 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Triples for Private Document Generation with Local Differential Privacy Guarantees
Aug 28, 2025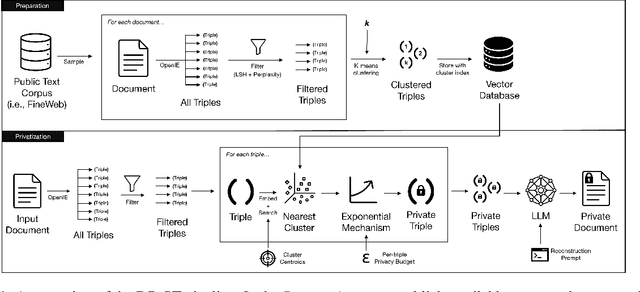
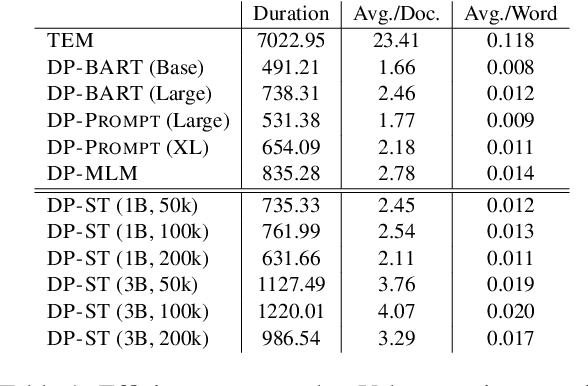
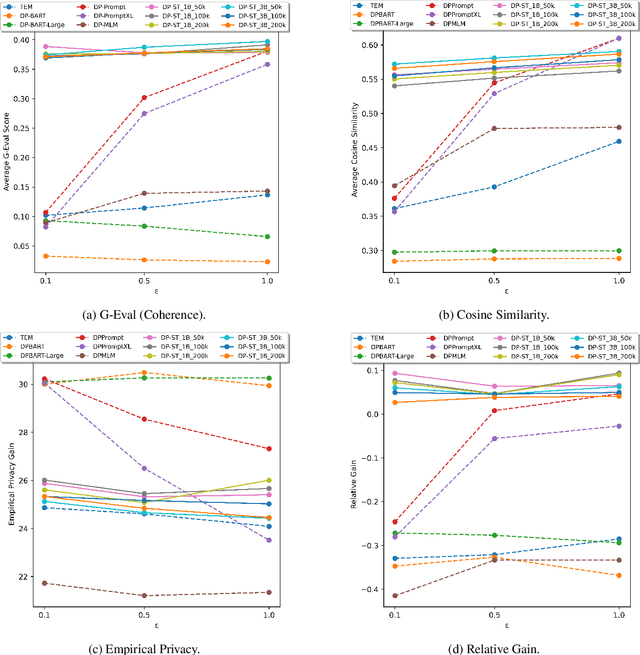

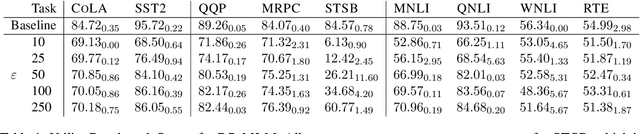
Many works at the intersection of Differential Privacy (DP) in Natural Language Processing aim to protect privacy by transforming texts under DP guarantees. This can be performed in a variety of ways, from word perturbations to full document rewriting, and most often under local DP. Here, an input text must be made indistinguishable from any other potential text, within some bound governed by the privacy parameter $\varepsilon$. Such a guarantee is quite demanding, and recent works show that privatizing texts under local DP can only be done reasonably under very high $\varepsilon$ values. Addressing this challenge, we introduce DP-ST, which leverages semantic triples for neighborhood-aware private document generation under local DP guarantees. Through the evaluation of our method, we demonstrate the effectiveness of the divide-and-conquer paradigm, particularly when limiting the DP notion (and privacy guarantees) to that of a privatization neighborhood. When combined with LLM post-processing, our method allows for coherent text generation even at lower $\varepsilon$ values, while still balancing privacy and utility. These findings highlight the importance of coherence in achieving balanced privatization outputs at reasonable $\varepsilon$ levels.
On the Impact of Noise in Differentially Private Text Rewriting
Jan 31, 2025



The field of text privatization often leverages the notion of $\textit{Differential Privacy}$ (DP) to provide formal guarantees in the rewriting or obfuscation of sensitive textual data. A common and nearly ubiquitous form of DP application necessitates the addition of calibrated noise to vector representations of text, either at the data- or model-level, which is governed by the privacy parameter $\varepsilon$. However, noise addition almost undoubtedly leads to considerable utility loss, thereby highlighting one major drawback of DP in NLP. In this work, we introduce a new sentence infilling privatization technique, and we use this method to explore the effect of noise in DP text rewriting. We empirically demonstrate that non-DP privatization techniques excel in utility preservation and can find an acceptable empirical privacy-utility trade-off, yet cannot outperform DP methods in empirical privacy protections. Our results highlight the significant impact of noise in current DP rewriting mechanisms, leading to a discussion of the merits and challenges of DP in NLP, as well as the opportunities that non-DP methods present.
