 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarth-o1: A Grid-free Observation-native Atmospheric World Model
May 07, 2026Despite the unprecedented volume of multimodal data provided by modern Earth observation systems, our ability to model atmospheric dynamics remains constrained. Traditional modeling frameworks force heterogeneous measurements into predefined spatial grids, inherently limiting the full exploitation of raw sensor data and creating severe computational bottlenecks. Here we present Earth-o1, an observation-native atmospheric world model that overcomes these structural limitations. Rather than relying on conventional atmospheric dynamical modeling systems or traditional data assimilation, Earth-o1 directly learns the continuous, three-dimensional physical evolution of the Earth system from ungridded observational data. By integrating diverse sensor inputs into a unified, grid-free dynamical field, the model autonomously advances the atmospheric state in space and time. We show that this fundamentally distinct paradigm enables direct, real-time forecasting and cross-sensor inference without the overhead of explicit numerical solvers. In hindcast evaluations, Earth-o1 achieves surface forecast skill comparable to the operational Integrated Forecasting System (IFS). These results establish that continuous, observation-driven world models -- a new class of fully observation-native geophysical simulators -- can match the fidelity of established physical frameworks, providing a scalable data-driven foundation for a digital twin of the Earth.
Satellite Observations Guided Diffusion Model for Accurate Meteorological States at Arbitrary Resolution
Feb 09, 2025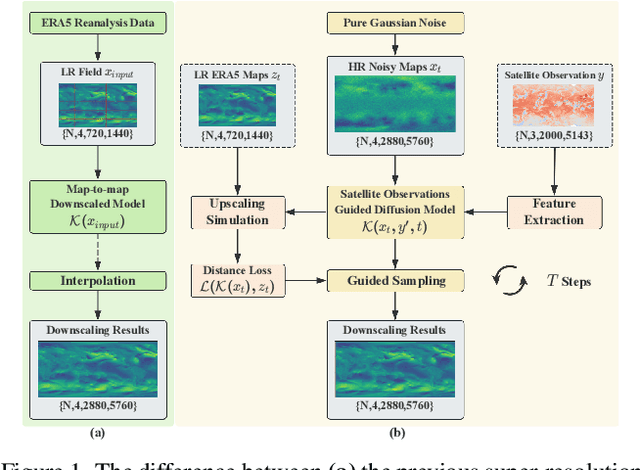
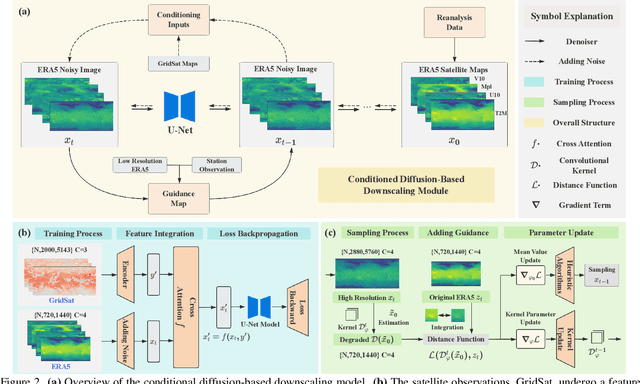
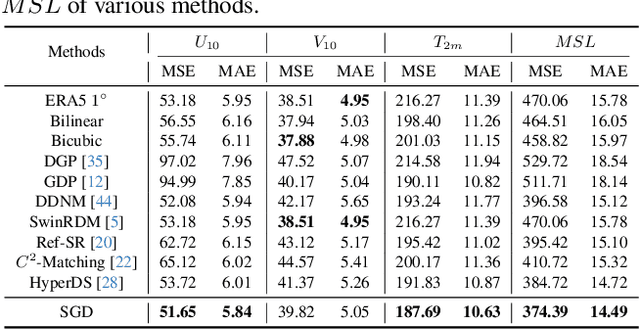
Accurate acquisition of surface meteorological conditions at arbitrary locations holds significant importance for weather forecasting and climate simulation. Due to the fact that meteorological states derived from satellite observations are often provided in the form of low-resolution grid fields, the direct application of spatial interpolation to obtain meteorological states for specific locations often results in significant discrepancies when compared to actual observations. Existing downscaling methods for acquiring meteorological state information at higher resolutions commonly overlook the correlation with satellite observations. To bridge the gap, we propose Satellite-observations Guided Diffusion Model (SGD), a conditional diffusion model pre-trained on ERA5 reanalysis data with satellite observations (GridSat) as conditions, which is employed for sampling downscaled meteorological states through a zero-shot guided sampling strategy and patch-based methods. During the training process, we propose to fuse the information from GridSat satellite observations into ERA5 maps via the attention mechanism, enabling SGD to generate atmospheric states that align more accurately with actual conditions. In the sampling, we employed optimizable convolutional kernels to simulate the upscale process, thereby generating high-resolution ERA5 maps using low-resolution ERA5 maps as well as observations from weather stations as guidance. Moreover, our devised patch-based method promotes SGD to generate meteorological states at arbitrary resolutions. Experiments demonstrate SGD fulfills accurate meteorological states downscaling to 6.25km.
