 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Privacy Risks and Mitigations in Retrieval-Augmented Generation Systems
Jan 07, 2026The continued promise of Large Language Models (LLMs), particularly in their natural language understanding and generation capabilities, has driven a rapidly increasing interest in identifying and developing LLM use cases. In an effort to complement the ingrained "knowledge" of LLMs, Retrieval-Augmented Generation (RAG) techniques have become widely popular. At its core, RAG involves the coupling of LLMs with domain-specific knowledge bases, whereby the generation of a response to a user question is augmented with contextual and up-to-date information. The proliferation of RAG has sparked concerns about data privacy, particularly with the inherent risks that arise when leveraging databases with potentially sensitive information. Numerous recent works have explored various aspects of privacy risks in RAG systems, from adversarial attacks to proposed mitigations. With the goal of surveying and unifying these works, we ask one simple question: What are the privacy risks in RAG, and how can they be measured and mitigated? To answer this question, we conduct a systematic literature review of RAG works addressing privacy, and we systematize our findings into a comprehensive set of privacy risks, mitigation techniques, and evaluation strategies. We supplement these findings with two primary artifacts: a Taxonomy of RAG Privacy Risks and a RAG Privacy Process Diagram. Our work contributes to the study of privacy in RAG not only by conducting the first systematization of risks and mitigations, but also by uncovering important considerations when mitigating privacy risks in RAG systems and assessing the current maturity of proposed mitigations.
Extracting O*NET Features from the NLx Corpus to Build Public Use Aggregate Labor Market Data
Oct 01, 2025Data from online job postings are difficult to access and are not built in a standard or transparent manner. Data included in the standard taxonomy and occupational information database (O*NET) are updated infrequently and based on small survey samples. We adopt O*NET as a framework for building natural language processing tools that extract structured information from job postings. We publish the Job Ad Analysis Toolkit (JAAT), a collection of open-source tools built for this purpose, and demonstrate its reliability and accuracy in out-of-sample and LLM-as-a-Judge testing. We extract more than 10 billion data points from more than 155 million online job ads provided by the National Labor Exchange (NLx) Research Hub, including O*NET tasks, occupation codes, tools, and technologies, as well as wages, skills, industry, and more features. We describe the construction of a dataset of occupation, state, and industry level features aggregated by monthly active jobs from 2015 - 2025. We illustrate the potential for research and future uses in education and workforce development.
Leveraging Semantic Triples for Private Document Generation with Local Differential Privacy Guarantees
