectorizers package, which allows easy modification of part-of-speech patterns for candidate keyphrase selection, and hence adaptation of our approach to any domain.