A Collocation-based Method for Addressing Challenges in Word-level Metric Differential Privacy
Jun 30, 2024Applications of Differential Privacy (DP) in NLP must distinguish between the syntactic level on which a proposed mechanism operates, often taking the form of $\textit{word-level}$ or $\textit{document-level}$ privatization. Recently, several word-level $\textit{Metric}$ Differential Privacy approaches have been proposed, which rely on this generalized DP notion for operating in word embedding spaces. These approaches, however, often fail to produce semantically coherent textual outputs, and their application at the sentence- or document-level is only possible by a basic composition of word perturbations. In this work, we strive to address these challenges by operating $\textit{between}$ the word and sentence levels, namely with $\textit{collocations}$. By perturbing n-grams rather than single words, we devise a method where composed privatized outputs have higher semantic coherence and variable length. This is accomplished by constructing an embedding model based on frequently occurring word groups, in which unigram words co-exist with bi- and trigram collocations. We evaluate our method in utility and privacy tests, which make a clear case for tokenization strategies beyond the word level.
DP-MLM: Differentially Private Text Rewriting Using Masked Language Models
Jun 30, 2024
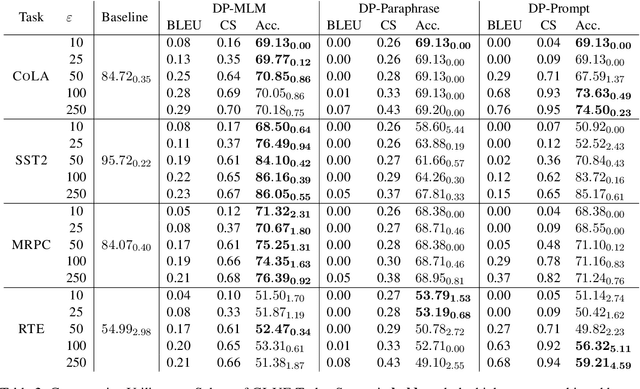
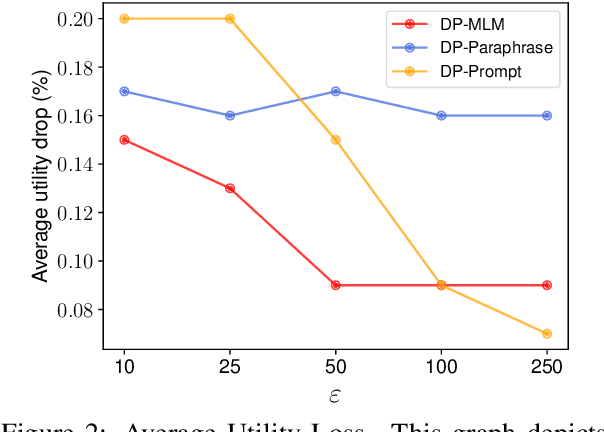
The task of text privatization using Differential Privacy has recently taken the form of $\textit{text rewriting}$, in which an input text is obfuscated via the use of generative (large) language models. While these methods have shown promising results in the ability to preserve privacy, these methods rely on autoregressive models which lack a mechanism to contextualize the private rewriting process. In response to this, we propose $\textbf{DP-MLM}$, a new method for differentially private text rewriting based on leveraging masked language models (MLMs) to rewrite text in a semantically similar $\textit{and}$ obfuscated manner. We accomplish this with a simple contextualization technique, whereby we rewrite a text one token at a time. We find that utilizing encoder-only MLMs provides better utility preservation at lower $\varepsilon$ levels, as compared to previous methods relying on larger models with a decoder. In addition, MLMs allow for greater customization of the rewriting mechanism, as opposed to generative approaches. We make the code for $\textbf{DP-MLM}$ public and reusable, found at https://github.com/sjmeis/DPMLM .
1-Diffractor: Efficient and Utility-Preserving Text Obfuscation Leveraging Word-Level Metric Differential Privacy
May 02, 2024The study of privacy-preserving Natural Language Processing (NLP) has gained rising attention in recent years. One promising avenue studies the integration of Differential Privacy in NLP, which has brought about innovative methods in a variety of application settings. Of particular note are $\textit{word-level Metric Local Differential Privacy (MLDP)}$ mechanisms, which work to obfuscate potentially sensitive input text by performing word-by-word $\textit{perturbations}$. Although these methods have shown promising results in empirical tests, there are two major drawbacks: (1) the inevitable loss of utility due to addition of noise, and (2) the computational expensiveness of running these mechanisms on high-dimensional word embeddings. In this work, we aim to address these challenges by proposing $\texttt{1-Diffractor}$, a new mechanism that boasts high speedups in comparison to previous mechanisms, while still demonstrating strong utility- and privacy-preserving capabilities. We evaluate $\texttt{1-Diffractor}$ for utility on several NLP tasks, for theoretical and task-based privacy, and for efficiency in terms of speed and memory. $\texttt{1-Diffractor}$ shows significant improvements in efficiency, while still maintaining competitive utility and privacy scores across all conducted comparative tests against previous MLDP mechanisms. Our code is made available at: https://github.com/sjmeis/Diffractor.
Privacy-Utility Trade-offs in Neural Networks for Medical Population Graphs: Insights from Differential Privacy and Graph Structure
Jul 13, 2023We initiate an empirical investigation into differentially private graph neural networks on population graphs from the medical domain by examining privacy-utility trade-offs at different privacy levels on both real-world and synthetic datasets and performing auditing through membership inference attacks. Our findings highlight the potential and the challenges of this specific DP application area. Moreover, we find evidence that the underlying graph structure constitutes a potential factor for larger performance gaps by showing a correlation between the degree of graph homophily and the accuracy of the trained model.