Aug 28, 2025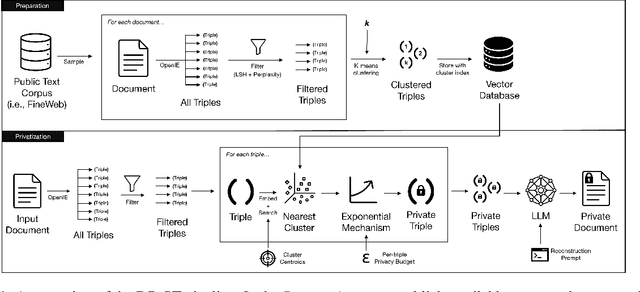
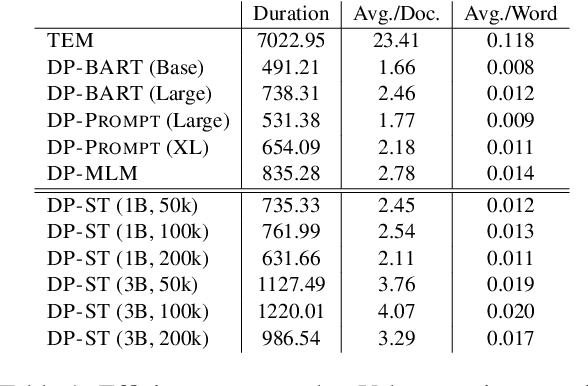
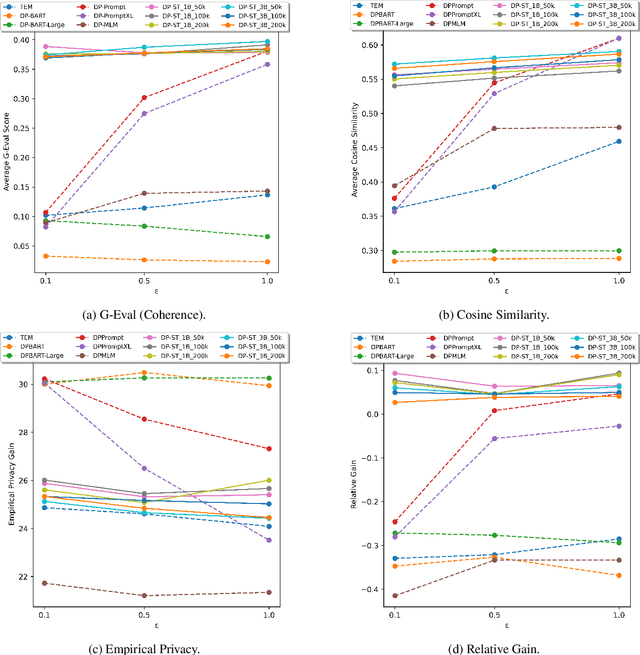

Many works at the intersection of Differential Privacy (DP) in Natural Language Processing aim to protect privacy by transforming texts under DP guarantees. This can be performed in a variety of ways, from word perturbations to full document rewriting, and most often under local DP. Here, an input text must be made indistinguishable from any other potential text, within some bound governed by the privacy parameter $\varepsilon$. Such a guarantee is quite demanding, and recent works show that privatizing texts under local DP can only be done reasonably under very high $\varepsilon$ values. Addressing this challenge, we introduce DP-ST, which leverages semantic triples for neighborhood-aware private document generation under local DP guarantees. Through the evaluation of our method, we demonstrate the effectiveness of the divide-and-conquer paradigm, particularly when limiting the DP notion (and privacy guarantees) to that of a privatization neighborhood. When combined with LLM post-processing, our method allows for coherent text generation even at lower $\varepsilon$ values, while still balancing privacy and utility. These findings highlight the importance of coherence in achieving balanced privatization outputs at reasonable $\varepsilon$ levels.
The Double-edged Sword of LLM-based Data Reconstruction: Understanding and Mitigating Contextual Vulnerability in Word-level Differential Privacy Text Sanitization
Aug 26, 2025
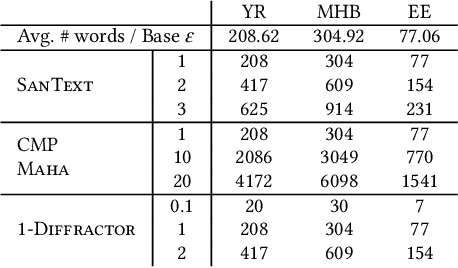


Differentially private text sanitization refers to the process of privatizing texts under the framework of Differential Privacy (DP), providing provable privacy guarantees while also empirically defending against adversaries seeking to harm privacy. Despite their simplicity, DP text sanitization methods operating at the word level exhibit a number of shortcomings, among them the tendency to leave contextual clues from the original texts due to randomization during sanitization $\unicode{x2013}$ this we refer to as $\textit{contextual vulnerability}$. Given the powerful contextual understanding and inference capabilities of Large Language Models (LLMs), we explore to what extent LLMs can be leveraged to exploit the contextual vulnerability of DP-sanitized texts. We expand on previous work not only in the use of advanced LLMs, but also in testing a broader range of sanitization mechanisms at various privacy levels. Our experiments uncover a double-edged sword effect of LLM-based data reconstruction attacks on privacy and utility: while LLMs can indeed infer original semantics and sometimes degrade empirical privacy protections, they can also be used for good, to improve the quality and privacy of DP-sanitized texts. Based on our findings, we propose recommendations for using LLM data reconstruction as a post-processing step, serving to increase privacy protection by thinking adversarially.
