 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarth-o1: A Grid-free Observation-native Atmospheric World Model
May 07, 2026Despite the unprecedented volume of multimodal data provided by modern Earth observation systems, our ability to model atmospheric dynamics remains constrained. Traditional modeling frameworks force heterogeneous measurements into predefined spatial grids, inherently limiting the full exploitation of raw sensor data and creating severe computational bottlenecks. Here we present Earth-o1, an observation-native atmospheric world model that overcomes these structural limitations. Rather than relying on conventional atmospheric dynamical modeling systems or traditional data assimilation, Earth-o1 directly learns the continuous, three-dimensional physical evolution of the Earth system from ungridded observational data. By integrating diverse sensor inputs into a unified, grid-free dynamical field, the model autonomously advances the atmospheric state in space and time. We show that this fundamentally distinct paradigm enables direct, real-time forecasting and cross-sensor inference without the overhead of explicit numerical solvers. In hindcast evaluations, Earth-o1 achieves surface forecast skill comparable to the operational Integrated Forecasting System (IFS). These results establish that continuous, observation-driven world models -- a new class of fully observation-native geophysical simulators -- can match the fidelity of established physical frameworks, providing a scalable data-driven foundation for a digital twin of the Earth.
TokenCom: Vision-Language Model for Multimodal and Multitask Token Communications
Feb 28, 2026Visual-Language Models (VLMs), with their strong capabilities in image and text understanding, offer a solid foundation for intelligent communications. However, their effectiveness is constrained by limited token granularity, overlong visual token sequences, and inadequate cross-modal alignment. To overcome these challenges, we propose TaiChi, a novel VLM framework designed for token communications. TaiChi adopts a dual-visual tokenizer architecture that processes both high- and low-resolution images to collaboratively capture pixel-level details and global conceptual features. A Bilateral Attention Network (BAN) is introduced to intelligently fuse multi-scale visual tokens, thereby enhancing visual understanding and producing compact visual tokens. In addition, a Kolmogorov Arnold Network (KAN)-based modality projector with learnable activation functions is employed to achieve precise nonlinear alignment from visual features to the text semantic space, thus minimizing information loss. Finally, TaiChi is integrated into a multimodal and multitask token communication system equipped with a joint VLM-channel coding scheme. Experimental results validate the superior performance of TaiChi, as well as the feasibility and effectiveness of the TaiChi-driven token communication system.
IceBench-S2S: A Benchmark of Deep Learning for Challenging Subseasonal-to-Seasonal Daily Arctic Sea Ice Forecasting in Deep Latent Space
Jan 31, 2026Arctic sea ice plays a critical role in regulating Earth's climate system, significantly influencing polar ecological stability and human activities in coastal regions. Recent advances in artificial intelligence have facilitated the development of skillful pan-Arctic sea ice forecasting systems, where data-driven approaches showcase tremendous potential to outperform conventional physics-based numerical models in terms of accuracy, computational efficiency and forecasting lead times. Despite the latest progress made by deep learning (DL) forecasting models, most of their skillful forecasting lead times are confined to daily subseasonal scale and monthly averaged values for up to six months, which drastically hinders their deployment for real-world applications, e.g., maritime routine planning for Arctic transportation and scientific investigation. Extending daily forecasts from subseasonal to seasonal (S2S) scale is scientifically crucial for operational applications. To bridge the gap between the forecasting lead time of current DL models and the significant daily S2S scale, we introduce IceBench-S2S, the first comprehensive benchmark for evaluating DL approaches in mitigating the challenge of forecasting Arctic sea ice concentration in successive 180-day periods. It proposes a generalized framework that first compresses spatial features of daily sea ice data into a deep latent space. The temporally concatenated deep features are subsequently modeled by DL-based forecasting backbones to predict the sea ice variation at S2S scale. IceBench-S2S provides a unified training and evaluation pipeline for different backbones, along with practical guidance for model selection in polar environmental monitoring tasks.
