 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation
Mar 23, 2026Earth Observation (EO) is essential for perceiving dynamic land surface changes, yet deploying autonomous EO in open environments is hindered by the immense diversity of multi-source data and heterogeneous tasks. While remote sensing agents have emerged to streamline EO workflows, existing tool-calling agents are confined to closed environments. They rely on pre-defined tools and are restricted to narrow scope, limiting their generalization to the diverse data and tasks. To overcome these limitations, we introduce OpenEarth-Agent, the first tool-creation agent framework tailored for open-environment EO. Rather than calling predefined tools, OpenEarth-Agent employs adaptive workflow planning and tool creation to generalize to unseen data and tasks. This adaptability is bolstered by an open-ended integration of multi-stage tools and cross-domain knowledge bases, enabling robust execution in the entire EO pipeline across multiple application domains. To comprehensively evaluate EO agents in open environments, we propose OpenEarth-Bench, a novel benchmark comprising 596 real-world, full-pipeline cases across seven application domains, explicitly designed to assess agents' adaptive planning and tool creation capabilities. Only essential pre-trained model tools are provided in this benchmark, devoid of any other predefined task-specific tools. Extensive experiments demonstrate that OpenEarth-Agent successfully masters full-pipeline EO across multiple domains in the open environment. Notably, on the cross-benchmark Earth-Bench, our tool-creating agent equipped with 6 essential pre-trained models achieves performance comparable to tool-calling agents relying on 104 specialized tools, and significantly outperforms them when provided with the complete toolset. In several cases, the created tools exhibit superior robustness to data anomalies compared to human-engineered counterparts.
TRACE: A Multi-Agent System for Autonomous Physical Reasoning in Seismological Science
Mar 22, 2026Inferring the physical mechanisms that govern earthquake sequences from indirect geophysical observations remains difficult, particularly across tectonically distinct environments where similar seismic patterns can reflect different underlying processes. Current interpretations rely heavily on the expert synthesis of catalogs, spatiotemporal statistics, and candidate physical models, limiting reproducibility and the systematic transfer of insight across settings. Here we present TRACE (Trans-perspective Reasoning and Automated Comprehensive Evaluator), a multi-agent system that combines large language model planning with formal seismological constraints to derive auditable, physically grounded mechanistic inference from raw observations. Applied to the 2019 Ridgecrest sequence, TRACE autonomously identifies stress-perturbation-induced delayed triggering, resolving the cascading interaction between the Mw 6.4 and Mw 7.1 mainshocks; in the Santorini-Kolumbo case, the system identifies a structurally guided intrusion model, distinguishing fault-channeled episodic migration from the continuous propagation expected in homogeneous crustal failure. By providing a generalizable logical infrastructure for interpreting heterogeneous seismic phenomena, TRACE advances the field from expert-dependent analysis toward knowledge-guided autonomous discovery in Earth sciences.
Accurate and Efficient Hybrid-Ensemble Atmospheric Data Assimilation in Latent Space with Uncertainty Quantification
Mar 04, 2026Data assimilation (DA) combines model forecasts and observations to estimate the optimal state of the atmosphere with its uncertainty, providing initial conditions for weather prediction and reanalyses for climate research. Yet, existing traditional and machine-learning DA methods struggle to achieve accuracy, efficiency and uncertainty quantification simultaneously. Here, we propose HLOBA (Hybrid-Ensemble Latent Observation-Background Assimilation), a three-dimensional hybrid-ensemble DA method that operates in an atmospheric latent space learned via an autoencoder (AE). HLOBA maps both model forecasts and observations into a shared latent space via the AE encoder and an end-to-end Observation-to-Latent-space mapping network (O2Lnet), respectively, and fuses them through a Bayesian update with weights inferred from time-lagged ensemble forecasts. Both idealized and real-observation experiments demonstrate that HLOBA matches dynamically constrained four-dimensional DA methods in both analysis and forecast skill, while achieving end-to-end inference-level efficiency and theoretical flexibility applies to any forecasting model. Moreover, by exploiting the error decorrelation property of latent variables, HLOBA enables element-wise uncertainty estimates for its latent analysis and propagates them to model space via the decoder. Idealized experiments show that this uncertainty highlights large-error regions and captures their seasonal variability.