Kolmogorov Arnold Neural Interpolator for Downscaling and Correcting Meteorological Fields from In-Situ Observations
Jan 24, 2025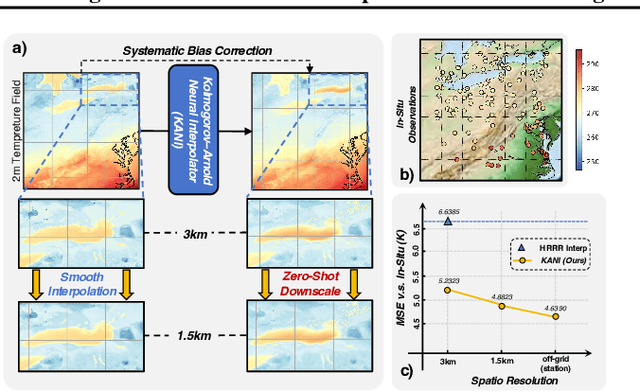

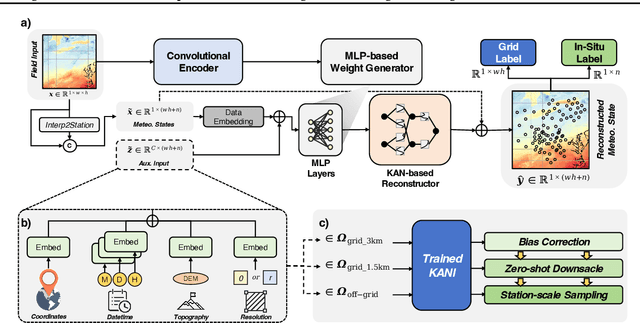
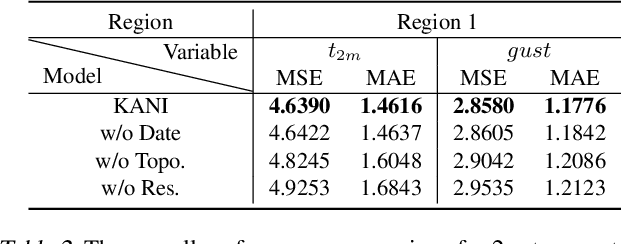
Obtaining accurate weather forecasts at station locations is a critical challenge due to systematic biases arising from the mismatch between multi-scale, continuous atmospheric characteristic and their discrete, gridded representations. Previous works have primarily focused on modeling gridded meteorological data, inherently neglecting the off-grid, continuous nature of atmospheric states and leaving such biases unresolved. To address this, we propose the Kolmogorov Arnold Neural Interpolator (KANI), a novel framework that redefines meteorological field representation as continuous neural functions derived from discretized grids. Grounded in the Kolmogorov Arnold theorem, KANI captures the inherent continuity of atmospheric states and leverages sparse in-situ observations to correct these biases systematically. Furthermore, KANI introduces an innovative zero-shot downscaling capability, guided by high-resolution topographic textures without requiring high-resolution meteorological fields for supervision. Experimental results across three sub-regions of the continental United States indicate that KANI achieves an accuracy improvement of 40.28% for temperature and 67.41% for wind speed, highlighting its significant improvement over traditional interpolation methods. This enables continuous neural representation of meteorological variables through neural networks, transcending the limitations of conventional grid-based representations.
