 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Document Embeddings for Aspect-based Similarity of Research Papers
Mar 28, 2022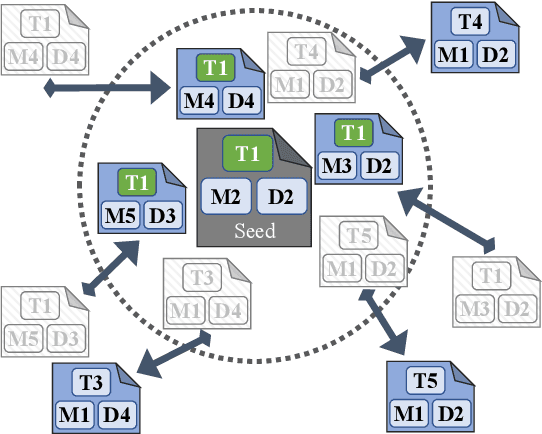
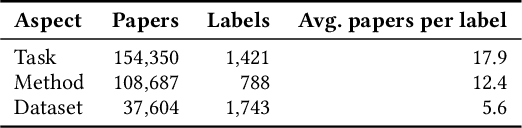
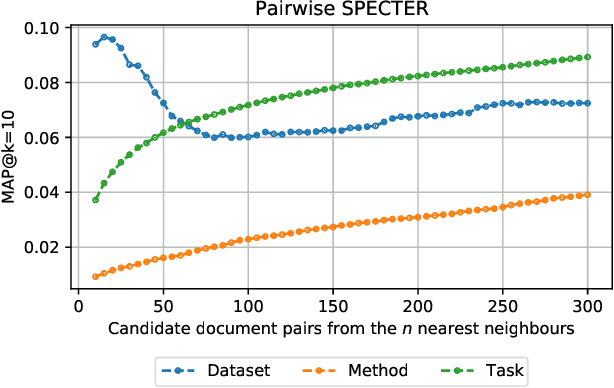
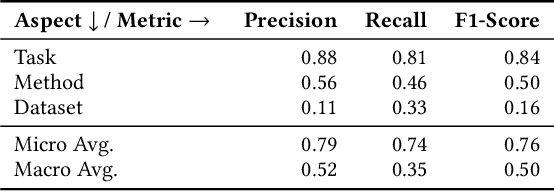
Document embeddings and similarity measures underpin content-based recommender systems, whereby a document is commonly represented as a single generic embedding. However, similarity computed on single vector representations provides only one perspective on document similarity that ignores which aspects make two documents alike. To address this limitation, aspect-based similarity measures have been developed using document segmentation or pairwise multi-class document classification. While segmentation harms the document coherence, the pairwise classification approach scales poorly to large scale corpora. In this paper, we treat aspect-based similarity as a classical vector similarity problem in aspect-specific embedding spaces. We represent a document not as a single generic embedding but as multiple specialized embeddings. Our approach avoids document segmentation and scales linearly w.r.t.the corpus size. In an empirical study, we use the Papers with Code corpus containing 157,606 research papers and consider the task, method, and dataset of the respective research papers as their aspects. We compare and analyze three generic document embeddings, six specialized document embeddings and a pairwise classification baseline in the context of research paper recommendations. As generic document embeddings, we consider FastText, SciBERT, and SPECTER. To compute the specialized document embeddings, we compare three alternative methods inspired by retrofitting, fine-tuning, and Siamese networks. In our experiments, Siamese SciBERT achieved the highest scores. Additional analyses indicate an implicit bias of the generic document embeddings towards the dataset aspect and against the method aspect of each research paper. Our approach of aspect-based document embeddings mitigates potential risks arising from implicit biases by making them explicit.
Scaling R-GCN Training with Graph Summarization
Mar 21, 2022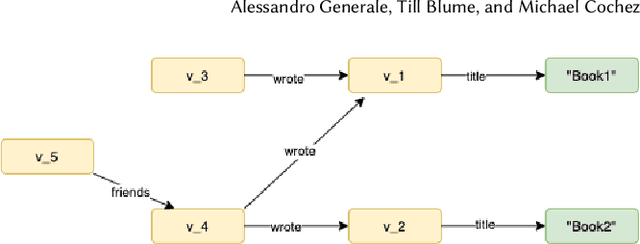


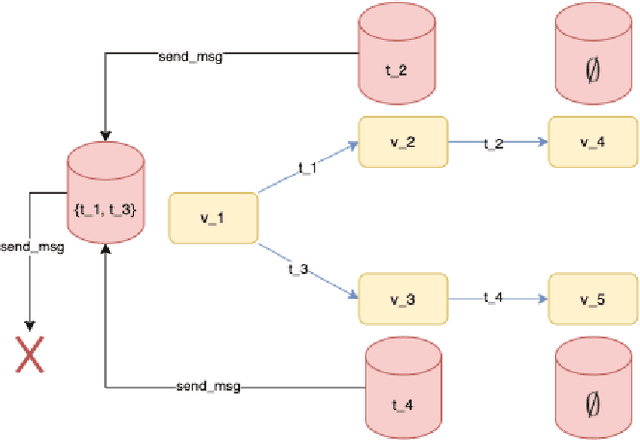
Training of Relational Graph Convolutional Networks (R-GCN) is a memory intense task. The amount of gradient information that needs to be stored during training for real-world graphs is often too large for the amount of memory available on most GPUs. In this work, we experiment with the use of graph summarization techniques to compress the graph and hence reduce the amount of memory needed. After training the R-GCN on the graph summary, we transfer the weights back to the original graph and attempt to perform inference on it. We obtain reasonable results on the AIFB, MUTAG and AM datasets. Our experiments show that training on the graph summary can yield a comparable or higher accuracy to training on the original graphs.Furthermore, if we take the time to compute the summary out of the equation, we observe that the smaller graph representations obtained with graph summarization methods reduces the computational overhead. However, further experiments are needed to evaluate additional graph summary models and whether our findings also holds true for very large graphs.
