 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Segment, Track, and Object Re-Localization from a Single 3D Model
Nov 12, 2025Accurate 6D pose estimation and tracking are fundamental capabilities for physical AI systems such as robots. However, existing approaches typically rely on a manually annotated segmentation mask of the target in the first frame, which is labor-intensive and leads to reduced performance when faced with occlusions or rapid movement. To address these limi- tations, we propose STORM (Segment, Track, and Object Re-localization from a single 3D Model), an open-source robust real-time 6D pose estimation system that requires no manual annotation. STORM employs a novel three-stage pipeline combining vision-language understanding with self-supervised feature matching: contextual object descriptions guide localization, self-cross-attention mechanisms identify candidate regions, and a segmentation model produces precise masks for accurate pose estimation. Another key innovation is our automatic re-registration mechanism that detects tracking failures through feature similarity monitoring and recovers from severe occlusions or rapid motion. STORM achieves state-of-the-art accuracy on challenging industrial datasets featuring multi-object occlusions, high-speed motion, and varying illumination, while operating at real-time speeds without additional training. This annotation-free approach significantly reduces deployment overhead, providing a practical solution for modern applications, such as flexible manufacturing and intelligent quality control.
BlendRL: A Framework for Merging Symbolic and Neural Policy Learning
Oct 15, 2024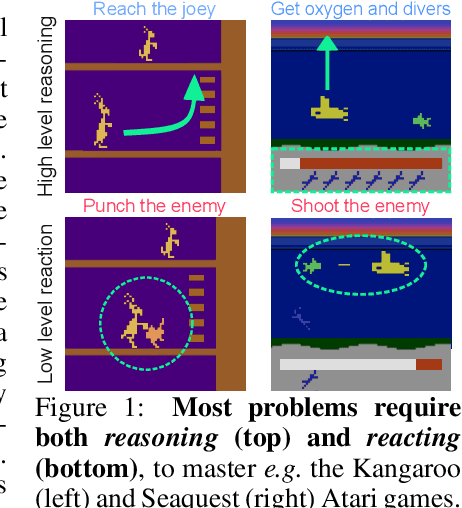
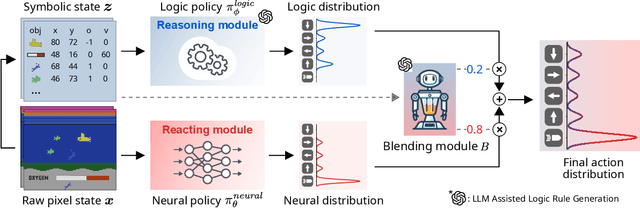

Humans can leverage both symbolic reasoning and intuitive reactions. In contrast, reinforcement learning policies are typically encoded in either opaque systems like neural networks or symbolic systems that rely on predefined symbols and rules. This disjointed approach severely limits the agents' capabilities, as they often lack either the flexible low-level reaction characteristic of neural agents or the interpretable reasoning of symbolic agents. To overcome this challenge, we introduce BlendRL, a neuro-symbolic RL framework that harmoniously integrates both paradigms within RL agents that use mixtures of both logic and neural policies. We empirically demonstrate that BlendRL agents outperform both neural and symbolic baselines in standard Atari environments, and showcase their robustness to environmental changes. Additionally, we analyze the interaction between neural and symbolic policies, illustrating how their hybrid use helps agents overcome each other's limitations.
EXPIL: Explanatory Predicate Invention for Learning in Games
Jun 10, 2024Reinforcement learning (RL) has proven to be a powerful tool for training agents that excel in various games. However, the black-box nature of neural network models often hinders our ability to understand the reasoning behind the agent's actions. Recent research has attempted to address this issue by using the guidance of pretrained neural agents to encode logic-based policies, allowing for interpretable decisions. A drawback of such approaches is the requirement of large amounts of predefined background knowledge in the form of predicates, limiting its applicability and scalability. In this work, we propose a novel approach, Explanatory Predicate Invention for Learning in Games (EXPIL), that identifies and extracts predicates from a pretrained neural agent, later used in the logic-based agents, reducing the dependency on predefined background knowledge. Our experimental evaluation on various games demonstrate the effectiveness of EXPIL in achieving explainable behavior in logic agents while requiring less background knowledge.
