 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything with Robust Uncertainty-Accuracy Correlation
May 11, 2026Despite strong zero-shot performance, SAM is unreliable under domain shift due to Mask-level Confidence Confusion (MCC), where a single IoU-based mask score fails to reflect pixel-wise reliability near boundaries. Motivated by the contrast between texture-biased shortcuts in neural networks and shape-centric processing in human vision, we model out-of-domain variation as appearance shifts and non-rigid deformations that jointly stress calibration. We propose Segment Anything with Robust Uncertainty-Accuracy Correlation (RUAC) for robust pixel-wise uncertainty estimation under appearance and deformation shifts. RUAC adds a lightweight uncertainty head, trains it with a collaborative style-deformation attack that jointly perturbs texture and geometry, and applies Uncertainty-Accuracy Alignment to ensure uncertainty consistently highlights erroneous pixels even under adversarial perturbations. Across 23 zero-shot domains, RUAC improves segmentation quality and yields more faithful uncertainty with stronger uncertainty-accuracy correlation. Project page: https://github.com/HongyouZhou/ruac.git.
Compression as an Adversarial Amplifier Through Decision Space Reduction
Apr 08, 2026Image compression is a ubiquitous component of modern visual pipelines, routinely applied by social media platforms and resource-constrained systems prior to inference. Despite its prevalence, the impact of compression on adversarial robustness remains poorly understood. We study a previously unexplored adversarial setting in which attacks are applied directly in compressed representations, and show that compression can act as an adversarial amplifier for deep image classifiers. Under identical nominal perturbation budgets, compression-aware attacks are substantially more effective than their pixel-space counterparts. We attribute this effect to decision space reduction, whereby compression induces a non-invertible, information-losing transformation that contracts classification margins and increases sensitivity to perturbations. Extensive experiments across standard benchmarks and architectures support our analysis and reveal a critical vulnerability in compression-in-the-loop deployment settings. Code will be released.
Low-Effort Jailbreak Attacks Against Text-to-Image Safety Filters
Apr 02, 2026Text-to-image generative models are widely deployed in creative tools and online platforms. To mitigate misuse, these systems rely on safety filters and moderation pipelines that aim to block harmful or policy violating content. In this work we show that modern text-to-image models remain vulnerable to low-effort jailbreak attacks that require only natural language prompts. We present a systematic study of prompt-based strategies that bypass safety filters without model access, optimization, or adversarial training. We introduce a taxonomy of visual jailbreak techniques including artistic reframing, material substitution, pseudo-educational framing, lifestyle aesthetic camouflage, and ambiguous action substitution. These strategies exploit weaknesses in prompt moderation and visual safety filtering by masking unsafe intent within benign semantic contexts. We evaluate these attacks across several state-of-the-art text-to-image systems and demonstrate that simple linguistic modifications can reliably evade existing safeguards and produce restricted imagery. Our findings highlight a critical gap between surface-level prompt filtering and the semantic understanding required to detect adversarial intent in generative media systems. Across all tested models and attack categories we observe an attack success rate (ASR) of up to 74.47%.
Do Phone-Use Agents Respect Your Privacy?
Apr 02, 2026We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as permissioned access, minimal disclosure, and user-controlled memory through a minimal privacy contract, iMy, and pair it with instrumented mock apps plus rule-based auditing that make unnecessary permission requests, deceptive re-disclosure, and unnecessary form filling observable and reproducible. Across five frontier models on 10 mobile apps and 300 tasks, we find that task success, privacy-compliant task completion, and later-session use of saved preferences are distinct capabilities, and no single model dominates all three. Evaluating success and privacy jointly reshuffles the model ordering relative to either metric alone. The most persistent failure mode across models is simple data minimization: agents still fill optional personal entries that the task does not require. These results show that privacy failures arise from over-helpful execution of benign tasks, and that success-only evaluation overestimates the deployment readiness of current phone-use agents. All code, mock apps, and agent trajectories are publicly available at~ https://github.com/FreedomIntelligence/MyPhoneBench.