Aspect-based Document Similarity for Research Papers
Oct 13, 2020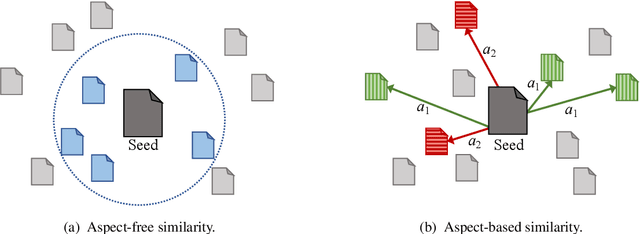
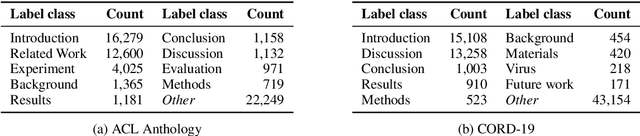
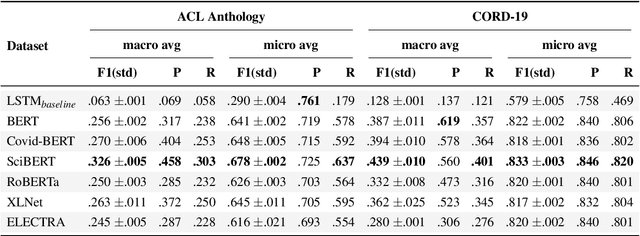
Traditional document similarity measures provide a coarse-grained distinction between similar and dissimilar documents. Typically, they do not consider in what aspects two documents are similar. This limits the granularity of applications like recommender systems that rely on document similarity. In this paper, we extend similarity with aspect information by performing a pairwise document classification task. We evaluate our aspect-based document similarity for research papers. Paper citations indicate the aspect-based similarity, i.e., the section title in which a citation occurs acts as a label for the pair of citing and cited paper. We apply a series of Transformer models such as RoBERTa, ELECTRA, XLNet, and BERT variations and compare them to an LSTM baseline. We perform our experiments on two newly constructed datasets of 172,073 research paper pairs from the ACL Anthology and CORD-19 corpus. Our results show SciBERT as the best performing system. A qualitative examination validates our quantitative results. Our findings motivate future research of aspect-based document similarity and the development of a recommender system based on the evaluated techniques. We make our datasets, code, and trained models publicly available.
Towards an Open Platform for Legal Information
May 27, 2020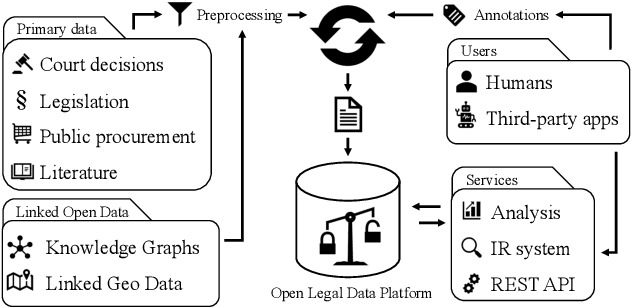

Recent advances in the area of legal information systems have led to a variety of applications that promise support in processing and accessing legal documents. Unfortunately, these applications have various limitations, e.g., regarding scope or extensibility. Furthermore, we do not observe a trend towards open access in digital libraries in the legal domain as we observe in other domains, e.g., economics of computer science. To improve open access in the legal domain, we present our approach for an open source platform to transparently process and access Legal Open Data. This enables the sustainable development of legal applications by offering a single technology stack. Moreover, the approach facilitates the development and deployment of new technologies. As proof of concept, we implemented six technologies and generated metadata for more than 250,000 German laws and court decisions. Thus, we can provide users of our platform not only access to legal documents, but also the contained information.