DeiSAM: Segment Anything with Deictic Prompting
Feb 21, 2024
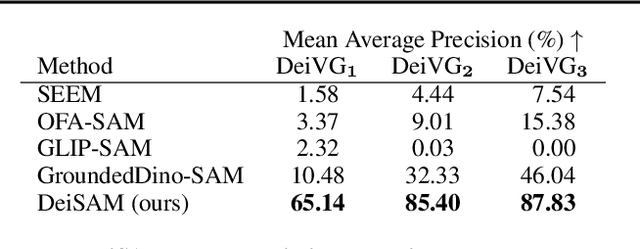


Large-scale, pre-trained neural networks have demonstrated strong capabilities in various tasks, including zero-shot image segmentation. To identify concrete objects in complex scenes, humans instinctively rely on deictic descriptions in natural language, i.e., referring to something depending on the context such as "The object that is on the desk and behind the cup.". However, deep learning approaches cannot reliably interpret such deictic representations due to their lack of reasoning capabilities in complex scenarios. To remedy this issue, we propose DeiSAM -- a combination of large pre-trained neural networks with differentiable logic reasoners -- for deictic promptable segmentation. Given a complex, textual segmentation description, DeiSAM leverages Large Language Models (LLMs) to generate first-order logic rules and performs differentiable forward reasoning on generated scene graphs. Subsequently, DeiSAM segments objects by matching them to the logically inferred image regions. As part of our evaluation, we propose the Deictic Visual Genome (DeiVG) dataset, containing paired visual input and complex, deictic textual prompts. Our empirical results demonstrate that DeiSAM is a substantial improvement over purely data-driven baselines for deictic promptable segmentation.
Learning by Self-Explaining
Sep 15, 2023Artificial intelligence (AI) research has a long track record of drawing inspirations from findings from biology, in particular human intelligence. In contrast to current AI research that mainly treats explanations as a means for model inspection, a somewhat neglected finding from human psychology is the benefit of self-explaining in an agents' learning process. Motivated by this, we introduce a novel learning paradigm, termed Learning by Self-Explaining (LSX). The underlying idea is that a learning module (learner) performs a base task, e.g. image classification, and provides explanations to its decisions. An internal critic module next evaluates the quality of these explanations given the original task. Finally, the learner is refined with the critic's feedback and the loop is repeated as required. The intuition behind this is that an explanation is considered "good" if the critic can perform the same task given the respective explanation. Despite many implementation possibilities the structure of any LSX instantiation can be taxonomized based on four learning modules which we identify as: Fit, Explain, Reflect and Revise. In our work, we provide distinct instantiations of LSX for two different learner models, each illustrating different choices for the various LSX components. We broadly evaluate these on several datasets and show that Learning by Self-Explaining not only boosts the generalization abilities of AI models, particularly in small-data regimes, but also aids in mitigating the influence of confounding factors, as well as leading to more task specific and faithful model explanations. Overall, our results provide experimental evidence of the potential of self-explaining within the learning phase of an AI model.