Satellite Observations Guided Diffusion Model for Accurate Meteorological States at Arbitrary Resolution
Feb 09, 2025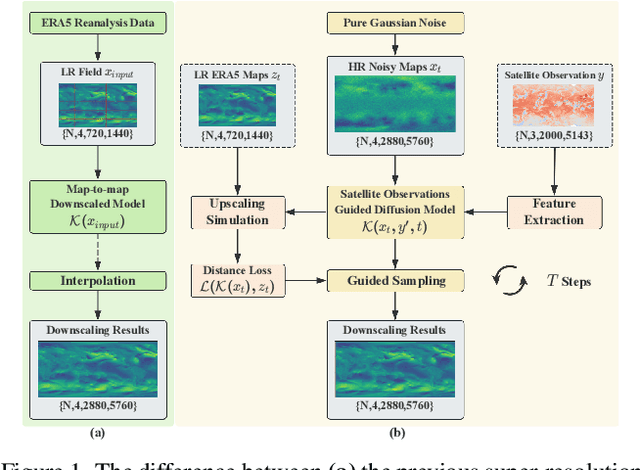
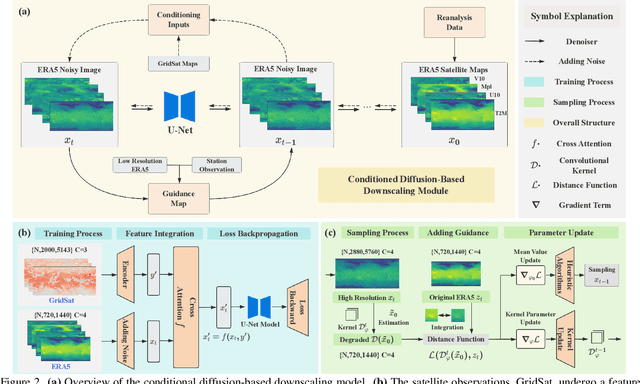
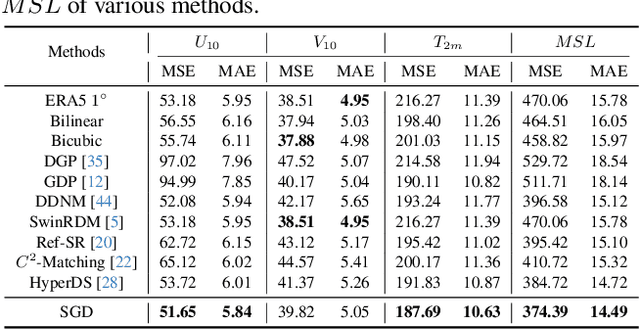
Accurate acquisition of surface meteorological conditions at arbitrary locations holds significant importance for weather forecasting and climate simulation. Due to the fact that meteorological states derived from satellite observations are often provided in the form of low-resolution grid fields, the direct application of spatial interpolation to obtain meteorological states for specific locations often results in significant discrepancies when compared to actual observations. Existing downscaling methods for acquiring meteorological state information at higher resolutions commonly overlook the correlation with satellite observations. To bridge the gap, we propose Satellite-observations Guided Diffusion Model (SGD), a conditional diffusion model pre-trained on ERA5 reanalysis data with satellite observations (GridSat) as conditions, which is employed for sampling downscaled meteorological states through a zero-shot guided sampling strategy and patch-based methods. During the training process, we propose to fuse the information from GridSat satellite observations into ERA5 maps via the attention mechanism, enabling SGD to generate atmospheric states that align more accurately with actual conditions. In the sampling, we employed optimizable convolutional kernels to simulate the upscale process, thereby generating high-resolution ERA5 maps using low-resolution ERA5 maps as well as observations from weather stations as guidance. Moreover, our devised patch-based method promotes SGD to generate meteorological states at arbitrary resolutions. Experiments demonstrate SGD fulfills accurate meteorological states downscaling to 6.25km.
Large Generative Model-assisted Talking-face Semantic Communication System
Nov 06, 2024
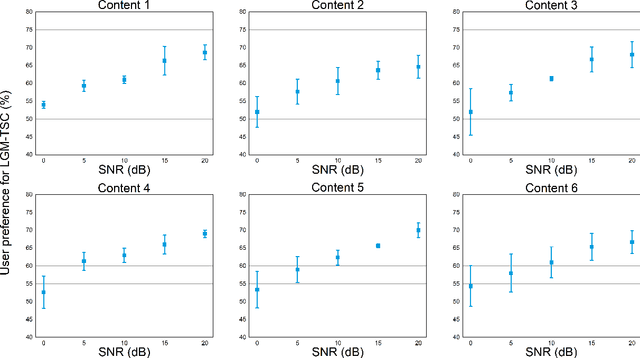
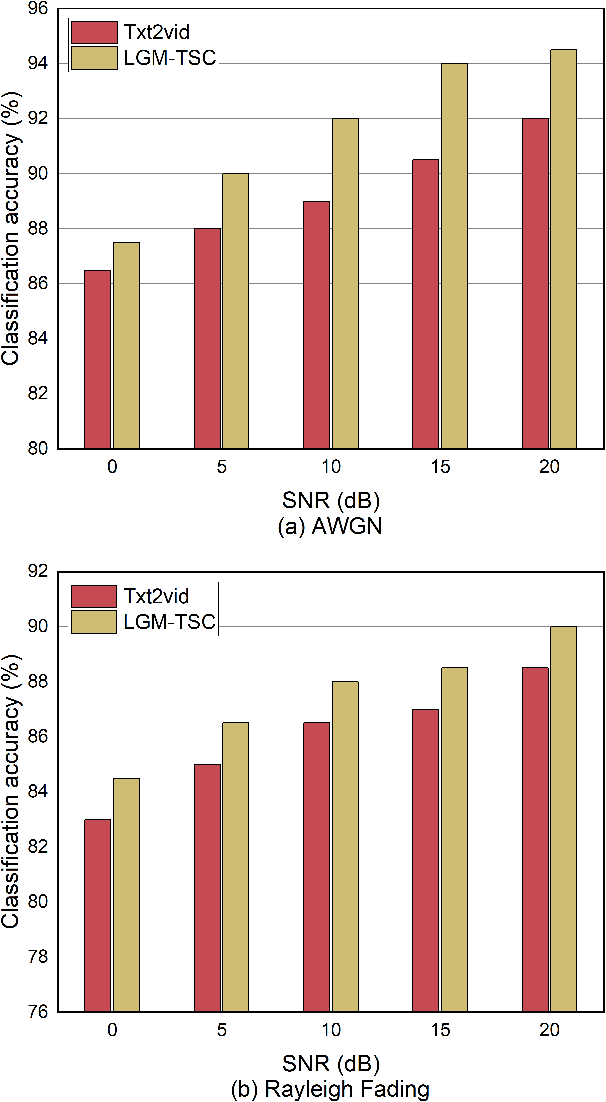