Spend Your Budget Wisely: Towards an Intelligent Distribution of the Privacy Budget in Differentially Private Text Rewriting
Mar 28, 2025
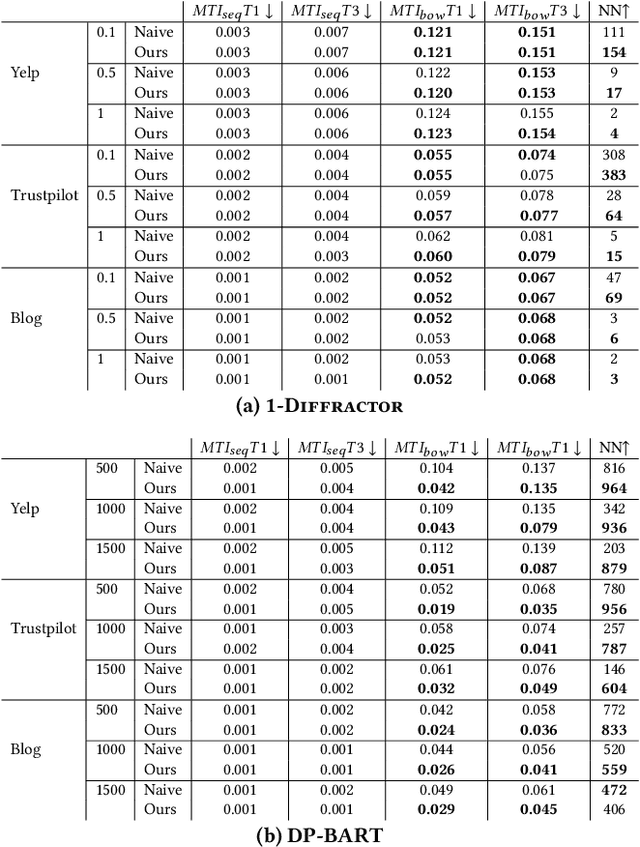

The task of $\textit{Differentially Private Text Rewriting}$ is a class of text privatization techniques in which (sensitive) input textual documents are $\textit{rewritten}$ under Differential Privacy (DP) guarantees. The motivation behind such methods is to hide both explicit and implicit identifiers that could be contained in text, while still retaining the semantic meaning of the original text, thus preserving utility. Recent years have seen an uptick in research output in this field, offering a diverse array of word-, sentence-, and document-level DP rewriting methods. Common to these methods is the selection of a privacy budget (i.e., the $\varepsilon$ parameter), which governs the degree to which a text is privatized. One major limitation of previous works, stemming directly from the unique structure of language itself, is the lack of consideration of $\textit{where}$ the privacy budget should be allocated, as not all aspects of language, and therefore text, are equally sensitive or personal. In this work, we are the first to address this shortcoming, asking the question of how a given privacy budget can be intelligently and sensibly distributed amongst a target document. We construct and evaluate a toolkit of linguistics- and NLP-based methods used to allocate a privacy budget to constituent tokens in a text document. In a series of privacy and utility experiments, we empirically demonstrate that given the same privacy budget, intelligent distribution leads to higher privacy levels and more positive trade-offs than a naive distribution of $\varepsilon$. Our work highlights the intricacies of text privatization with DP, and furthermore, it calls for further work on finding more efficient ways to maximize the privatization benefits offered by DP in text rewriting.
Investigating User Perspectives on Differentially Private Text Privatization
Mar 12, 2025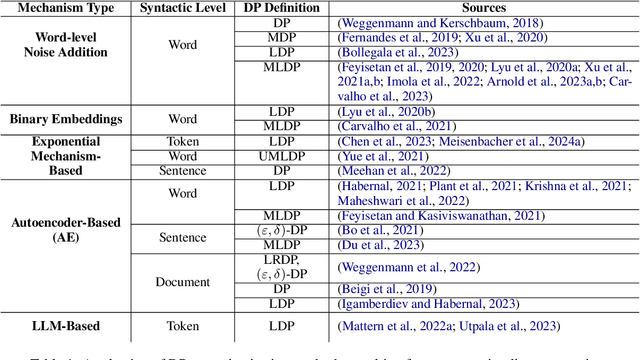
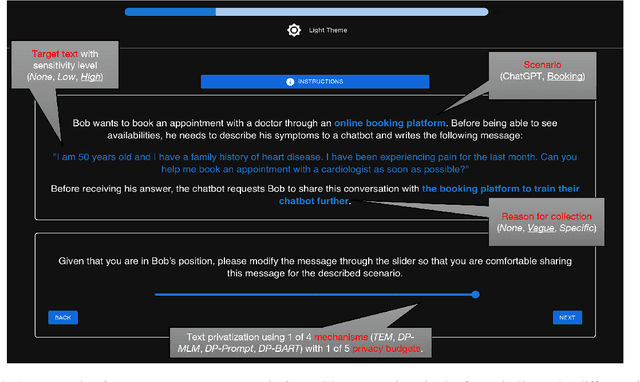
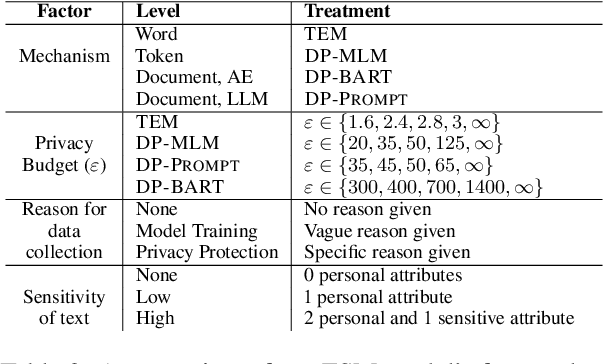
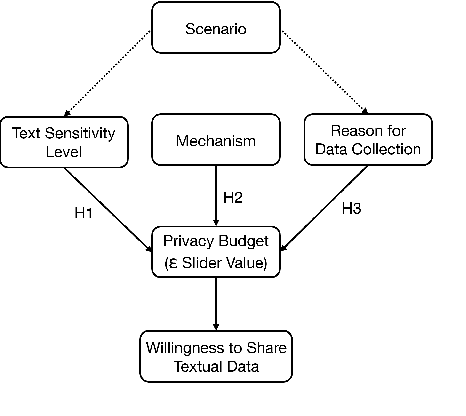
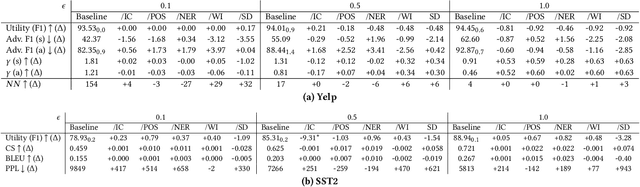