WSSM: Geographic-enhanced hierarchical state-space model for global station weather forecast
Jan 20, 2025Global Station Weather Forecasting (GSWF), a prominent meteorological research area, is pivotal in providing timely localized weather predictions. Despite the progress existing models have made in the overall accuracy of the GSWF, executing high-precision extreme event prediction still presents a substantial challenge. The recent emergence of state-space models, with their ability to efficiently capture continuous-time dynamics and latent states, offer potential solutions. However, early investigations indicated that Mamba underperforms in the context of GSWF, suggesting further adaptation and optimization. To tackle this problem, in this paper, we introduce Weather State-space Model (WSSM), a novel Mamba-based approach tailored for GSWF. Geographical knowledge is integrated in addition to the widely-used positional encoding to represent the absolute special-temporal position. The multi-scale time-frequency features are synthesized from coarse to fine to model the seasonal to extreme weather dynamic. Our method effectively improves the overall prediction accuracy and addresses the challenge of forecasting extreme weather events. The state-of-the-art results obtained on the Weather-5K subset underscore the efficacy of the WSSM
MambaDS: Near-Surface Meteorological Field Downscaling with Topography Constrained Selective State Space Modeling
Aug 20, 2024



In an era of frequent extreme weather and global warming, obtaining precise, fine-grained near-surface weather forecasts is increasingly essential for human activities. Downscaling (DS), a crucial task in meteorological forecasting, enables the reconstruction of high-resolution meteorological states for target regions from global-scale forecast results. Previous downscaling methods, inspired by CNN and Transformer-based super-resolution models, lacked tailored designs for meteorology and encountered structural limitations. Notably, they failed to efficiently integrate topography, a crucial prior in the downscaling process. In this paper, we address these limitations by pioneering the selective state space model into the meteorological field downscaling and propose a novel model called MambaDS. This model enhances the utilization of multivariable correlations and topography information, unique challenges in the downscaling process while retaining the advantages of Mamba in long-range dependency modeling and linear computational complexity. Through extensive experiments in both China mainland and the continental United States (CONUS), we validated that our proposed MambaDS achieves state-of-the-art results in three different types of meteorological field downscaling settings. We will release the code subsequently.
Multi-view Remote Sensing Image Segmentation With SAM priors
May 23, 2024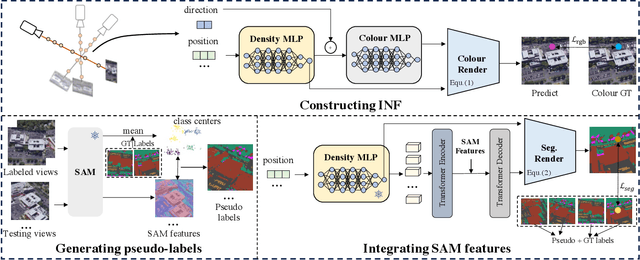
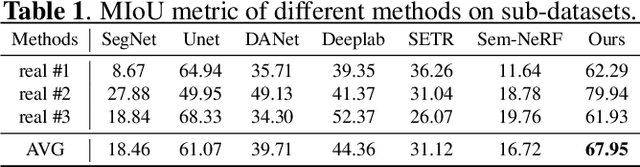
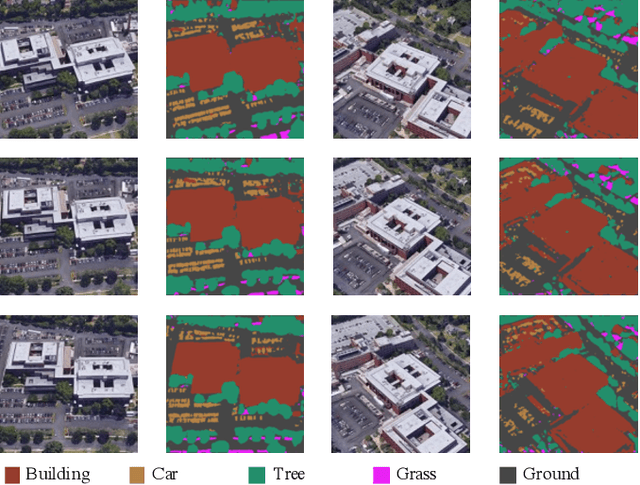
Multi-view segmentation in Remote Sensing (RS) seeks to segment images from diverse perspectives within a scene. Recent methods leverage 3D information extracted from an Implicit Neural Field (INF), bolstering result consistency across multiple views while using limited accounts of labels (even within 3-5 labels) to streamline labor. Nonetheless, achieving superior performance within the constraints of limited-view labels remains challenging due to inadequate scene-wide supervision and insufficient semantic features within the INF. To address these. we propose to inject the prior of the visual foundation model-Segment Anything(SAM), to the INF to obtain better results under the limited number of training data. Specifically, we contrast SAM features between testing and training views to derive pseudo labels for each testing view, augmenting scene-wide labeling information. Subsequently, we introduce SAM features via a transformer into the INF of the scene, supplementing the semantic information. The experimental results demonstrate that our method outperforms the mainstream method, confirming the efficacy of SAM as a supplement to the INF for this task.