The rapid development of generative Artificial Intelligence (AI) continually unveils the potential of Semantic Communication (SemCom). However, current talking-face SemCom systems still encounter challenges such as low bandwidth utilization, semantic ambiguity, and diminished Quality of Experience (QoE). This study introduces a Large Generative Model-assisted Talking-face Semantic Communication (LGM-TSC) System tailored for the talking-face video communication. Firstly, we introduce a Generative Semantic Extractor (GSE) at the transmitter based on the FunASR model to convert semantically sparse talking-face videos into texts with high information density. Secondly, we establish a private Knowledge Base (KB) based on the Large Language Model (LLM) for semantic disambiguation and correction, complemented by a joint knowledge base-semantic-channel coding scheme. Finally, at the receiver, we propose a Generative Semantic Reconstructor (GSR) that utilizes BERT-VITS2 and SadTalker models to transform text back into a high-QoE talking-face video matching the user's timbre. Simulation results demonstrate the feasibility and effectiveness of the proposed LGM-TSC system.
IceDiff: High Resolution and High-Quality Sea Ice Forecasting with Generative Diffusion Prior
Oct 10, 2024Variation of Arctic sea ice has significant impacts on polar ecosystems, transporting routes, coastal communities, and global climate. Tracing the change of sea ice at a finer scale is paramount for both operational applications and scientific studies. Recent pan-Arctic sea ice forecasting methods that leverage advances in artificial intelligence has made promising progress over numerical models. However, forecasting sea ice at higher resolutions is still under-explored. To bridge the gap, we propose a two-staged deep learning framework, IceDiff, to forecast sea ice concentration at finer scales. IceDiff first leverages an independently trained vision transformer to generate coarse yet superior forecasting over previous methods at a regular 25km x 25km grid. This high-quality sea ice forecasting can be utilized as reliable guidance for the next stage. Subsequently, an unconditional diffusion model pre-trained on sea ice concentration maps is utilized for sampling down-scaled sea ice forecasting via a zero-shot guided sampling strategy and a patch-based method. For the first time, IceDiff demonstrates sea ice forecasting with the 6.25km x 6.25km resolution. IceDiff extends the boundary of existing sea ice forecasting models and more importantly, its capability to generate high-resolution sea ice concentration data is vital for pragmatic usages and research.
