 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePronunciation Generation for Foreign Language Words in Intra-Sentential Code-Switching Speech Recognition
Paper and Code
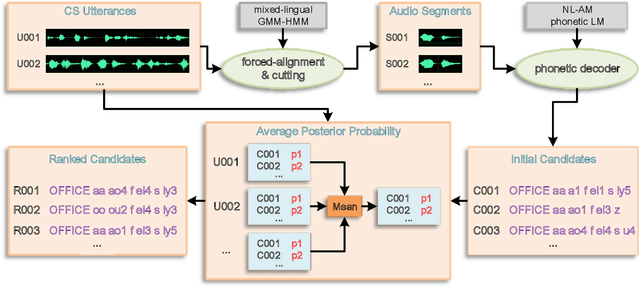

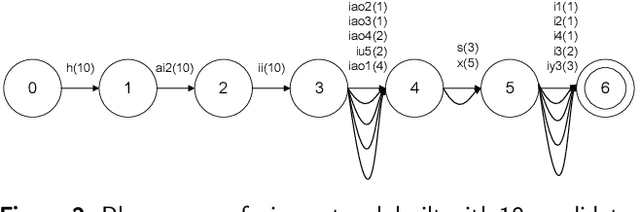

Code-Switching refers to the phenomenon of switching languages within a sentence or discourse. However, limited code-switching , different language phoneme-sets and high rebuilding costs throw a challenge to make the specialized acoustic model for code-switching speech recognition. In this paper, we make use of limited code-switching data as driving materials and explore a shortcut to quickly develop intra-sentential code-switching recognition skill on the commissioned native language acoustic model, where we propose a data-driven method to make the seed lexicon which is used to train grapheme-to-phoneme model to predict mapping pronunciations for foreign language word in code-switching sentences. The core work of the data-driven technology in this paper consists of a phonetic decoding method and different selection methods. And for imbalanced word-level driving materials problem, we have an internal assistance inspiration that learning the good pronunciation rules in the words that possess sufficient materials using the grapheme-to-phoneme model to help the scarce. Our experiments show that the Mixed Error Rate in intra-sentential Chinese-English code-switching recognition reduced from 29.15\%, acquired on the pure Chinese recognizer, to 12.13\% by adding foreign language words' pronunciation through our data-driven approach, and finally get the best result 11.14\% with the combination of different selection methods and internal assistance tactic.