ZeroDiff++: Substantial Unseen Visual-semantic Correlation in Zero-shot Learning
Feb 12, 2026Zero-shot Learning (ZSL) enables classifiers to recognize classes unseen during training, commonly via generative two stage methods: (1) learn visual semantic correlations from seen classes; (2) synthesize unseen class features from semantics to train classifiers. In this paper, we identify spurious visual semantic correlations in existing generative ZSL worsened by scarce seen class samples and introduce two metrics to quantify spuriousness for seen and unseen classes. Furthermore, we point out a more critical bottleneck: existing unadaptive fully noised generators produce features disconnected from real test samples, which also leads to the spurious correlation. To enhance the visual-semantic correlations on both seen and unseen classes, we propose ZeroDiff++, a diffusion-based generative framework. In training, ZeroDiff++ uses (i) diffusion augmentation to produce diverse noised samples, (ii) supervised contrastive (SC) representations for instance level semantics, and (iii) multi view discriminators with Wasserstein mutual learning to assess generated features. At generation time, we introduce (iv) Diffusion-based Test time Adaptation (DiffTTA) to adapt the generator using pseudo label reconstruction, and (v) Diffusion-based Test time Generation (DiffGen) to trace the diffusion denoising path and produce partially synthesized features that connect real and generated data, and mitigates data scarcity further. Extensive experiments on three ZSL benchmarks demonstrate that ZeroDiff++ not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code would be available.
Adversarial Robustness in Zero-Shot Learning:An Empirical Study on Class and Concept-Level Vulnerabilities
Dec 21, 2025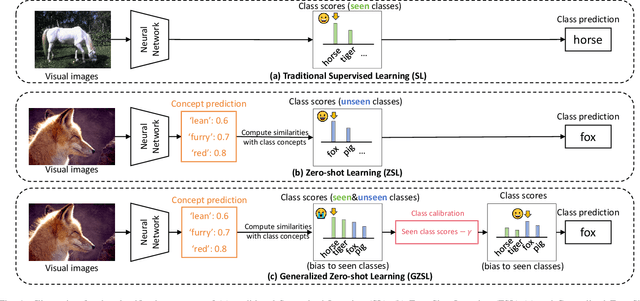

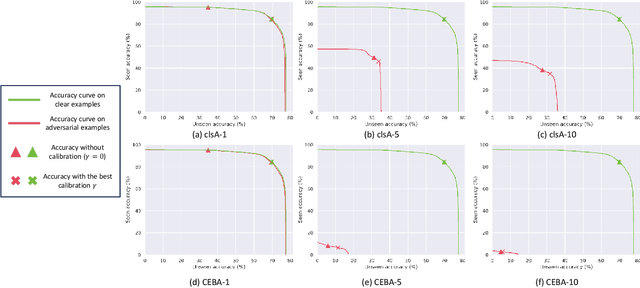
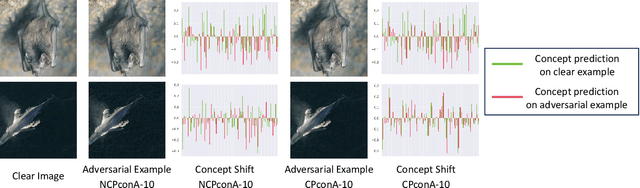
Zero-shot Learning (ZSL) aims to enable image classifiers to recognize images from unseen classes that were not included during training. Unlike traditional supervised classification, ZSL typically relies on learning a mapping from visual features to predefined, human-understandable class concepts. While ZSL models promise to improve generalization and interpretability, their robustness under systematic input perturbations remain unclear. In this study, we present an empirical analysis about the robustness of existing ZSL methods at both classlevel and concept-level. Specifically, we successfully disrupted their class prediction by the well-known non-target class attack (clsA). However, in the Generalized Zero-shot Learning (GZSL) setting, we observe that the success of clsA is only at the original best-calibrated point. After the attack, the optimal bestcalibration point shifts, and ZSL models maintain relatively strong performance at other calibration points, indicating that clsA results in a spurious attack success in the GZSL. To address this, we propose the Class-Bias Enhanced Attack (CBEA), which completely eliminates GZSL accuracy across all calibrated points by enhancing the gap between seen and unseen class probabilities.Next, at concept-level attack, we introduce two novel attack modes: Class-Preserving Concept Attack (CPconA) and NonClass-Preserving Concept Attack (NCPconA). Our extensive experiments evaluate three typical ZSL models across various architectures from the past three years and reveal that ZSL models are vulnerable not only to the traditional class attack but also to concept-based attacks. These attacks allow malicious actors to easily manipulate class predictions by erasing or introducing concepts. Our findings highlight a significant performance gap between existing approaches, emphasizing the need for improved adversarial robustness in current ZSL models.
