 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous and Adept Snapshot Distillation for 3D Semantic Segmentation
Jun 24, 2026Multi-modal fusion and multi-model ensembling are prevalent in enhancing the performance of 3D semantic segmentation. Despite the impressive performance, these methods either rely on auxiliary input signals or suffer from costly computational expense. To efficaciously enhance the segmentation performance without introducing intolerable costs, we propose to transfer the rich knowledge from the multi-modal model (i.e., point clouds and images) and multiple model experts to the point-cloudbased network through knowledge distillation. Specifically, we present Information-oriented Heterogeneous Distillation (IHD) to help the uni-modal model absorb the complementary knowledge from the multi-modal teacher. We design the Information-Oriented Filtering (IOF) strategy to select informative images from the continuous image sequence for multi-modal fusion. This practice can boost the performance of the multi-modal teacher, thus benefiting the learning of the student. Besides, as opposed to vanilla model ensembling that requires the separate training of each expert, we propose Adept Snapshot Distillation (ASD). ASD treats the freely available model snapshots generated during the training phase as multiple experts, which significantly reduces the training cost for model ensembling. For each expert teacher, it only provides supervision to the student in the class where it is adept. The resulting Heterogeneous and Adept Snapshot Knowledge Distillation, dubbed HAS-KD, attains state-of-the-art results on ScanNetV2 and S3DIS datasets. HAS-KD can be seamlessly integrated into contemporary 3D segmentation algorithms and bring considerable gains without introducing extra inference burdens. The code will be made publicly available upon publication.
PD-TPE: Parallel Decoder with Text-guided Position Encoding for 3D Visual Grounding
Jul 19, 2024



3D visual grounding aims to locate the target object mentioned by free-formed natural language descriptions in 3D point cloud scenes. Most previous work requires the encoder-decoder to simultaneously align the attribute information of the target object and its relational information with the surrounding environment across modalities. This causes the queries' attention to be dispersed, potentially leading to an excessive focus on points irrelevant to the input language descriptions. To alleviate these issues, we propose PD-TPE, a visual-language model with a double-branch decoder. The two branches perform proposal feature decoding and surrounding layout awareness in parallel. Since their attention maps are not influenced by each other, the queries focus on tokens relevant to each branch's specific objective. In particular, we design a novel Text-guided Position Encoding method, which differs between the two branches. In the main branch, the priori relies on the relative positions between tokens and predicted 3D boxes, which direct the model to pay more attention to tokens near the object; in the surrounding branch, it is guided by the similarity between visual and text features, so that the queries attend to tokens that can provide effective layout information. Extensive experiments demonstrate that we surpass the state-of-the-art on two widely adopted 3D visual grounding datasets, ScanRefer and NR3D, by 1.8% and 2.2%, respectively. Codes will be made publicly available.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
DGSD: Dynamical Graph Self-Distillation for EEG-Based Auditory Spatial Attention Detection
Sep 07, 2023

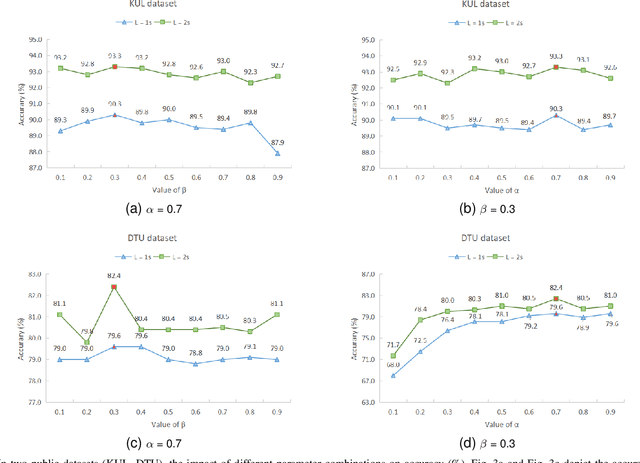

Auditory Attention Detection (AAD) aims to detect target speaker from brain signals in a multi-speaker environment. Although EEG-based AAD methods have shown promising results in recent years, current approaches primarily rely on traditional convolutional neural network designed for processing Euclidean data like images. This makes it challenging to handle EEG signals, which possess non-Euclidean characteristics. In order to address this problem, this paper proposes a dynamical graph self-distillation (DGSD) approach for AAD, which does not require speech stimuli as input. Specifically, to effectively represent the non-Euclidean properties of EEG signals, dynamical graph convolutional networks are applied to represent the graph structure of EEG signals, which can also extract crucial features related to auditory spatial attention in EEG signals. In addition, to further improve AAD detection performance, self-distillation, consisting of feature distillation and hierarchical distillation strategies at each layer, is integrated. These strategies leverage features and classification results from the deepest network layers to guide the learning of shallow layers. Our experiments are conducted on two publicly available datasets, KUL and DTU. Under a 1-second time window, we achieve results of 90.0\% and 79.6\% accuracy on KUL and DTU, respectively. We compare our DGSD method with competitive baselines, and the experimental results indicate that the detection performance of our proposed DGSD method is not only superior to the best reproducible baseline but also significantly reduces the number of trainable parameters by approximately 100 times.