Observation-Guided Meteorological Field Downscaling at Station Scale: A Benchmark and a New Method
Jan 22, 2024Downscaling (DS) of meteorological variables involves obtaining high-resolution states from low-resolution meteorological fields and is an important task in weather forecasting. Previous methods based on deep learning treat downscaling as a super-resolution task in computer vision and utilize high-resolution gridded meteorological fields as supervision to improve resolution at specific grid scales. However, this approach has struggled to align with the continuous distribution characteristics of meteorological fields, leading to an inherent systematic bias between the downscaled results and the actual observations at meteorological stations. In this paper, we extend meteorological downscaling to arbitrary scattered station scales, establish a brand new benchmark and dataset, and retrieve meteorological states at any given station location from a coarse-resolution meteorological field. Inspired by data assimilation techniques, we integrate observational data into the downscaling process, providing multi-scale observational priors. Building on this foundation, we propose a new downscaling model based on hypernetwork architecture, namely HyperDS, which efficiently integrates different observational information into the model training, achieving continuous scale modeling of the meteorological field. Through extensive experiments, our proposed method outperforms other specially designed baseline models on multiple surface variables. Notably, the mean squared error (MSE) for wind speed and surface pressure improved by 67% and 19.5% compared to other methods. We will release the dataset and code subsequently.
Learning to detect cloud and snow in remote sensing images from noisy labels
Jan 17, 2024


Detecting clouds and snow in remote sensing images is an essential preprocessing task for remote sensing imagery. Previous works draw inspiration from semantic segmentation models in computer vision, with most research focusing on improving model architectures to enhance detection performance. However, unlike natural images, the complexity of scenes and the diversity of cloud types in remote sensing images result in many inaccurate labels in cloud and snow detection datasets, introducing unnecessary noises into the training and testing processes. By constructing a new dataset and proposing a novel training strategy with the curriculum learning paradigm, we guide the model in reducing overfitting to noisy labels. Additionally, we design a more appropriate model performance evaluation method, that alleviates the performance assessment bias caused by noisy labels. By conducting experiments on models with UNet and Segformer, we have validated the effectiveness of our proposed method. This paper is the first to consider the impact of label noise on the detection of clouds and snow in remote sensing images.
DeepPhysiNet: Bridging Deep Learning and Atmospheric Physics for Accurate and Continuous Weather Modeling
Jan 04, 2024Accurate weather forecasting holds significant importance to human activities. Currently, there are two paradigms for weather forecasting: Numerical Weather Prediction (NWP) and Deep Learning-based Prediction (DLP). NWP utilizes atmospheric physics for weather modeling but suffers from poor data utilization and high computational costs, while DLP can learn weather patterns from vast amounts of data directly but struggles to incorporate physical laws. Both paradigms possess their respective strengths and weaknesses, and are incompatible, because physical laws adopted in NWP describe the relationship between coordinates and meteorological variables, while DLP directly learns the relationships between meteorological variables without consideration of coordinates. To address these problems, we introduce the DeepPhysiNet framework, incorporating physical laws into deep learning models for accurate and continuous weather system modeling. First, we construct physics networks based on multilayer perceptrons (MLPs) for individual meteorological variable, such as temperature, pressure, and wind speed. Physics networks establish relationships between variables and coordinates by taking coordinates as input and producing variable values as output. The physical laws in the form of Partial Differential Equations (PDEs) can be incorporated as a part of loss function. Next, we construct hyper-networks based on deep learning methods to directly learn weather patterns from a large amount of meteorological data. The output of hyper-networks constitutes a part of the weights for the physics networks. Experimental results demonstrate that, upon successful integration of physical laws, DeepPhysiNet can accomplish multiple tasks simultaneously, not only enhancing forecast accuracy but also obtaining continuous spatiotemporal resolution results, which is unattainable by either the NWP or DLP.
Time Travelling Pixels: Bitemporal Features Integration with Foundation Model for Remote Sensing Image Change Detection
Dec 23, 2023

Change detection, a prominent research area in remote sensing, is pivotal in observing and analyzing surface transformations. Despite significant advancements achieved through deep learning-based methods, executing high-precision change detection in spatio-temporally complex remote sensing scenarios still presents a substantial challenge. The recent emergence of foundation models, with their powerful universality and generalization capabilities, offers potential solutions. However, bridging the gap of data and tasks remains a significant obstacle. In this paper, we introduce Time Travelling Pixels (TTP), a novel approach that integrates the latent knowledge of the SAM foundation model into change detection. This method effectively addresses the domain shift in general knowledge transfer and the challenge of expressing homogeneous and heterogeneous characteristics of multi-temporal images. The state-of-the-art results obtained on the LEVIR-CD underscore the efficacy of the TTP. The Code is available at \url{https://kychen.me/TTP}.