 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
SciLaD: A Large-Scale, Transparent, Reproducible Dataset for Natural Scientific Language Processing
Dec 12, 2025SciLaD is a novel, large-scale dataset of scientific language constructed entirely using open-source frameworks and publicly available data sources. It comprises a curated English split containing over 10 million scientific publications and a multilingual, unfiltered TEI XML split including more than 35 million publications. We also publish the extensible pipeline for generating SciLaD. The dataset construction and processing workflow demonstrates how open-source tools can enable large-scale, scientific data curation while maintaining high data quality. Finally, we pre-train a RoBERTa model on our dataset and evaluate it across a comprehensive set of benchmarks, achieving performance comparable to other scientific language models of similar size, validating the quality and utility of SciLaD. We publish the dataset and evaluation pipeline to promote reproducibility, transparency, and further research in natural scientific language processing and understanding including scholarly document processing.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Reward Modeling with Weak Supervision for Language Models
Oct 28, 2024Recent advancements in large language models (LLMs) have led to their increased application across various tasks, with reinforcement learning from human feedback (RLHF) being a crucial part of their training to align responses with user intentions. In the RLHF process, a reward model is trained using responses preferences determined by human labelers or AI systems, which then refines the LLM through reinforcement learning. This work introduces weak supervision as a strategy to extend RLHF datasets and enhance reward model performance. Weak supervision employs noisy or imprecise data labeling, reducing reliance on expensive manually labeled data. By analyzing RLHF datasets to identify heuristics that correlate with response preference, we wrote simple labeling functions and then calibrated a label model to weakly annotate unlabeled data. Our evaluation show that while weak supervision significantly benefits smaller datasets by improving reward model performance, its effectiveness decreases with larger, originally labeled datasets. Additionally, using an LLM to generate and then weakly label responses offers a promising method for extending preference data.
Data Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Symmetric Dot-Product Attention for Efficient Training of BERT Language Models
Jun 10, 2024



Initially introduced as a machine translation model, the Transformer architecture has now become the foundation for modern deep learning architecture, with applications in a wide range of fields, from computer vision to natural language processing. Nowadays, to tackle increasingly more complex tasks, Transformer-based models are stretched to enormous sizes, requiring increasingly larger training datasets, and unsustainable amount of compute resources. The ubiquitous nature of the Transformer and its core component, the attention mechanism, are thus prime targets for efficiency research. In this work, we propose an alternative compatibility function for the self-attention mechanism introduced by the Transformer architecture. This compatibility function exploits an overlap in the learned representation of the traditional scaled dot-product attention, leading to a symmetric with pairwise coefficient dot-product attention. When applied to the pre-training of BERT-like models, this new symmetric attention mechanism reaches a score of 79.36 on the GLUE benchmark against 78.74 for the traditional implementation, leads to a reduction of 6% in the number of trainable parameters, and reduces the number of training steps required before convergence by half.
Investigating Gender Bias in Turkish Language Models
Apr 17, 2024


Language models are trained mostly on Web data, which often contains social stereotypes and biases that the models can inherit. This has potentially negative consequences, as models can amplify these biases in downstream tasks or applications. However, prior research has primarily focused on the English language, especially in the context of gender bias. In particular, grammatically gender-neutral languages such as Turkish are underexplored despite representing different linguistic properties to language models with possibly different effects on biases. In this paper, we fill this research gap and investigate the significance of gender bias in Turkish language models. We build upon existing bias evaluation frameworks and extend them to the Turkish language by translating existing English tests and creating new ones designed to measure gender bias in the context of T\"urkiye. Specifically, we also evaluate Turkish language models for their embedded ethnic bias toward Kurdish people. Based on the experimental results, we attribute possible biases to different model characteristics such as the model size, their multilingualism, and the training corpora. We make the Turkish gender bias dataset publicly available.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023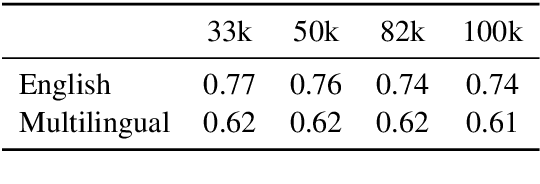
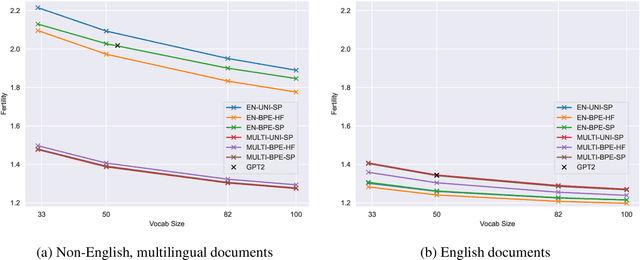
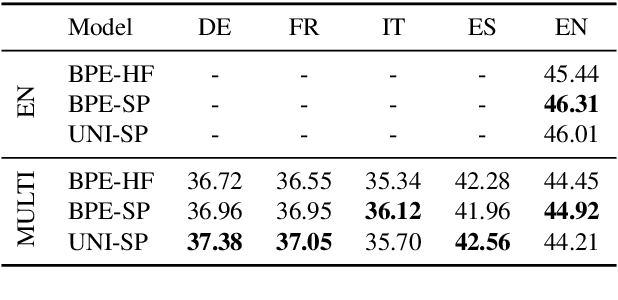
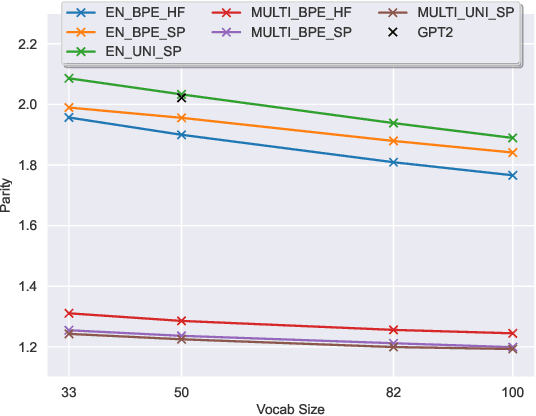
The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.
