 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFusion: Vision-Language Model as Unified Encoder in Image Generation
Oct 14, 2025
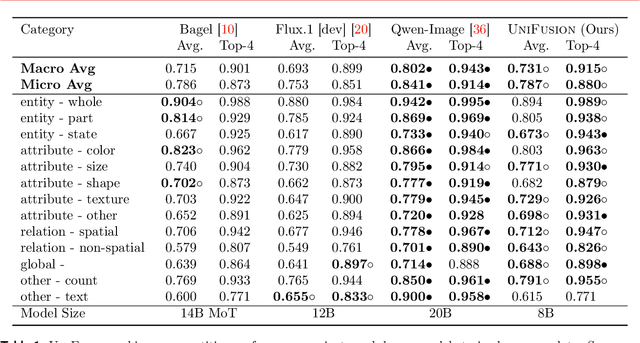

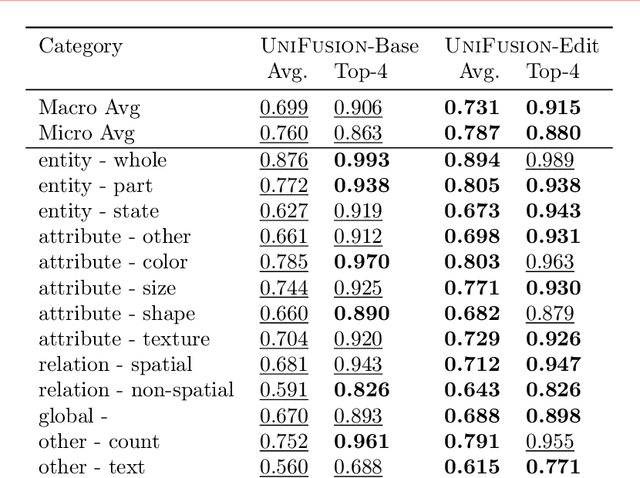
Although recent advances in visual generation have been remarkable, most existing architectures still depend on distinct encoders for images and text. This separation constrains diffusion models' ability to perform cross-modal reasoning and knowledge transfer. Prior attempts to bridge this gap often use the last layer information from VLM, employ multiple visual encoders, or train large unified models jointly for text and image generation, which demands substantial computational resources and large-scale data, limiting its accessibility.We present UniFusion, a diffusion-based generative model conditioned on a frozen large vision-language model (VLM) that serves as a unified multimodal encoder. At the core of UniFusion is the Layerwise Attention Pooling (LAP) mechanism that extracts both high level semantics and low level details from text and visual tokens of a frozen VLM to condition a diffusion generative model. We demonstrate that LAP outperforms other shallow fusion architectures on text-image alignment for generation and faithful transfer of visual information from VLM to the diffusion model which is key for editing. We propose VLM-Enabled Rewriting Injection with Flexibile Inference (VERIFI), which conditions a diffusion transformer (DiT) only on the text tokens generated by the VLM during in-model prompt rewriting. VERIFI combines the alignment of the conditioning distribution with the VLM's reasoning capabilities for increased capabilities and flexibility at inference. In addition, finetuning on editing task not only improves text-image alignment for generation, indicative of cross-modality knowledge transfer, but also exhibits tremendous generalization capabilities. Our model when trained on single image editing, zero-shot generalizes to multiple image references further motivating the unified encoder design of UniFusion.
CHRONOBERG: Capturing Language Evolution and Temporal Awareness in Foundation Models
Sep 26, 2025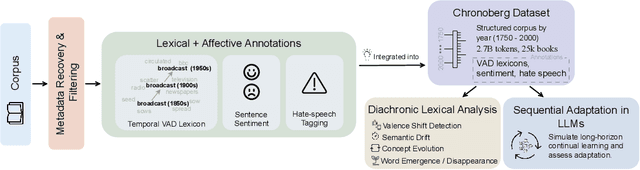



