 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockGaussian: Efficient Large-Scale Scene Novel View Synthesis via Adaptive Block-Based Gaussian Splatting
Apr 15, 2025
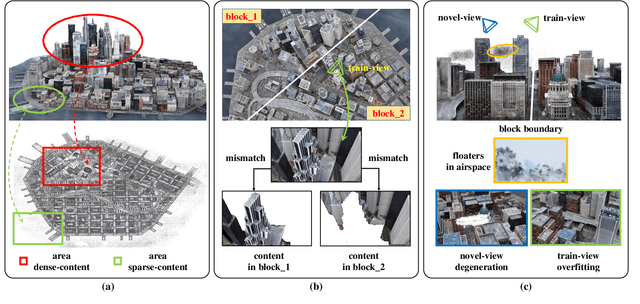
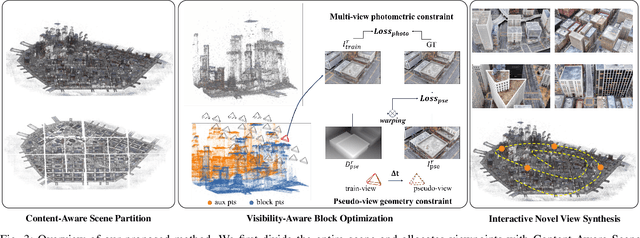
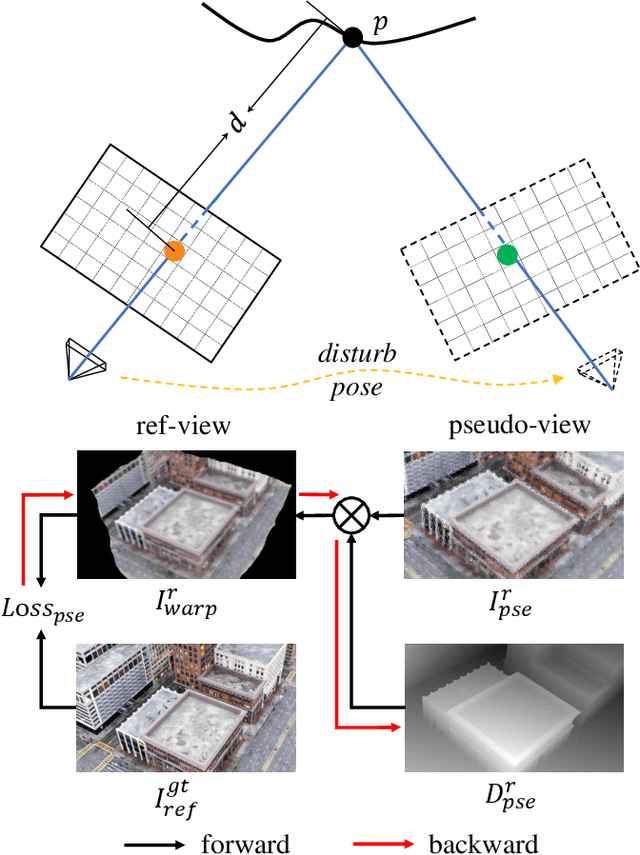
The recent advancements in 3D Gaussian Splatting (3DGS) have demonstrated remarkable potential in novel view synthesis tasks. The divide-and-conquer paradigm has enabled large-scale scene reconstruction, but significant challenges remain in scene partitioning, optimization, and merging processes. This paper introduces BlockGaussian, a novel framework incorporating a content-aware scene partition strategy and visibility-aware block optimization to achieve efficient and high-quality large-scale scene reconstruction. Specifically, our approach considers the content-complexity variation across different regions and balances computational load during scene partitioning, enabling efficient scene reconstruction. To tackle the supervision mismatch issue during independent block optimization, we introduce auxiliary points during individual block optimization to align the ground-truth supervision, which enhances the reconstruction quality. Furthermore, we propose a pseudo-view geometry constraint that effectively mitigates rendering degradation caused by airspace floaters during block merging. Extensive experiments on large-scale scenes demonstrate that our approach achieves state-of-the-art performance in both reconstruction efficiency and rendering quality, with a 5x speedup in optimization and an average PSNR improvement of 1.21 dB on multiple benchmarks. Notably, BlockGaussian significantly reduces computational requirements, enabling large-scale scene reconstruction on a single 24GB VRAM device. The project page is available at https://github.com/SunshineWYC/BlockGaussian
Multi-view Remote Sensing Image Segmentation With SAM priors
May 23, 2024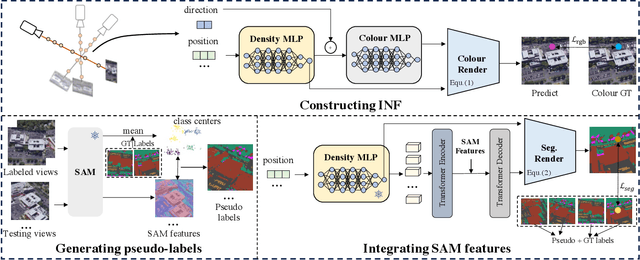
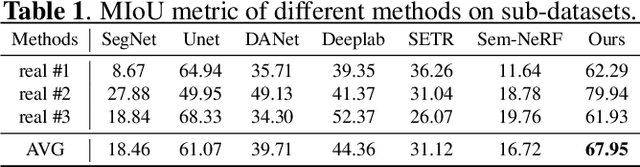
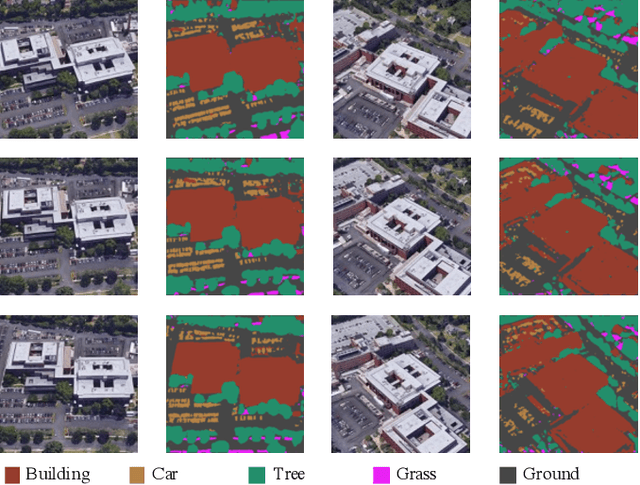
Multi-view segmentation in Remote Sensing (RS) seeks to segment images from diverse perspectives within a scene. Recent methods leverage 3D information extracted from an Implicit Neural Field (INF), bolstering result consistency across multiple views while using limited accounts of labels (even within 3-5 labels) to streamline labor. Nonetheless, achieving superior performance within the constraints of limited-view labels remains challenging due to inadequate scene-wide supervision and insufficient semantic features within the INF. To address these. we propose to inject the prior of the visual foundation model-Segment Anything(SAM), to the INF to obtain better results under the limited number of training data. Specifically, we contrast SAM features between testing and training views to derive pseudo labels for each testing view, augmenting scene-wide labeling information. Subsequently, we introduce SAM features via a transformer into the INF of the scene, supplementing the semantic information. The experimental results demonstrate that our method outperforms the mainstream method, confirming the efficacy of SAM as a supplement to the INF for this task.
