 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Rewrite It Again: A Post-Processing Method for Enhanced Semantic Similarity and Privacy Preservation of Differentially Private Rewritten Text
Paper and Code
May 31, 2024
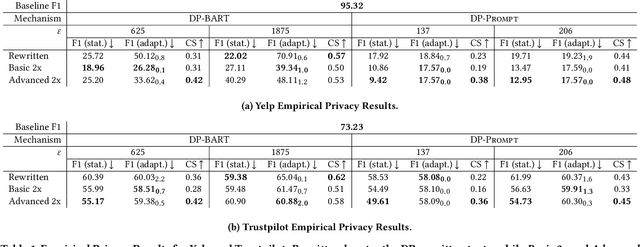


The study of Differential Privacy (DP) in Natural Language Processing often views the task of text privatization as a $\textit{rewriting}$ task, in which sensitive input texts are rewritten to hide explicit or implicit private information. In order to evaluate the privacy-preserving capabilities of a DP text rewriting mechanism, $\textit{empirical privacy}$ tests are frequently employed. In these tests, an adversary is modeled, who aims to infer sensitive information (e.g., gender) about the author behind a (privatized) text. Looking to improve the empirical protections provided by DP rewriting methods, we propose a simple post-processing method based on the goal of aligning rewritten texts with their original counterparts, where DP rewritten texts are rewritten $\textit{again}$. Our results show that such an approach not only produces outputs that are more semantically reminiscent of the original inputs, but also texts which score on average better in empirical privacy evaluations. Therefore, our approach raises the bar for DP rewriting methods in their empirical privacy evaluations, providing an extra layer of protection against malicious adversaries.