Large language models (LLMs) excel at operating at scale by leveraging social media and various data crawled from the web. Whereas existing corpora are diverse, their frequent lack of long-term temporal structure may however limit an LLM's ability to contextualize semantic and normative evolution of language and to capture diachronic variation. To support analysis and training for the latter, we introduce CHRONOBERG, a temporally structured corpus of English book texts spanning 250 years, curated from Project Gutenberg and enriched with a variety of temporal annotations. First, the edited nature of books enables us to quantify lexical semantic change through time-sensitive Valence-Arousal-Dominance (VAD) analysis and to construct historically calibrated affective lexicons to support temporally grounded interpretation. With the lexicons at hand, we demonstrate a need for modern LLM-based tools to better situate their detection of discriminatory language and contextualization of sentiment across various time-periods. In fact, we show how language models trained sequentially on CHRONOBERG struggle to encode diachronic shifts in meaning, emphasizing the need for temporally aware training and evaluation pipelines, and positioning CHRONOBERG as a scalable resource for the study of linguistic change and temporal generalization. Disclaimer: This paper includes language and display of samples that could be offensive to readers. Open Access: Chronoberg is available publicly on HuggingFace at ( https://huggingface.co/datasets/spaul25/Chronoberg). Code is available at (https://github.com/paulsubarna/Chronoberg).
Measuring and Guiding Monosemanticity
Jun 24, 2025There is growing interest in leveraging mechanistic interpretability and controllability to better understand and influence the internal dynamics of large language models (LLMs). However, current methods face fundamental challenges in reliably localizing and manipulating feature representations. Sparse Autoencoders (SAEs) have recently emerged as a promising direction for feature extraction at scale, yet they, too, are limited by incomplete feature isolation and unreliable monosemanticity. To systematically quantify these limitations, we introduce Feature Monosemanticity Score (FMS), a novel metric to quantify feature monosemanticity in latent representation. Building on these insights, we propose Guided Sparse Autoencoders (G-SAE), a method that conditions latent representations on labeled concepts during training. We demonstrate that reliable localization and disentanglement of target concepts within the latent space improve interpretability, detection of behavior, and control. Specifically, our evaluations on toxicity detection, writing style identification, and privacy attribute recognition show that G-SAE not only enhances monosemanticity but also enables more effective and fine-grained steering with less quality degradation. Our findings provide actionable guidelines for measuring and advancing mechanistic interpretability and control of LLMs.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025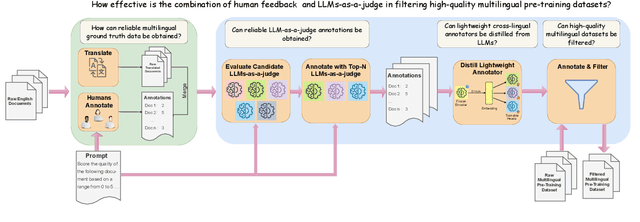
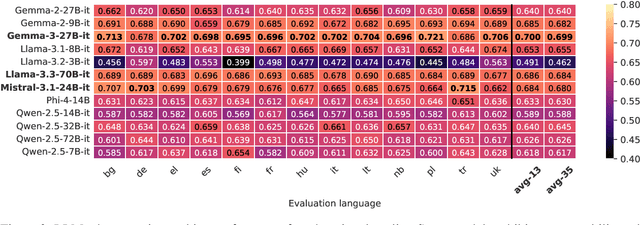

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
The Cake that is Intelligence and Who Gets to Bake it: An AI Analogy and its Implications for Participation
Feb 06, 2025In a widely popular analogy by Turing Award Laureate Yann LeCun, machine intelligence has been compared to cake - where unsupervised learning forms the base, supervised learning adds the icing, and reinforcement learning is the cherry on top. We expand this 'cake that is intelligence' analogy from a simple structural metaphor to the full life-cycle of AI systems, extending it to sourcing of ingredients (data), conception of recipes (instructions), the baking process (training), and the tasting and selling of the cake (evaluation and distribution). Leveraging our re-conceptualization, we describe each step's entailed social ramifications and how they are bounded by statistical assumptions within machine learning. Whereas these technical foundations and social impacts are deeply intertwined, they are often studied in isolation, creating barriers that restrict meaningful participation. Our re-conceptualization paves the way to bridge this gap by mapping where technical foundations interact with social outcomes, highlighting opportunities for cross-disciplinary dialogue. Finally, we conclude with actionable recommendations at each stage of the metaphorical AI cake's life-cycle, empowering prospective AI practitioners, users, and researchers, with increased awareness and ability to engage in broader AI discourse.
LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Gaps
Dec 19, 2024