AspectCSE: Sentence Embeddings for Aspect-based Semantic Textual Similarity using Contrastive Learning and Structured Knowledge
Jul 22, 2023Generic sentence embeddings provide a coarse-grained approximation of semantic textual similarity but ignore specific aspects that make texts similar. Conversely, aspect-based sentence embeddings provide similarities between texts based on certain predefined aspects. Thus, similarity predictions of texts are more targeted to specific requirements and more easily explainable. In this paper, we present AspectCSE, an approach for aspect-based contrastive learning of sentence embeddings. Results indicate that AspectCSE achieves an average improvement of 3.97% on information retrieval tasks across multiple aspects compared to the previous best results. We also propose using Wikidata knowledge graph properties to train models of multi-aspect sentence embeddings in which multiple specific aspects are simultaneously considered during similarity predictions. We demonstrate that multi-aspect embeddings outperform single-aspect embeddings on aspect-specific information retrieval tasks. Finally, we examine the aspect-based sentence embedding space and demonstrate that embeddings of semantically similar aspect labels are often close, even without explicit similarity training between different aspect labels.
Efficient Language Model Training through Cross-Lingual and Progressive Transfer Learning
Jan 23, 2023
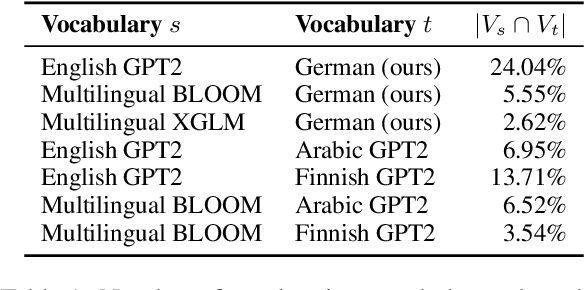
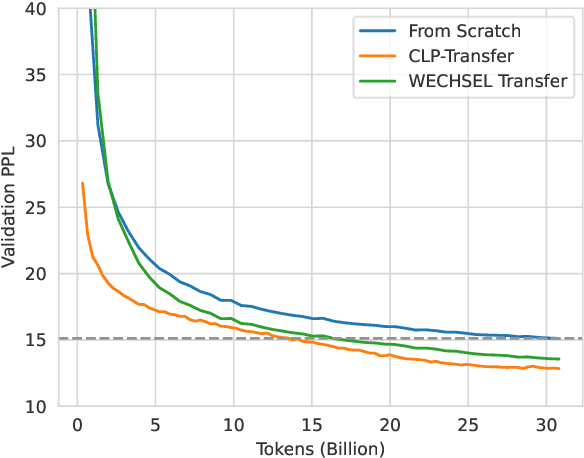
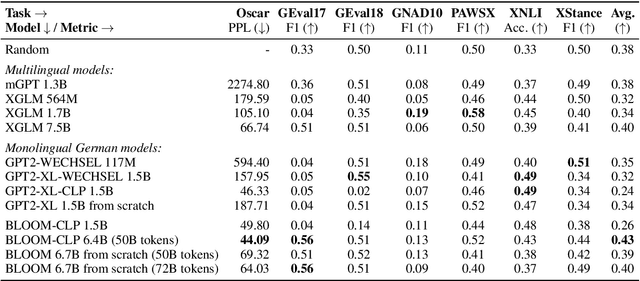
Most Transformer language models are primarily pretrained on English text, limiting their use for other languages. As the model sizes grow, the performance gap between English and other languages with fewer compute and data resources increases even further. Consequently, more resource-efficient training methods are needed to bridge the gap for languages with fewer resources available. To address this problem, we introduce a cross-lingual and progressive transfer learning approach, called CLP-Transfer, that transfers models from a source language, for which pretrained models are publicly available, like English, to a new target language. As opposed to prior work, which focused on the cross-lingual transfer between two languages, we extend the transfer to the model size. Given a pretrained model in a source language, we aim for a same-sized model in a target language. Instead of training a model from scratch, we exploit a smaller model that is in the target language but requires much fewer resources. Both small and source models are then used to initialize the token embeddings of the larger model based on the overlapping vocabulary of the source and target language. All remaining weights are reused from the model in the source language. This approach outperforms the sole cross-lingual transfer and can save up to 80% of the training steps compared to the random initialization.