Learning Occupancy for Monocular 3D Object Detection
May 25, 2023
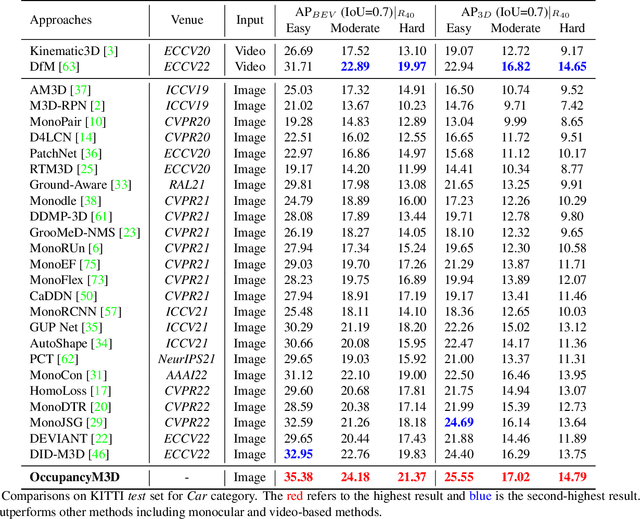
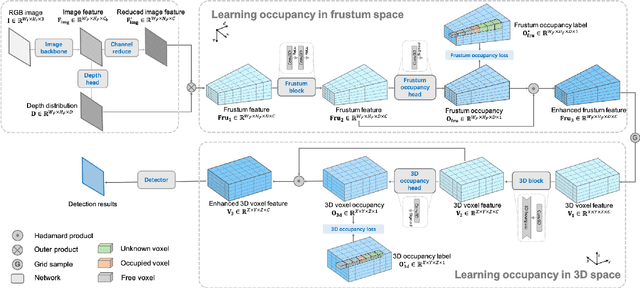
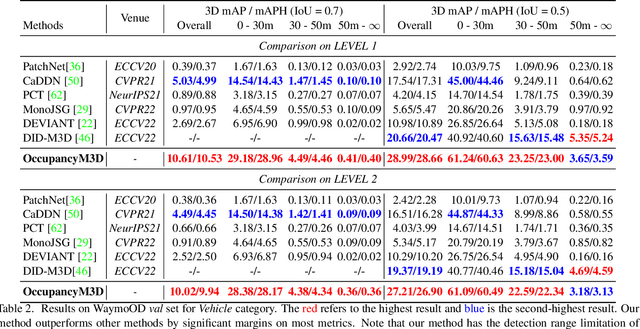
Monocular 3D detection is a challenging task due to the lack of accurate 3D information. Existing approaches typically rely on geometry constraints and dense depth estimates to facilitate the learning, but often fail to fully exploit the benefits of three-dimensional feature extraction in frustum and 3D space. In this paper, we propose \textbf{OccupancyM3D}, a method of learning occupancy for monocular 3D detection. It directly learns occupancy in frustum and 3D space, leading to more discriminative and informative 3D features and representations. Specifically, by using synchronized raw sparse LiDAR point clouds, we define the space status and generate voxel-based occupancy labels. We formulate occupancy prediction as a simple classification problem and design associated occupancy losses. Resulting occupancy estimates are employed to enhance original frustum/3D features. As a result, experiments on KITTI and Waymo open datasets demonstrate that the proposed method achieves a new state of the art and surpasses other methods by a significant margin. Codes and pre-trained models will be available at \url{https://github.com/SPengLiang/OccupancyM3D}.