Recent literature has seen a considerable uptick in $\textit{Differentially Private Natural Language Processing}$ (DP NLP). This includes DP text privatization, where potentially sensitive input texts are transformed under DP to achieve privatized output texts that ideally mask sensitive information $\textit{and}$ maintain original semantics. Despite continued work to address the open challenges in DP text privatization, there remains a scarcity of work addressing user perceptions of this technology, a crucial aspect which serves as the final barrier to practical adoption. In this work, we conduct a survey study with 721 laypersons around the globe, investigating how the factors of $\textit{scenario}$, $\textit{data sensitivity}$, $\textit{mechanism type}$, and $\textit{reason for data collection}$ impact user preferences for text privatization. We learn that while all these factors play a role in influencing privacy decisions, users are highly sensitive to the utility and coherence of the private output texts. Our findings highlight the socio-technical factors that must be considered in the study of DP NLP, opening the door to further user-based investigations going forward.
Lexical Substitution is not Synonym Substitution: On the Importance of Producing Contextually Relevant Word Substitutes
Feb 06, 2025Lexical Substitution is the task of replacing a single word in a sentence with a similar one. This should ideally be one that is not necessarily only synonymous, but also fits well into the surrounding context of the target word, while preserving the sentence's grammatical structure. Recent advances in Lexical Substitution have leveraged the masked token prediction task of Pre-trained Language Models to generate replacements for a given word in a sentence. With this technique, we introduce ConCat, a simple augmented approach which utilizes the original sentence to bolster contextual information sent to the model. Compared to existing approaches, it proves to be very effective in guiding the model to make contextually relevant predictions for the target word. Our study includes a quantitative evaluation, measured via sentence similarity and task performance. In addition, we conduct a qualitative human analysis to validate that users prefer the substitutions proposed by our method, as opposed to previous methods. Finally, we test our approach on the prevailing benchmark for Lexical Substitution, CoInCo, revealing potential pitfalls of the benchmark. These insights serve as the foundation for a critical discussion on the way in which Lexical Substitution is evaluated.
