 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Remote Sensing Image Segmentation With SAM priors
May 23, 2024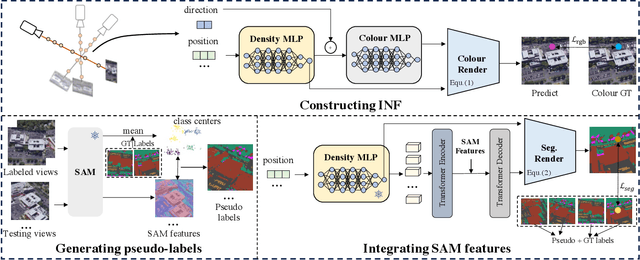
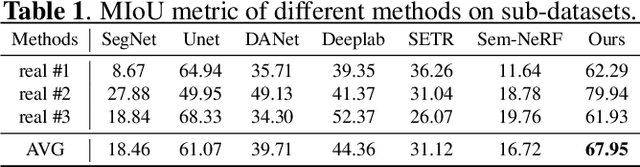
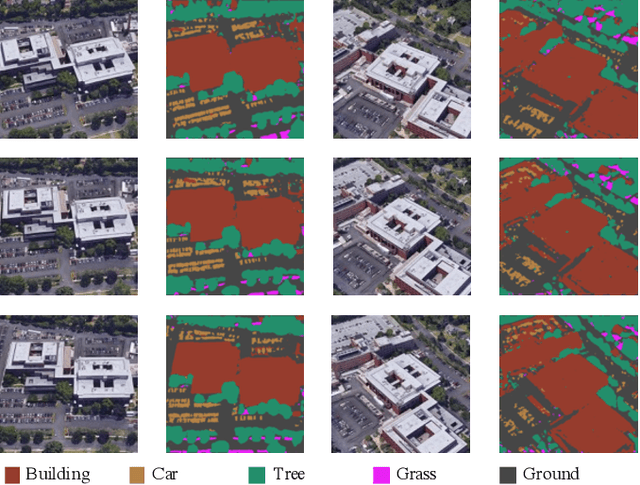
Multi-view segmentation in Remote Sensing (RS) seeks to segment images from diverse perspectives within a scene. Recent methods leverage 3D information extracted from an Implicit Neural Field (INF), bolstering result consistency across multiple views while using limited accounts of labels (even within 3-5 labels) to streamline labor. Nonetheless, achieving superior performance within the constraints of limited-view labels remains challenging due to inadequate scene-wide supervision and insufficient semantic features within the INF. To address these. we propose to inject the prior of the visual foundation model-Segment Anything(SAM), to the INF to obtain better results under the limited number of training data. Specifically, we contrast SAM features between testing and training views to derive pseudo labels for each testing view, augmenting scene-wide labeling information. Subsequently, we introduce SAM features via a transformer into the INF of the scene, supplementing the semantic information. The experimental results demonstrate that our method outperforms the mainstream method, confirming the efficacy of SAM as a supplement to the INF for this task.