 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateCheck 2026: Scientific Fact-Checking and Disinformation Narrative Classification of Climate-related Claims
Mar 27, 2026Automatically verifying climate-related claims against scientific literature is a challenging task, complicated by the specialised nature of scholarly evidence and the diversity of rhetorical strategies underlying climate disinformation. ClimateCheck 2026 is the second iteration of a shared task addressing this challenge, expanding on the 2025 edition with tripled training data and a new disinformation narrative classification task. Running from January to February 2026 on the CodaBench platform, the competition attracted 20 registered participants and 8 leaderboard submissions, with systems combining dense retrieval pipelines, cross-encoder ensembles, and large language models with structured hierarchical reasoning. In addition to standard evaluation metrics (Recall@K and Binary Preference), we adapt an automated framework to assess retrieval quality under incomplete annotations, exposing systematic biases in how conventional metrics rank systems. A cross-task analysis further reveals that not all climate disinformation is equally verifiable, potentially implicating how future fact-checking systems should be designed.
SciLaD: A Large-Scale, Transparent, Reproducible Dataset for Natural Scientific Language Processing
Dec 12, 2025SciLaD is a novel, large-scale dataset of scientific language constructed entirely using open-source frameworks and publicly available data sources. It comprises a curated English split containing over 10 million scientific publications and a multilingual, unfiltered TEI XML split including more than 35 million publications. We also publish the extensible pipeline for generating SciLaD. The dataset construction and processing workflow demonstrates how open-source tools can enable large-scale, scientific data curation while maintaining high data quality. Finally, we pre-train a RoBERTa model on our dataset and evaluate it across a comprehensive set of benchmarks, achieving performance comparable to other scientific language models of similar size, validating the quality and utility of SciLaD. We publish the dataset and evaluation pipeline to promote reproducibility, transparency, and further research in natural scientific language processing and understanding including scholarly document processing.
NFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
How desirable is alignment between LLMs and linguistically diverse human users?
Feb 18, 2025We discuss how desirable it is that Large Language Models (LLMs) be able to adapt or align their language behavior with users who may be diverse in their language use. User diversity may come about among others due to i) age differences; ii) gender characteristics, and/or iii) multilingual experience, and associated differences in language processing and use. We consider potential consequences for usability, communication, and LLM development.
Multilingual European Language Models: Benchmarking Approaches and Challenges
Feb 18, 2025The breakthrough of generative large language models (LLMs) that can solve different tasks through chat interaction has led to a significant increase in the use of general benchmarks to assess the quality or performance of these models beyond individual applications. There is also a need for better methods to evaluate and also to compare models due to the ever increasing number of new models published. However, most of the established benchmarks revolve around the English language. This paper analyses the benefits and limitations of current evaluation datasets, focusing on multilingual European benchmarks. We analyse seven multilingual benchmarks and identify four major challenges. Furthermore, we discuss potential solutions to enhance translation quality and mitigate cultural biases, including human-in-the-loop verification and iterative translation ranking. Our analysis highlights the need for culturally aware and rigorously validated benchmarks to assess the reasoning and question-answering capabilities of multilingual LLMs accurately.
Are Multilingual Language Models an Off-ramp for Under-resourced Languages? Will we arrive at Digital Language Equality in Europe in 2030?
Feb 18, 2025
Large language models (LLMs) demonstrate unprecedented capabilities and define the state of the art for almost all natural language processing (NLP) tasks and also for essentially all Language Technology (LT) applications. LLMs can only be trained for languages for which a sufficient amount of pre-training data is available, effectively excluding many languages that are typically characterised as under-resourced. However, there is both circumstantial and empirical evidence that multilingual LLMs, which have been trained using data sets that cover multiple languages (including under-resourced ones), do exhibit strong capabilities for some of these under-resourced languages. Eventually, this approach may have the potential to be a technological off-ramp for those under-resourced languages for which "native" LLMs, and LLM-based technologies, cannot be developed due to a lack of training data. This paper, which concentrates on European languages, examines this idea, analyses the current situation in terms of technology support and summarises related work. The article concludes by focusing on the key open questions that need to be answered for the approach to be put into practice in a systematic way.
Entity Linking using LLMs for Automated Product Carbon Footprint Estimation
Feb 11, 2025
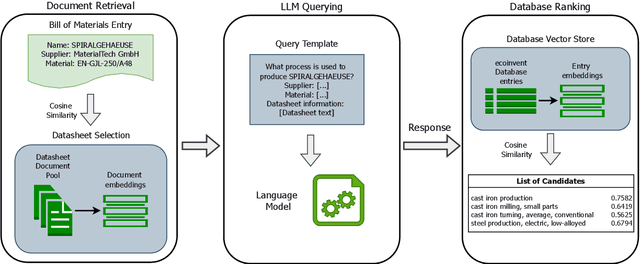

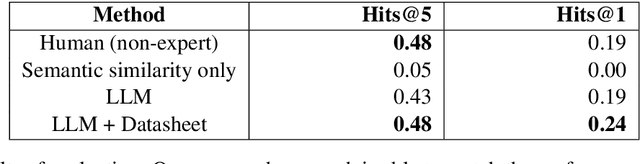
Growing concerns about climate change and sustainability are driving manufacturers to take significant steps toward reducing their carbon footprints. For these manufacturers, a first step towards this goal is to identify the environmental impact of the individual components of their products. We propose a system leveraging large language models (LLMs) to automatically map components from manufacturer Bills of Materials (BOMs) to Life Cycle Assessment (LCA) database entries by using LLMs to expand on available component information. Our approach reduces the need for manual data processing, paving the way for more accessible sustainability practices.
Reward Modeling with Weak Supervision for Language Models
Oct 28, 2024Recent advancements in large language models (LLMs) have led to their increased application across various tasks, with reinforcement learning from human feedback (RLHF) being a crucial part of their training to align responses with user intentions. In the RLHF process, a reward model is trained using responses preferences determined by human labelers or AI systems, which then refines the LLM through reinforcement learning. This work introduces weak supervision as a strategy to extend RLHF datasets and enhance reward model performance. Weak supervision employs noisy or imprecise data labeling, reducing reliance on expensive manually labeled data. By analyzing RLHF datasets to identify heuristics that correlate with response preference, we wrote simple labeling functions and then calibrated a label model to weakly annotate unlabeled data. Our evaluation show that while weak supervision significantly benefits smaller datasets by improving reward model performance, its effectiveness decreases with larger, originally labeled datasets. Additionally, using an LLM to generate and then weakly label responses offers a promising method for extending preference data.
Data Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Weighted Cross-entropy for Low-Resource Languages in Multilingual Speech Recognition
Sep 25, 2024

This paper addresses the challenge of integrating low-resource languages into multilingual automatic speech recognition (ASR) systems. We introduce a novel application of weighted cross-entropy, typically used for unbalanced datasets, to facilitate the integration of low-resource languages into pre-trained multilingual ASR models within the context of continual multilingual learning. We fine-tune the Whisper multilingual ASR model on five high-resource languages and one low-resource language, employing language-weighted dynamic cross-entropy and data augmentation. The results show a remarkable 6.69% word error rate (WER) reduction for the low-resource language compared to the fine-tuned model without applying our approach, and a 48.86% WER reduction compared to the original Whisper model. In addition, our approach yields an average WER reduction of 3.29% across the six languages, showing no degradation for the high-resource languages.
* 5 pages, 1 figure. Presented at Interspeech 2024