IceBench-S2S: A Benchmark of Deep Learning for Challenging Subseasonal-to-Seasonal Daily Arctic Sea Ice Forecasting in Deep Latent Space
Jan 31, 2026Arctic sea ice plays a critical role in regulating Earth's climate system, significantly influencing polar ecological stability and human activities in coastal regions. Recent advances in artificial intelligence have facilitated the development of skillful pan-Arctic sea ice forecasting systems, where data-driven approaches showcase tremendous potential to outperform conventional physics-based numerical models in terms of accuracy, computational efficiency and forecasting lead times. Despite the latest progress made by deep learning (DL) forecasting models, most of their skillful forecasting lead times are confined to daily subseasonal scale and monthly averaged values for up to six months, which drastically hinders their deployment for real-world applications, e.g., maritime routine planning for Arctic transportation and scientific investigation. Extending daily forecasts from subseasonal to seasonal (S2S) scale is scientifically crucial for operational applications. To bridge the gap between the forecasting lead time of current DL models and the significant daily S2S scale, we introduce IceBench-S2S, the first comprehensive benchmark for evaluating DL approaches in mitigating the challenge of forecasting Arctic sea ice concentration in successive 180-day periods. It proposes a generalized framework that first compresses spatial features of daily sea ice data into a deep latent space. The temporally concatenated deep features are subsequently modeled by DL-based forecasting backbones to predict the sea ice variation at S2S scale. IceBench-S2S provides a unified training and evaluation pipeline for different backbones, along with practical guidance for model selection in polar environmental monitoring tasks.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
SynWeather: Weather Observation Data Synthesis across Multiple Regions and Variables via a General Diffusion Transformer
Nov 15, 2025With the advancement of meteorological instruments, abundant data has become available. Current approaches are typically focus on single-variable, single-region tasks and primarily rely on deterministic modeling. This limits unified synthesis across variables and regions, overlooks cross-variable complementarity and often leads to over-smoothed results. To address above challenges, we introduce SynWeather, the first dataset designed for Unified Multi-region and Multi-variable Weather Observation Data Synthesis. SynWeather covers four representative regions: the Continental United States, Europe, East Asia, and Tropical Cyclone regions, as well as provides high-resolution observations of key weather variables, including Composite Radar Reflectivity, Hourly Precipitation, Visible Light, and Microwave Brightness Temperature. In addition, we introduce SynWeatherDiff, a general and probabilistic weather synthesis model built upon the Diffusion Transformer framework to address the over-smoothed problem. Experiments on the SynWeather dataset demonstrate the effectiveness of our network compared with both task-specific and general models.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
A Survey of Deep Learning-based Point Cloud Denoising
Aug 23, 2025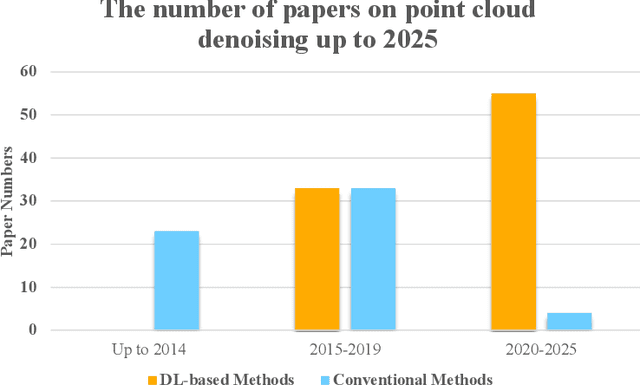
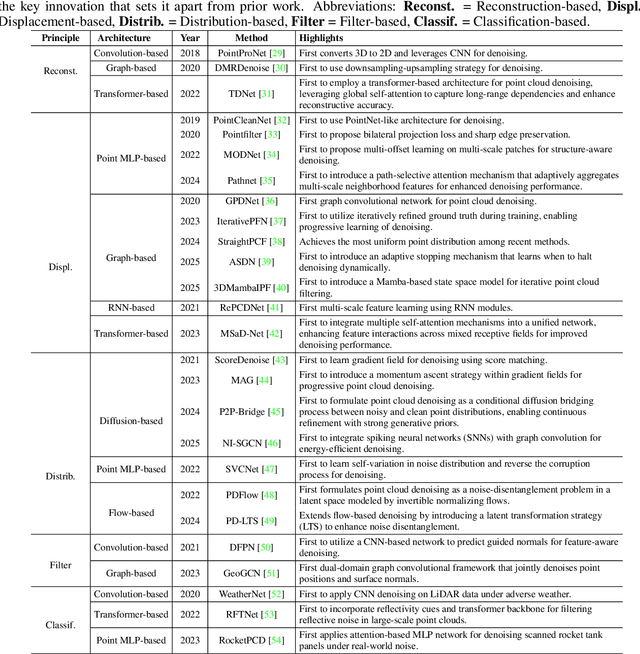
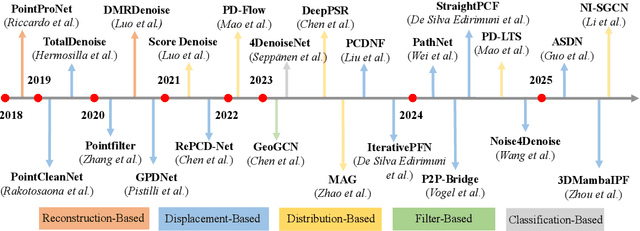

Accurate 3D geometry acquisition is essential for a wide range of applications, such as computer graphics, autonomous driving, robotics, and augmented reality. However, raw point clouds acquired in real-world environments are often corrupted with noise due to various factors such as sensor, lighting, material, environment etc, which reduces geometric fidelity and degrades downstream performance. Point cloud denoising is a fundamental problem, aiming to recover clean point sets while preserving underlying structures. Classical optimization-based methods, guided by hand-crafted filters or geometric priors, have been extensively studied but struggle to handle diverse and complex noise patterns. Recent deep learning