 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicRank: Logic Induced Reranking for Generative Text-to-Image Systems
Paper and Code
Aug 29, 2022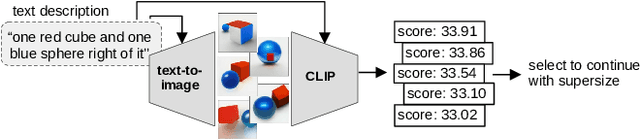



Text-to-image models have recently achieved remarkable success with seemingly accurate samples in photo-realistic quality. However as state-of-the-art language models still struggle evaluating precise statements consistently, so do language model based image generation processes. In this work we showcase problems of state-of-the-art text-to-image models like DALL-E with generating accurate samples from statements related to the draw bench benchmark. Furthermore we show that CLIP is not able to rerank those generated samples consistently. To this end we propose LogicRank, a neuro-symbolic reasoning framework that can result in a more accurate ranking-system for such precision-demanding settings. LogicRank integrates smoothly into the generation process of text-to-image models and moreover can be used to further fine-tune towards a more logical precise model.