Building safe Large Language Models (LLMs) across multiple languages is essential in ensuring both safe access and linguistic diversity. To this end, we introduce M-ALERT, a multilingual benchmark that evaluates the safety of LLMs in five languages: English, French, German, Italian, and Spanish. M-ALERT includes 15k high-quality prompts per language, totaling 75k, following the detailed ALERT taxonomy. Our extensive experiments on 10 state-of-the-art LLMs highlight the importance of language-specific safety analysis, revealing that models often exhibit significant inconsistencies in safety across languages and categories. For instance, Llama3.2 shows high unsafety in the category crime_tax for Italian but remains safe in other languages. Similar differences can be observed across all models. In contrast, certain categories, such as substance_cannabis and crime_propaganda, consistently trigger unsafe responses across models and languages. These findings underscore the need for robust multilingual safety practices in LLMs to ensure safe and responsible usage across diverse user communities.
SCAR: Sparse Conditioned Autoencoders for Concept Detection and Steering in LLMs
Nov 11, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities in generating human-like text, but their output may not be aligned with the user or even produce harmful content. This paper presents a novel approach to detect and steer concepts such as toxicity before generation. We introduce the Sparse Conditioned Autoencoder (SCAR), a single trained module that extends the otherwise untouched LLM. SCAR ensures full steerability, towards and away from concepts (e.g., toxic content), without compromising the quality of the model's text generation on standard evaluation benchmarks. We demonstrate the effective application of our approach through a variety of concepts, including toxicity, safety, and writing style alignment. As such, this work establishes a robust framework for controlling LLM generations, ensuring their ethical and safe deployment in real-world applications.
Core Tokensets for Data-efficient Sequential Training of Transformers
Oct 08, 2024



Deep networks are frequently tuned to novel tasks and continue learning from ongoing data streams. Such sequential training requires consolidation of new and past information, a challenge predominantly addressed by retaining the most important data points - formally known as coresets. Traditionally, these coresets consist of entire samples, such as images or sentences. However, recent transformer architectures operate on tokens, leading to the famous assertion that an image is worth 16x16 words. Intuitively, not all of these tokens are equally informative or memorable. Going beyond coresets, we thus propose to construct a deeper-level data summary on the level of tokens. Our respectively named core tokensets both select the most informative data points and leverage feature attribution to store only their most relevant features. We demonstrate that core tokensets yield significant performance retention in incremental image classification, open-ended visual question answering, and continual image captioning with significantly reduced memory. In fact, we empirically find that a core tokenset of 1\% of the data performs comparably to at least a twice as large and up to 10 times larger coreset.
T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings
Jun 27, 2024



Tokenizers are crucial for encoding information in Large Language Models, but their development has recently stagnated, and they contain inherent weaknesses. Major limitations include computational overhead, ineffective vocabulary use, and unnecessarily large embedding and head layers. Additionally, their performance is biased towards a reference corpus, leading to reduced effectiveness for underrepresented languages. To remedy these issues, we propose T-FREE, which directly embeds words through sparse activation patterns over character triplets, and does not require a reference corpus. T-FREE inherently exploits morphological similarities and allows for strong compression of embedding layers. In our exhaustive experimental evaluation, we achieve competitive downstream performance with a parameter reduction of more than 85% on these layers. Further, T-FREE shows significant improvements in cross-lingual transfer learning.
LLavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment
Jun 07, 2024



We introduce LlavaGuard, a family of VLM-based safeguard models, offering a versatile framework for evaluating the safety compliance of visual content. Specifically, we designed LlavaGuard for dataset annotation and generative model safeguarding. To this end, we collected and annotated a high-quality visual dataset incorporating a broad safety taxonomy, which we use to tune VLMs on context-aware safety risks. As a key innovation, LlavaGuard's new responses contain comprehensive information, including a safety rating, the violated safety categories, and an in-depth rationale. Further, our introduced customizable taxonomy categories enable the context-specific alignment of LlavaGuard to various scenarios. Our experiments highlight the capabilities of LlavaGuard in complex and real-world applications. We provide checkpoints ranging from 7B to 34B parameters demonstrating state-of-the-art performance, with even the smallest models outperforming baselines like GPT-4. We make our dataset and model weights publicly available and invite further research to address the diverse needs of communities and contexts.