Boosting Semi-Supervised 3D Object Detection with Semi-Sampling
Nov 15, 2022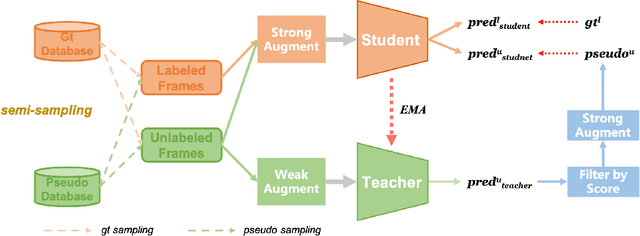



Current 3D object detection methods heavily rely on an enormous amount of annotations. Semi-supervised learning can be used to alleviate this issue. Previous semi-supervised 3D object detection methods directly follow the practice of fully-supervised methods to augment labeled and unlabeled data, which is sub-optimal. In this paper, we design a data augmentation method for semi-supervised learning, which we call Semi-Sampling. Specifically, we use ground truth labels and pseudo labels to crop gt samples and pseudo samples on labeled frames and unlabeled frames, respectively. Then we can generate a gt sample database and a pseudo sample database. When training a teacher-student semi-supervised framework, we randomly select gt samples and pseudo samples to both labeled frames and unlabeled frames, making a strong data augmentation for them. Our semi-sampling can be regarded as an extension of gt-sampling to semi-supervised learning. Our method is simple but effective. We consistently improve state-of-the-art methods on ScanNet, SUN-RGBD, and KITTI benchmarks by large margins. For example, when training using only 10% labeled data on ScanNet, we achieve 3.1 mAP and 6.4 mAP improvement upon 3DIoUMatch in terms of mAP@0.25 and mAP@0.5. When training using only 1% labeled data on KITTI, we boost 3DIoUMatch by 3.5 mAP, 6.7 mAP and 14.1 mAP on car, pedestrian and cyclist classes. Codes will be made publicly available at https://github.com/LittlePey/Semi-Sampling.
Pronunciation Generation for Foreign Language Words in Intra-Sentential Code-Switching Speech Recognition
Oct 26, 2022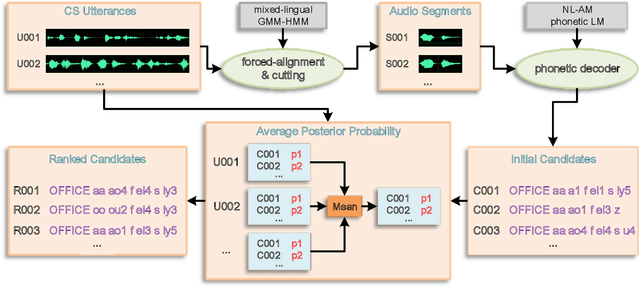

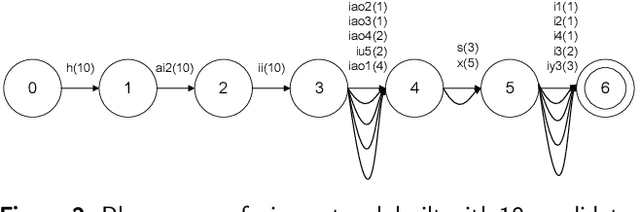

Code-Switching refers to the phenomenon of switching languages within a sentence or discourse. However, limited code-switching , different language phoneme-sets and high rebuilding costs throw a challenge to make the specialized acoustic model for code-switching speech recognition. In this paper, we make use of limited code-switching data as driving materials and explore a shortcut to quickly develop intra-sentential code-switching recognition skill on the commissioned native language acoustic model, where we propose a data-driven method to make the seed lexicon which is used to train grapheme-to-phoneme model to predict mapping pronunciations for foreign language word in code-switching sentences. The core work of the data-driven technology in this paper consists of a phonetic decoding method and different selection methods. And for imbalanced word-level driving materials problem, we have an internal assistance inspiration that learning the good pronunciation rules in the words that possess sufficient materials using the grapheme-to-phoneme model to help the scarce. Our experiments show that the Mixed Error Rate in intra-sentential Chinese-English code-switching recognition reduced from 29.15\%, acquired on the pure Chinese recognizer, to 12.13\% by adding foreign language words' pronunciation through our data-driven approach, and finally get the best result 11.14\% with the combination of different selection methods and internal assistance tactic.
