 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Loops and Memory in Transformers: Think Harder or Know More?
Mar 11, 2026Chain-of-thought (CoT) prompting enables reasoning in language models but requires explicit verbalization of intermediate steps. Looped transformers offer an alternative by iteratively refining representations within hidden states. This parameter efficiency comes at a cost, as looped models lack the storage capacity of deeper models which use unique weights per layer. In this work, we investigate transformer models that feature both adaptive per-layer looping, where each transformer block learns to iterate its hidden state via a learned halting mechanism, and gated memory banks, that provide additional learned storage. We find that looping primarily benefits mathematical reasoning, while memory banks help recover performance on commonsense tasks compared to parameter and FLOP matched models. Combining both mechanisms yields a model that outperforms an iso-FLOP baseline, with three times the number of layers, across math benchmarks. Analysis of model internals reveals layer specialization: early layers learn to loop minimally and access memory sparingly, while later layers do both more heavily.
Is continuous CoT better suited for multi-lingual reasoning?
Mar 09, 2026We investigate whether performing reasoning in a continuous latent space leads to more robust multilingual capabilities. We compare Continuous Chain-of-Thought (using the CODI framework) against standard supervised fine-tuning across five typologically diverse languages: English, Chinese, German, French, and Urdu. Our experiments on GSM8k and CommonsenseQA demonstrate that continuous reasoning significantly outperforms explicit reasoning on low-resource languages, particularly in zero-shot settings where the target language was not seen during training. Additionally, this approach achieves extreme efficiency, compressing reasoning traces by approximately $29\times$ to $50\times$. These findings indicate that continuous latent representations naturally exhibit greater language invariance, offering a scalable solution for cross-lingual reasoning.
Modalities, a PyTorch-native Framework For Large-scale LLM Training and Research
Feb 09, 2026Today's LLM (pre-) training and research workflows typically allocate a significant amount of compute to large-scale ablation studies. Despite the substantial compute costs of these ablations, existing open-source frameworks provide limited tooling for these experiments, often forcing researchers to write their own wrappers and scripts. We propose Modalities, an end-to-end PyTorch-native framework that integrates data-driven LLM research with large-scale model training from two angles. Firstly, by integrating state-of-the-art parallelization strategies, it enables both efficient pretraining and systematic ablations at trillion-token and billion-parameter scale. Secondly, Modalities adopts modular design with declarative, self-contained configuration, enabling reproducibility and extensibility levels that are difficult to achieve out-of-the-box with existing LLM training frameworks.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025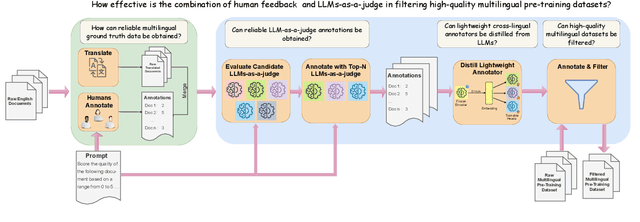
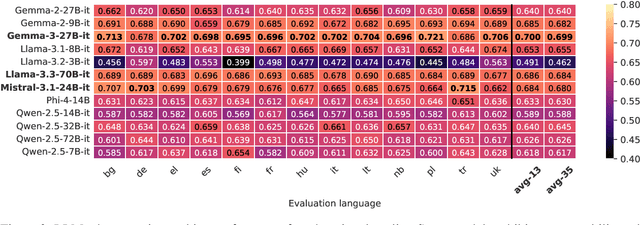

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
Towards Multilingual LLM Evaluation for European Languages
Oct 17, 2024



The rise of Large Language Models (LLMs) has revolutionized natural language processing across numerous languages and tasks. However, evaluating LLM performance in a consistent and meaningful way across multiple European languages remains challenging, especially due to the scarcity of language-parallel multilingual benchmarks. We introduce a multilingual evaluation approach tailored for European languages. We employ translated versions of five widely-used benchmarks to assess the capabilities of 40 LLMs across 21 European languages. Our contributions include examining the effectiveness of translated benchmarks, assessing the impact of different translation services, and offering a multilingual evaluation framework for LLMs that includes newly created datasets: EU20-MMLU, EU20-HellaSwag, EU20-ARC, EU20-TruthfulQA, and EU20-GSM8K. The benchmarks and results are made publicly available to encourage further research in multilingual LLM evaluation.
Data Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Towards Cross-Lingual LLM Evaluation for European Languages
Oct 11, 2024The rise of Large Language Models (LLMs) has revolutionized natural language processing across numerous languages and tasks. However, evaluating LLM performance in a consistent and meaningful way across multiple European languages remains challenging, especially due to the scarcity of multilingual benchmarks. We introduce a cross-lingual evaluation approach tailored for European languages. We employ translated versions of five widely-used benchmarks to assess the capabilities of 40 LLMs across 21 European languages. Our contributions include examining the effectiveness of translated benchmarks, assessing the impact of different translation services, and offering a multilingual evaluation framework for LLMs that includes newly created datasets: EU20-MMLU, EU20-HellaSwag, EU20-ARC, EU20-TruthfulQA, and EU20-GSM8K. The benchmarks and results are made publicly available to encourage further research in multilingual LLM evaluation.
Do Multilingual Large Language Models Mitigate Stereotype Bias?
Jul 09, 2024