Remote Sensing Novel View Synthesis with Implicit Multiplane Representations
May 18, 2022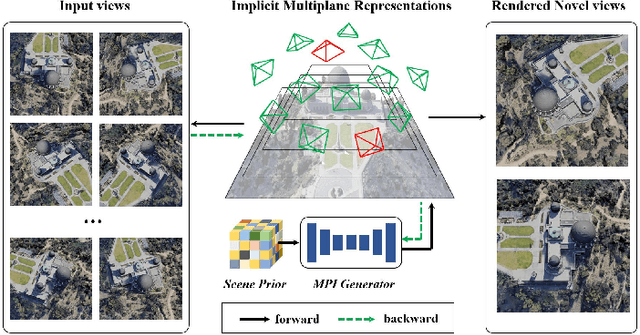
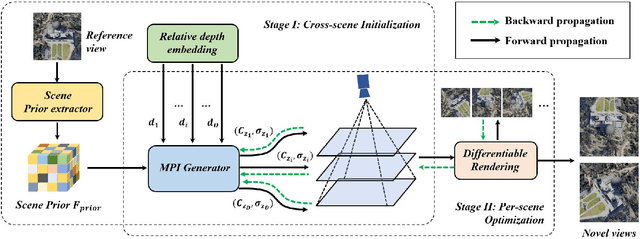
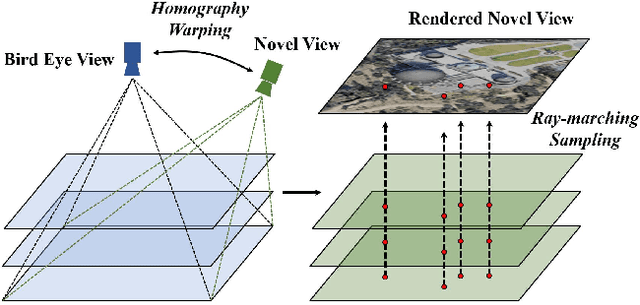
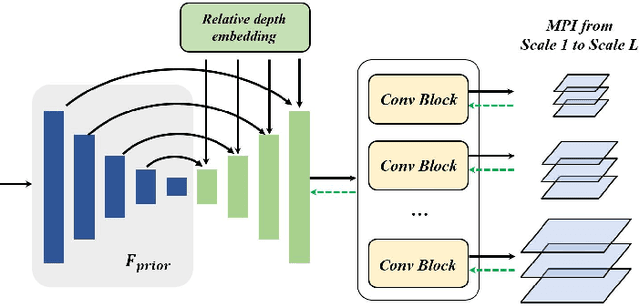
Novel view synthesis of remote sensing scenes is of great significance for scene visualization, human-computer interaction, and various downstream applications. Despite the recent advances in computer graphics and photogrammetry technology, generating novel views is still challenging particularly for remote sensing images due to its high complexity, view sparsity and limited view-perspective variations. In this paper, we propose a novel remote sensing view synthesis method by leveraging the recent advances in implicit neural representations. Considering the overhead and far depth imaging of remote sensing images, we represent the 3D space by combining implicit multiplane images (MPI) representation and deep neural networks. The 3D scene is reconstructed under a self-supervised optimization paradigm through a differentiable multiplane renderer with multi-view input constraints. Images from any novel views thus can be freely rendered on the basis of the reconstructed model. As a by-product, the depth maps corresponding to the given viewpoint can be generated along with the rendering output. We refer to our method as Implicit Multiplane Images (ImMPI). To further improve the view synthesis under sparse-view inputs, we explore the learning-based initialization of remote sensing 3D scenes and proposed a neural network based Prior extractor to accelerate the optimization process. In addition, we propose a new dataset for remote sensing novel view synthesis with multi-view real-world google earth images. Extensive experiments demonstrate the superiority of the ImMPI over previous state-of-the-art methods in terms of reconstruction accuracy, visual fidelity, and time efficiency. Ablation experiments also suggest the effectiveness of our methodology design. Our dataset and code can be found at https://github.com/wyc-Chang/ImMPI