Graph R-CNN: Towards Accurate 3D Object Detection with Semantic-Decorated Local Graph
Aug 07, 2022Two-stage detectors have gained much popularity in 3D object detection. Most two-stage 3D detectors utilize grid points, voxel grids, or sampled keypoints for RoI feature extraction in the second stage. Such methods, however, are inefficient in handling unevenly distributed and sparse outdoor points. This paper solves this problem in three aspects. 1) Dynamic Point Aggregation. We propose the patch search to quickly search points in a local region for each 3D proposal. The dynamic farthest voxel sampling is then applied to evenly sample the points. Especially, the voxel size varies along the distance to accommodate the uneven distribution of points. 2) RoI-graph Pooling. We build local graphs on the sampled points to better model contextual information and mine point relations through iterative message passing. 3) Visual Features Augmentation. We introduce a simple yet effective fusion strategy to compensate for sparse LiDAR points with limited semantic cues. Based on these modules, we construct our Graph R-CNN as the second stage, which can be applied to existing one-stage detectors to consistently improve the detection performance. Extensive experiments show that Graph R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI and Waymo Open Dataset. And we rank first place on the KITTI BEV car detection leaderboard. Code will be available at \url{https://github.com/Nightmare-n/GraphRCNN}.
DETRs with Hybrid Matching
Jul 26, 2022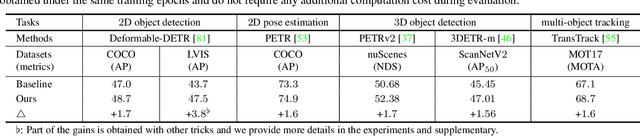
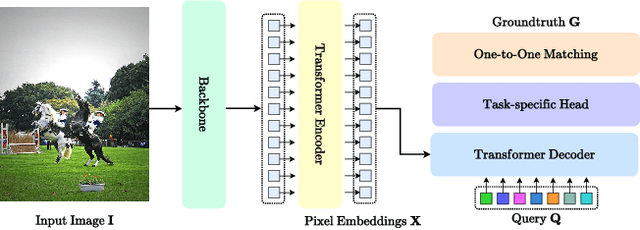

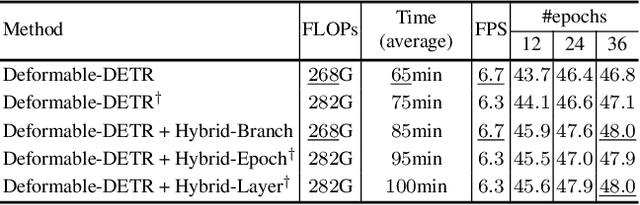
One-to-one set matching is a key design for DETR to establish its end-to-end capability, so that object detection does not require a hand-crafted NMS (non-maximum suppression) method to remove duplicate detections. This end-to-end signature is important for the versatility of DETR, and it has been generalized to a wide range of visual problems, including instance/semantic segmentation, human pose estimation, and point cloud/multi-view-images based detection, etc. However, we note that because there are too few queries assigned as positive samples, the one-to-one set matching significantly reduces the training efficiency of positive samples. This paper proposes a simple yet effective method based on a hybrid matching scheme that combines the original one-to-one