approaches leverage neural network architectures to learn distinctive representations and demonstrate strong outcomes, particularly on complex and large-scale point clouds. Provided these significant advances, this survey provides a comprehensive and up-to-date review of deep learning-based point cloud denoising methods up to August 2025. We organize the literature from two perspectives: (1) supervision level (supervised vs. unsupervised), and (2) modeling perspective, proposing a functional taxonomy that unifies diverse approaches by their denoising principles. We further analyze architectural trends both structurally and chronologically, establish a unified benchmark with consistent training settings, and evaluate methods in terms of denoising quality, surface fidelity, point distribution, and computational efficiency. Finally, we discuss open challenges and outline directions for future research in this rapidly evolving field.
EarthLink: A Self-Evolving AI Agent for Climate Science
Jul 24, 2025


Modern Earth science is at an inflection point. The vast, fragmented, and complex nature of Earth system data, coupled with increasingly sophisticated analytical demands, creates a significant bottleneck for rapid scientific discovery. Here we introduce EarthLink, the first AI agent designed as an interactive copilot for Earth scientists. It automates the end-to-end research workflow, from planning and code generation to multi-scenario analysis. Unlike static diagnostic tools, EarthLink can learn from user interaction, continuously refining its capabilities through a dynamic feedback loop. We validated its performance on a number of core scientific tasks of climate change, ranging from model-observation comparisons to the diagnosis of complex phenomena. In a multi-expert evaluation, EarthLink produced scientifically sound analyses and demonstrated an analytical competency that was rated as comparable to specific aspects of a human junior researcher's workflow. Additionally, its transparent, auditable workflows and natural language interface empower scientists to shift from laborious manual execution to strategic oversight and hypothesis generation. EarthLink marks a pivotal step towards an efficient, trustworthy, and collaborative paradigm for Earth system research in an era of accelerating global change. The system is accessible at our website https://earthlink.intern-ai.org.cn.
Multi-modal Multi-task Pre-training for Improved Point Cloud Understanding
Jul 23, 2025Recent advances in multi-modal pre-training methods have shown promising effectiveness in learning 3D representations by aligning multi-modal features between 3D shapes and their corresponding 2D counterparts. However, existing multi-modal pre-training frameworks primarily rely on a single pre-training task to gather multi-modal data in 3D applications. This limitation prevents the models from obtaining the abundant information provided by other relevant tasks, which can hinder their performance in downstream tasks, particularly in complex and diverse domains. In order to tackle this issue, we propose MMPT, a Multi-modal Multi-task Pre-training framework designed to enhance point cloud understanding. Specifically, three pre-training tasks are devised: (i) Token-level reconstruction (TLR) aims to recover masked point tokens, endowing the model with representative learning abilities. (ii) Point-level reconstruction (PLR) is integrated to predict the masked point positions directly, and the reconstructed point cloud can be considered as a transformed point cloud used in the subsequent task. (iii) Multi-modal contrastive learning (MCL) combines feature correspondences within and across modalities, thus assembling a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised manner. Moreover, this framework operates without requiring any 3D annotations, making it scalable for use with large datasets. The trained encoder can be effectively transferred to various downstream tasks. To demonstrate its effectiveness, we evaluated its performance compared to state-of-the-art methods in various discriminant and generative applications under widely-used benchmarks.