Anyone Can Jailbreak: Prompt-Based Attacks on LLMs and T2Is
Jul 29, 2025Despite significant advancements in alignment and content moderation, large language models (LLMs) and text-to-image (T2I) systems remain vulnerable to prompt-based attacks known as jailbreaks. Unlike traditional adversarial examples requiring expert knowledge, many of today's jailbreaks are low-effort, high-impact crafted by everyday users with nothing more than cleverly worded prompts. This paper presents a systems-style investigation into how non-experts reliably circumvent safety mechanisms through techniques such as multi-turn narrative escalation, lexical camouflage, implication chaining, fictional impersonation, and subtle semantic edits. We propose a unified taxonomy of prompt-level jailbreak strategies spanning both text-output and T2I models, grounded in empirical case studies across popular APIs. Our analysis reveals that every stage of the moderation pipeline, from input filtering to output validation, can be bypassed with accessible strategies. We conclude by highlighting the urgent need for context-aware defenses that reflect the ease with which these jailbreaks can be reproduced in real-world settings.
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Jul 08, 2025Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
Learning from Less: Guiding Deep Reinforcement Learning with Differentiable Symbolic Planning
May 16, 2025



When tackling complex problems, humans naturally break them down into smaller, manageable subtasks and adjust their initial plans based on observations. For instance, if you want to make coffee at a friend's place, you might initially plan to grab coffee beans, go to the coffee machine, and pour them into the machine. Upon noticing that the machine is full, you would skip the initial steps and proceed directly to brewing. In stark contrast, state of the art reinforcement learners, such as Proximal Policy Optimization (PPO), lack such prior knowledge and therefore require significantly more training steps to exhibit comparable adaptive behavior. Thus, a central research question arises: \textit{How can we enable reinforcement learning (RL) agents to have similar ``human priors'', allowing the agent to learn with fewer training interactions?} To address this challenge, we propose differentiable symbolic planner (Dylan), a novel framework that integrates symbolic planning into Reinforcement Learning. Dylan serves as a reward model that dynamically shapes rewards by leveraging human priors, guiding agents through intermediate subtasks, thus enabling more efficient exploration. Beyond reward shaping, Dylan can work as a high level planner that composes primitive policies to generate new behaviors while avoiding common symbolic planner pitfalls such as infinite execution loops. Our experimental evaluations demonstrate that Dylan significantly improves RL agents' performance and facilitates generalization to unseen tasks.