While preliminary findings indicate that multilingual LLMs exhibit reduced bias compared to monolingual ones, a comprehensive understanding of the effect of multilingual training on bias mitigation, is lacking. This study addresses this gap by systematically training six LLMs of identical size (2.6B parameters) and architecture: five monolingual models (English, German, French, Italian, and Spanish) and one multilingual model trained on an equal distribution of data across these languages, all using publicly available data. To ensure robust evaluation, standard bias benchmarks were automatically translated into the five target languages and verified for both translation quality and bias preservation by human annotators. Our results consistently demonstrate that multilingual training effectively mitigates bias. Moreover, we observe that multilingual models achieve not only lower bias but also superior prediction accuracy when compared to monolingual models with the same amount of training data, model architecture, and size.
Investigating Multilingual Instruction-Tuning: Do Polyglot Models Demand for Multilingual Instructions?
Feb 21, 2024The adaption of multilingual pre-trained Large Language Models (LLMs) into eloquent and helpful assistants is essential to facilitate their use across different language regions. In that spirit, we are the first to conduct an extensive study of the performance of multilingual models on parallel, multi-turn instruction-tuning benchmarks across a selection of the most-spoken Indo-European languages. We systematically examine the effects of language and instruction dataset size on a mid-sized, multilingual LLM by instruction-tuning it on parallel instruction-tuning datasets. Our results demonstrate that instruction-tuning on parallel instead of monolingual corpora benefits cross-lingual instruction following capabilities by up to 4.6%. Furthermore, we show that the Superficial Alignment Hypothesis does not hold in general, as the investigated multilingual 7B parameter model presents a counter-example requiring large-scale instruction-tuning datasets. Finally, we conduct a human annotation study to understand the alignment between human-based and GPT-4-based evaluation within multilingual chat scenarios.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023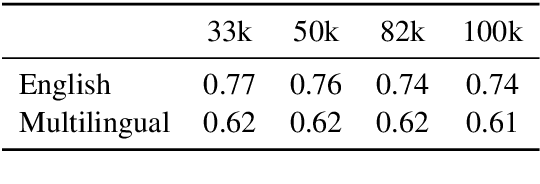
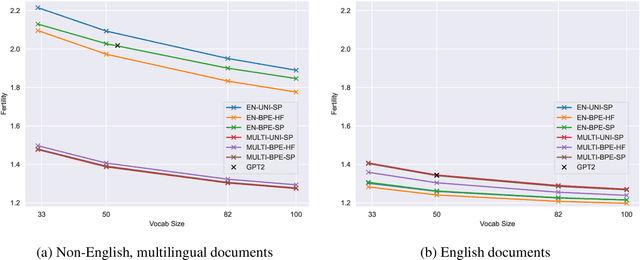
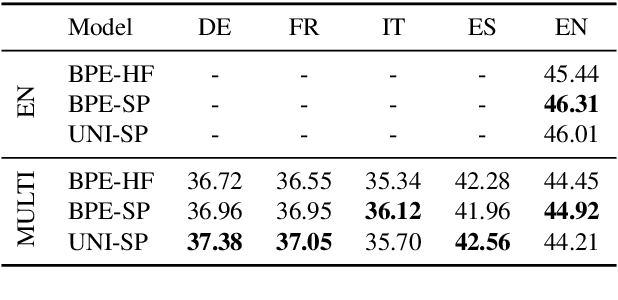
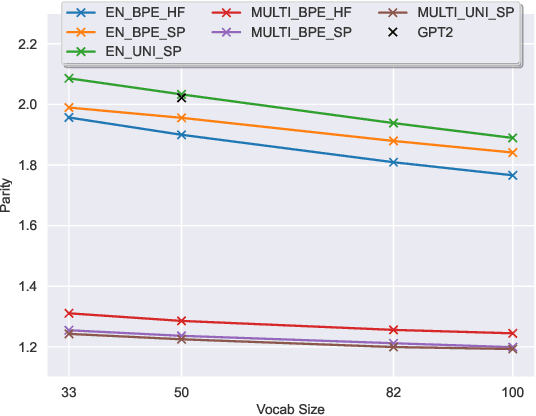
The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.