matching branch with auxiliary queries that use one-to-many matching loss during training. This hybrid strategy has been shown to significantly improve training efficiency and improve accuracy. In inference, only the original one-to-one match branch is used, thus maintaining the end-to-end merit and the same inference efficiency of DETR. The method is named $\mathcal{H}$-DETR, and it shows that a wide range of representative DETR methods can be consistently improved across a wide range of visual tasks, including Deformable-DETR, 3DETR/PETRv2, PETR, and TransTrack, among others. Code will be available at: https://github.com/HDETR
DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection
Jul 22, 2022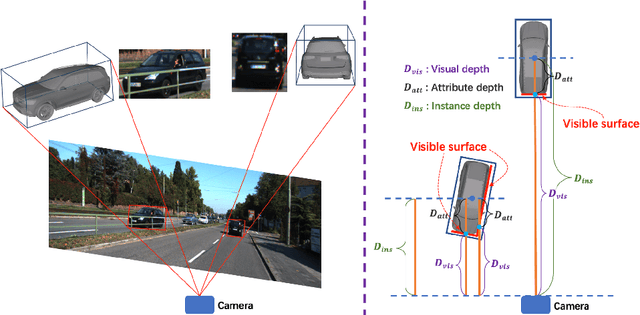
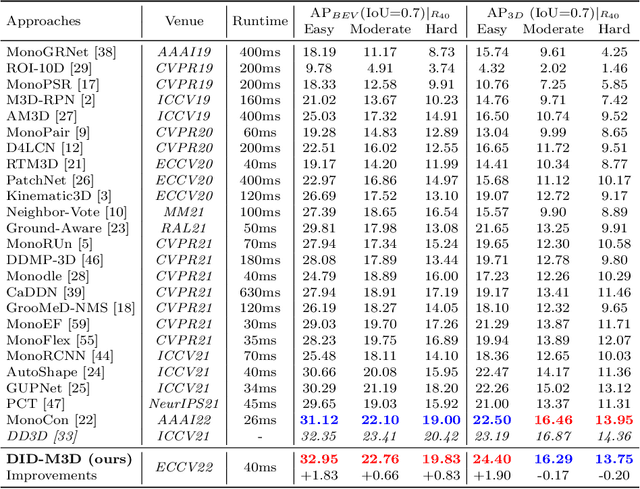
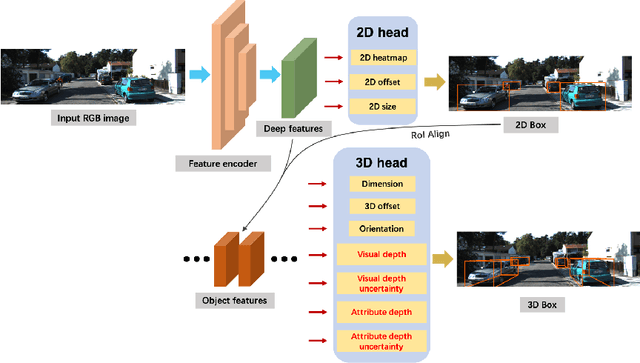

Monocular 3D detection has drawn much attention from the community due to its low cost and setup simplicity. It takes an RGB image as input and predicts 3D boxes in the 3D space. The most challenging sub-task lies in the instance depth estimation. Previous works usually use a direct estimation method. However, in this paper we point out that the instance depth on the RGB image is non-intuitive. It is coupled by visual depth clues and instance attribute clues, making it hard to be directly learned in the network. Therefore, we propose to reformulate the instance depth to the combination of the instance visual surface depth (visual depth) and the instance attribute depth (attribute depth). The visual depth is related to objects' appearances and positions on the image. By contrast, the attribute depth relies on objects' inherent attributes, which are invariant to the object affine transformation on the image. Correspondingly, we decouple the 3D location uncertainty into visual depth uncertainty and attribute depth uncertainty. By combining different types of depths and associated uncertainties, we can obtain the final instance depth. Furthermore, data augmentation in monocular 3D detection is usually limited due to the physical nature, hindering the boost of performance. Based on the proposed instance depth disentanglement strategy, we can alleviate this problem. Evaluated on KITTI, our method achieves new state-of-the-art results, and extensive ablation studies validate the effectiveness of each component in our method. The codes are released at https://github.com/SPengLiang/DID-M3D.