Interpretable Zero-shot Learning with Infinite Class Concepts
May 06, 2025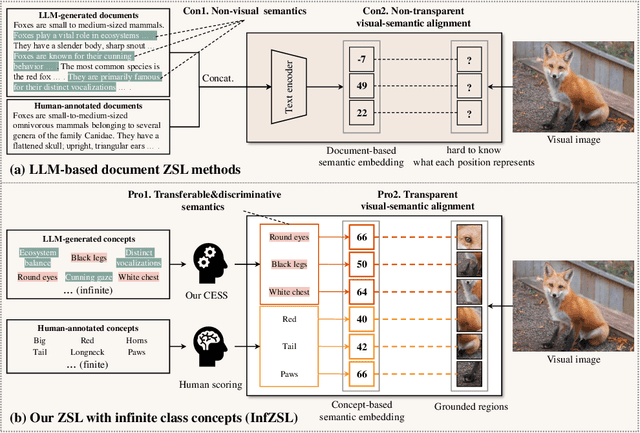
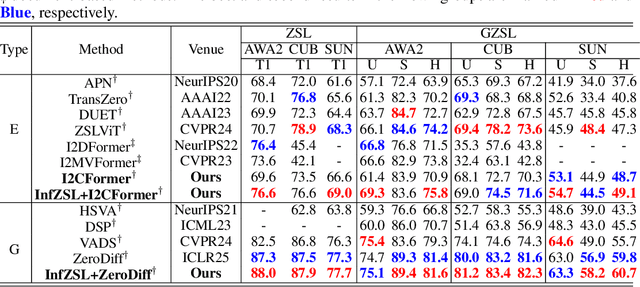
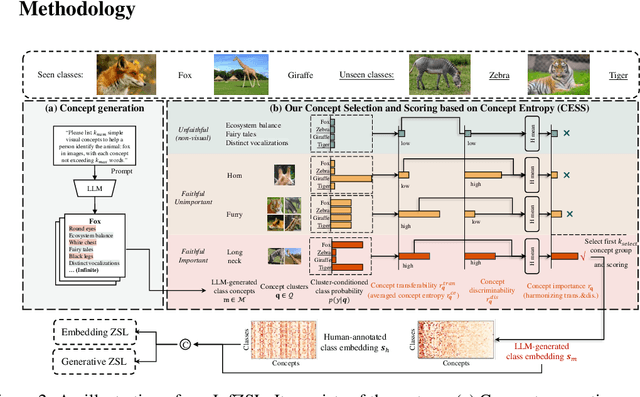
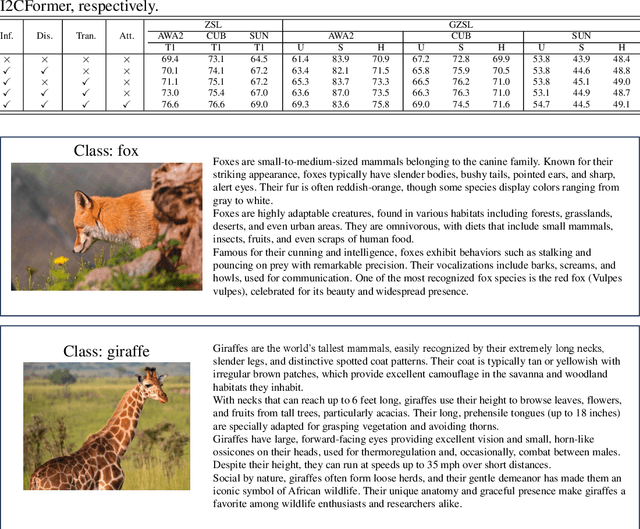
Zero-shot learning (ZSL) aims to recognize unseen classes by aligning images with intermediate class semantics, like human-annotated concepts or class definitions. An emerging alternative leverages Large-scale Language Models (LLMs) to automatically generate class documents. However, these methods often face challenges with transparency in the classification process and may suffer from the notorious hallucination problem in LLMs, resulting in non-visual class semantics. This paper redefines class semantics in ZSL with a focus on transferability and discriminability, introducing a novel framework called Zero-shot Learning with Infinite Class Concepts (InfZSL). Our approach leverages the powerful capabilities of LLMs to dynamically generate an unlimited array of phrase-level class concepts. To address the hallucination challenge, we introduce an entropy-based scoring process that incorporates a ``goodness" concept selection mechanism, ensuring that only the most transferable and discriminative concepts are selected. Our InfZSL framework not only demonstrates significant improvements on three popular benchmark datasets but also generates highly interpretable, image-grounded concepts. Code will be released upon acceptance.