PostCast: Generalizable Postprocessing for Precipitation Nowcasting via Unsupervised Blurriness Modeling
Oct 08, 2024

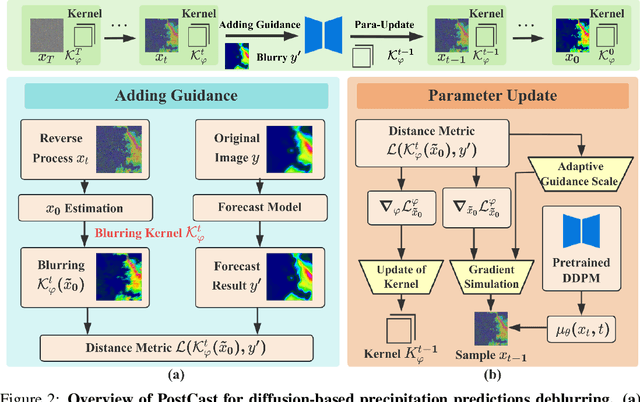

Precipitation nowcasting plays a pivotal role in socioeconomic sectors, especially in severe convective weather warnings. Although notable progress has been achieved by approaches mining the spatiotemporal correlations with deep learning, these methods still suffer severe blurriness as the lead time increases, which hampers accurate predictions for extreme precipitation. To alleviate blurriness, researchers explore generative methods conditioned on blurry predictions. However, the pairs of blurry predictions and corresponding ground truth need to be generated in advance, making the training pipeline cumbersome and limiting the generality of generative models within blur modes that appear in training data. By rethinking the blurriness in precipitation nowcasting as a blur kernel acting on predictions, we propose an unsupervised postprocessing method to eliminate the blurriness without the requirement of training with the pairs of blurry predictions and corresponding ground truth. Specifically, we utilize blurry predictions to guide the generation process of a pre-trained unconditional denoising diffusion probabilistic model (DDPM) to obtain high-fidelity predictions with eliminated blurriness. A zero-shot blur kernel estimation mechanism and an auto-scale denoise guidance strategy are introduced to adapt the unconditional DDPM to any blurriness modes varying from datasets and lead times in precipitation nowcasting. Extensive experiments are conducted on 7 precipitation radar datasets, demonstrating the generality and superiority of our method.
Taming Generative Diffusion for Universal Blind Image Restoration
Aug 21, 2024
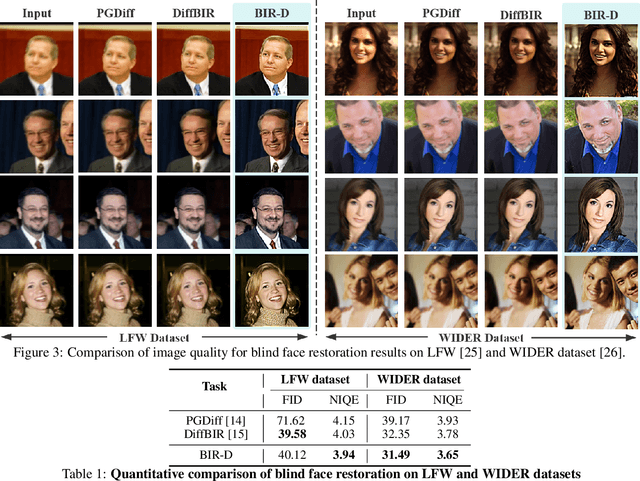


Diffusion models have been widely utilized for image restoration. However, previous blind image restoration methods still need to assume the type of degradation model while leaving the parameters to be optimized, limiting their real-world applications. Therefore, we aim to tame generative diffusion prior for universal blind image restoration dubbed BIR-D, which utilizes an optimizable convolutional kernel to simulate the degradation model and dynamically update the parameters of the kernel in the diffusion steps, enabling it to achieve blind image restoration results even in various complex situations. Besides, based on mathematical reasoning, we have provided an empirical formula for the chosen of adaptive guidance scale, eliminating the need for a grid search for the optimal parameter. Experimentally, Our BIR-D has demonstrated superior practicality and versatility than off-the-shelf unsupervised methods across various tasks both on real-world and synthetic datasets, qualitatively and quantitatively. BIR-D is able to fulfill multi-guidance blind image restoration. Moreover, BIR-D can also restore images that undergo multiple and complicated degradations, demonstrating the practical applications.
Personalized Wireless Federated Learning for Large Language Models
Apr 20, 2024

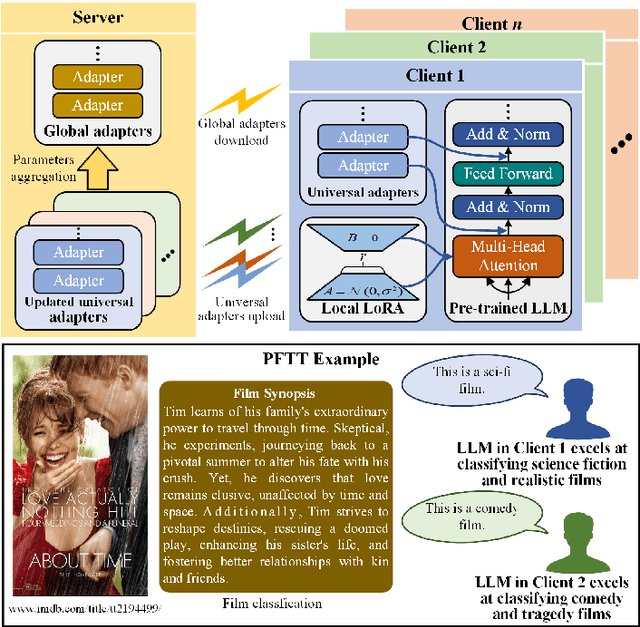

Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.