Learning Differentiable Logic Programs for Abstract Visual Reasoning
Jul 03, 2023Visual reasoning is essential for building intelligent agents that understand the world and perform problem-solving beyond perception. Differentiable forward reasoning has been developed to integrate reasoning with gradient-based machine learning paradigms. However, due to the memory intensity, most existing approaches do not bring the best of the expressivity of first-order logic, excluding a crucial ability to solve abstract visual reasoning, where agents need to perform reasoning by using analogies on abstract concepts in different scenarios. To overcome this problem, we propose NEUro-symbolic Message-pAssiNg reasoNer (NEUMANN), which is a graph-based differentiable forward reasoner, passing messages in a memory-efficient manner and handling structured programs with functors. Moreover, we propose a computationally-efficient structure learning algorithm to perform explanatory program induction on complex visual scenes. To evaluate, in addition to conventional visual reasoning tasks, we propose a new task, visual reasoning behind-the-scenes, where agents need to learn abstract programs and then answer queries by imagining scenes that are not observed. We empirically demonstrate that NEUMANN solves visual reasoning tasks efficiently, outperforming neural, symbolic, and neuro-symbolic baselines.
V-LoL: A Diagnostic Dataset for Visual Logical Learning
Jul 03, 2023



Despite the successes of recent developments in visual AI, different shortcomings still exist; from missing exact logical reasoning, to abstract generalization abilities, to understanding complex and noisy scenes. Unfortunately, existing benchmarks, were not designed to capture more than a few of these aspects. Whereas deep learning datasets focus on visually complex data but simple visual reasoning tasks, inductive logic datasets involve complex logical learning tasks, however, lack the visual component. To address this, we propose the visual logical learning dataset, V-LoL, that seamlessly combines visual and logical challenges. Notably, we introduce the first instantiation of V-LoL, V-LoL-Trains, -- a visual rendition of a classic benchmark in symbolic AI, the Michalski train problem. By incorporating intricate visual scenes and flexible logical reasoning tasks within a versatile framework, V-LoL-Trains provides a platform for investigating a wide range of visual logical learning challenges. We evaluate a variety of AI systems including traditional symbolic AI, neural AI, as well as neuro-symbolic AI. Our evaluations demonstrate that even state-of-the-art AI faces difficulties in dealing with visual logical learning challenges, highlighting unique advantages and limitations specific to each methodology. Overall, V-LoL opens up new avenues for understanding and enhancing current abilities in visual logical learning for AI systems.
Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
Jun 02, 2023The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
Differentiable Meta logical Programming
Nov 21, 2022Deep learning uses an increasing amount of computation and data to solve very specific problems. By stark contrast, human minds solve a wide range of problems using a fixed amount of computation and limited experience. One ability that seems crucial to this kind of general intelligence is meta-reasoning, i.e., our ability to reason about reasoning. To make deep learning do more from less, we propose the differentiable logical meta interpreter (DLMI). The key idea is to realize a meta-interpreter using differentiable forward-chaining reasoning in first-order logic. This directly allows DLMI to reason and even learn about its own operations. This is different from performing object-level deep reasoning and learning, which refers in some way to entities external to the system. In contrast, DLMI is able to reflect or introspect, i.e., to shift from meta-reasoning to object-level reasoning and vice versa. Among many other experimental evaluations, we illustrate this behavior using the novel task of "repairing Kandinsky patterns," i.e., how to edit the objects in an image so that it agrees with a given logical concept.
LogicRank: Logic Induced Reranking for Generative Text-to-Image Systems
Aug 29, 2022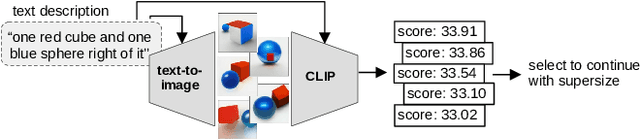



Text-to-image models have recently achieved remarkable success with seemingly accurate samples in photo-realistic quality. However as state-of-the-art language models still struggle evaluating precise statements consistently, so do language model based image generation processes. In this work we showcase problems of state-of-the-art text-to-image models like DALL-E with generating accurate samples from statements related to the draw bench benchmark. Furthermore we show that CLIP is not able to rerank those generated samples consistently. To this end we propose LogicRank, a neuro-symbolic reasoning framework that can result in a more accurate ranking-system for such precision-demanding settings. LogicRank integrates smoothly into the generation process of text-to-image models and moreover can be used to further fine-tune towards a more logical precise model.