On the Impact of Noise in Differentially Private Text Rewriting
Jan 31, 2025



The field of text privatization often leverages the notion of $\textit{Differential Privacy}$ (DP) to provide formal guarantees in the rewriting or obfuscation of sensitive textual data. A common and nearly ubiquitous form of DP application necessitates the addition of calibrated noise to vector representations of text, either at the data- or model-level, which is governed by the privacy parameter $\varepsilon$. However, noise addition almost undoubtedly leads to considerable utility loss, thereby highlighting one major drawback of DP in NLP. In this work, we introduce a new sentence infilling privatization technique, and we use this method to explore the effect of noise in DP text rewriting. We empirically demonstrate that non-DP privatization techniques excel in utility preservation and can find an acceptable empirical privacy-utility trade-off, yet cannot outperform DP methods in empirical privacy protections. Our results highlight the significant impact of noise in current DP rewriting mechanisms, leading to a discussion of the merits and challenges of DP in NLP, as well as the opportunities that non-DP methods present.
Thinking Outside of the Differential Privacy Box: A Case Study in Text Privatization with Language Model Prompting
Oct 01, 2024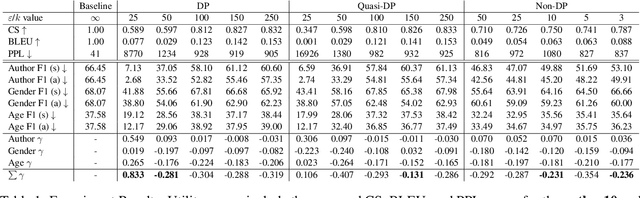
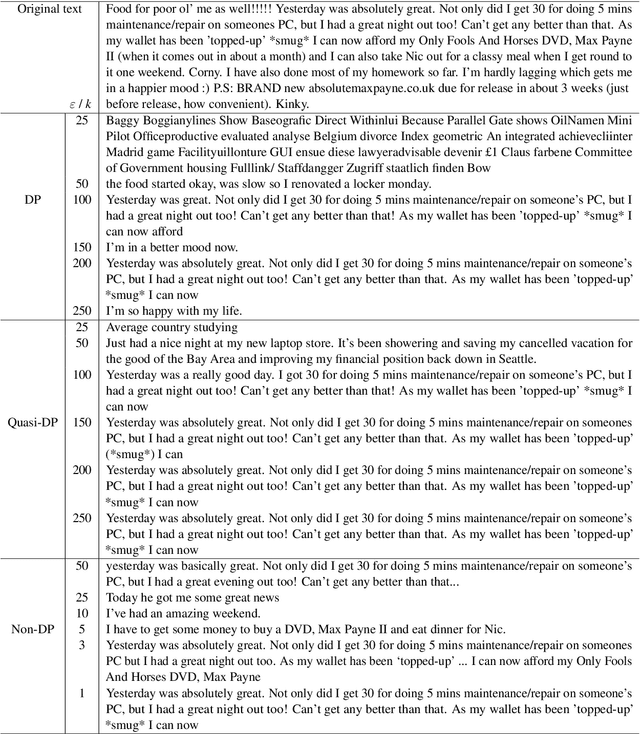

The field of privacy-preserving Natural Language Processing has risen in popularity, particularly at a time when concerns about privacy grow with the proliferation of Large Language Models. One solution consistently appearing in recent literature has been the integration of Differential Privacy (DP) into NLP techniques. In this paper, we take these approaches into critical view, discussing the restrictions that DP integration imposes, as well as bring to light the challenges that such restrictions entail. To accomplish this, we focus on $\textbf{DP-Prompt}$, a recent method for text privatization leveraging language models to rewrite texts. In particular, we explore this rewriting task in multiple scenarios, both with DP and without DP. To drive the discussion on the merits of DP in NLP, we conduct empirical utility and privacy experiments. Our results demonstrate the need for more discussion on the usability of DP in NLP and its benefits over non-DP approaches.
An Improved Method for Class-specific Keyword Extraction: A Case Study in the German Business Registry
Jul 19, 2024

The task of $\textit{keyword extraction}$ is often an important initial step in unsupervised information extraction, forming the basis for tasks such as topic modeling or document classification. While recent methods have proven to be quite effective in the extraction of keywords, the identification of $\textit{class-specific}$ keywords, or only those pertaining to a predefined class, remains challenging. In this work, we propose an improved method for class-specific keyword extraction, which builds upon the popular $\textbf{KeyBERT}$ library to identify only keywords related to a class described by $\textit{seed keywords}$. We test this method using a dataset of German business registry entries, where the goal is to classify each business according to an economic sector. Our results reveal that our method greatly improves upon previous approaches, setting a new standard for $\textit{class-specific}$ keyword extraction.