 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentMiner: Intent Inversion Attack via Tool Call Analysis in the Model Context Protocol
Dec 16, 2025The rapid evolution of Large Language Models (LLMs) into autonomous agents has led to the adoption of the Model Context Protocol (MCP) as a standard for discovering and invoking external tools. While this architecture decouples the reasoning engine from tool execution to enhance scalability, it introduces a significant privacy surface: third-party MCP servers, acting as semi-honest intermediaries, can observe detailed tool interaction logs outside the user's trusted boundary. In this paper, we first identify and formalize a novel privacy threat termed Intent Inversion, where a semi-honest MCP server attempts to reconstruct the user's private underlying intent solely by analyzing legitimate tool calls. To systematically assess this vulnerability, we propose IntentMiner, a framework that leverages Hierarchical Information Isolation and Three-Dimensional Semantic Analysis, integrating tool purpose, call statements, and returned results, to accurately infer user intent at the step level. Extensive experiments demonstrate that IntentMiner achieves a high degree of semantic alignment (over 85%) with original user queries, significantly outperforming baseline approaches. These results highlight the inherent privacy risks in decoupled agent architectures, revealing that seemingly benign tool execution logs can serve as a potent vector for exposing user secrets.
SUDO: Enhancing Text-to-Image Diffusion Models with Self-Supervised Direct Preference Optimization
Apr 20, 2025



Previous text-to-image diffusion models typically employ supervised fine-tuning (SFT) to enhance pre-trained base models. However, this approach primarily minimizes the loss of mean squared error (MSE) at the pixel level, neglecting the need for global optimization at the image level, which is crucial for achieving high perceptual quality and structural coherence. In this paper, we introduce Self-sUpervised Direct preference Optimization (SUDO), a novel paradigm that optimizes both fine-grained details at the pixel level and global image quality. By integrating direct preference optimization into the model, SUDO generates preference image pairs in a self-supervised manner, enabling the model to prioritize global-level learning while complementing the pixel-level MSE loss. As an effective alternative to supervised fine-tuning, SUDO can be seamlessly applied to any text-to-image diffusion model. Importantly, it eliminates the need for costly data collection and annotation efforts typically associated with traditional direct preference optimization methods. Through extensive experiments on widely-used models, including Stable Diffusion 1.5 and XL, we demonstrate that SUDO significantly enhances both global and local image quality. The codes are provided at \href{https://github.com/SPengLiang/SUDO}{this link}.
Discriminator-Free Direct Preference Optimization for Video Diffusion
Apr 11, 2025Direct Preference Optimization (DPO), which aligns models with human preferences through win/lose data pairs, has achieved remarkable success in language and image generation. However, applying DPO to video diffusion models faces critical challenges: (1) Data inefficiency. Generating thousands of videos per DPO iteration incurs prohibitive costs; (2) Evaluation uncertainty. Human annotations suffer from subjective bias, and automated discriminators fail to detect subtle temporal artifacts like flickering or motion incoherence. To address these, we propose a discriminator-free video DPO framework that: (1) Uses original real videos as win cases and their edited versions (e.g., reversed, shuffled, or noise-corrupted clips) as lose cases; (2) Trains video diffusion models to distinguish and avoid artifacts introduced by editing. This approach eliminates the need for costly synthetic video comparisons, provides unambiguous quality signals, and enables unlimited training data expansion through simple editing operations. We theoretically prove the framework's effectiveness even when real videos and model-generated videos follow different distributions. Experiments on CogVideoX demonstrate the efficiency of the proposed method.
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
VP-MEL: Visual Prompts Guided Multimodal Entity Linking
Dec 10, 2024



Multimodal Entity Linking (MEL) is extensively utilized in the domains of information retrieval. However, existing MEL methods typically utilize mention words as mentions for retrieval. This results in a significant dependence of MEL on mention words, thereby constraining its capacity to effectively leverage information from both images and text. In situations where mention words are absent, MEL methods struggle to leverage image-text pairs for entity linking. To solve these issues, we introduce a Visual Prompts guided Multimodal Entity Linking (VP-MEL) task. VP-MEL directly marks specific regions within the image. These markers are referred to as visual prompts in VP-MEL. Without mention words, VP-MEL aims to utilize marked image-text pairs to align visual prompts with specific entities in the knowledge bases. A new dataset for the VP-MEL task, VPWiki, is proposed in this paper. Moreover, we propose a framework named FBMEL, which enhances the significance of visual prompts and fully leverages the information in image-text pairs. Experimental results on the VPWiki dataset demonstrate that FBMEL outperforms baseline methods across multiple benchmarks for the VP-MEL task.
Searching Priors Makes Text-to-Video Synthesis Better
Jun 05, 2024
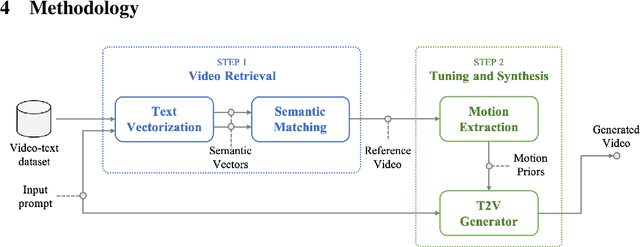


Significant advancements in video diffusion models have brought substantial progress to the field of text-to-video (T2V) synthesis. However, existing T2V synthesis model struggle to accurately generate complex motion dynamics, leading to a reduction in video realism. One possible solution is to collect massive data and train the model on it, but this would be extremely expensive. To alleviate this problem, in this paper, we reformulate the typical T2V generation process as a search-based generation pipeline. Instead of scaling up the model training, we employ existing videos as the motion prior database. Specifically, we divide T2V generation process into two steps: (i) For a given prompt input, we search existing text-video datasets to find videos with text labels that closely match the prompt motions. We propose a tailored search algorithm that emphasizes object motion features. (ii) Retrieved videos are processed and distilled into motion priors to fine-tune a pre-trained base T2V model, followed by generating desired videos using input prompt. By utilizing the priors gleaned from the searched videos, we enhance the realism of the generated videos' motion. All operations can be finished on a single NVIDIA RTX 4090 GPU. We validate our method against state-of-the-art T2V models across diverse prompt inputs. The code will be public.
EmoSpeaker: One-shot Fine-grained Emotion-Controlled Talking Face Generation
Feb 02, 2024



Implementing fine-grained emotion control is crucial for emotion generation tasks because it enhances the expressive capability of the generative model, allowing it to accurately and comprehensively capture and express various nuanced emotional states, thereby improving the emotional quality and personalization of generated content. Generating fine-grained facial animations that accurately portray emotional expressions using only a portrait and an audio recording presents a challenge. In order to address this challenge, we propose a visual attribute-guided audio decoupler. This enables the obtention of content vectors solely related to the audio content, enhancing the stability of subsequent lip movement coefficient predictions. To achieve more precise emotional expression, we introduce a fine-grained emotion coefficient prediction module. Additionally, we propose an emotion intensity control method using a fine-grained emotion matrix. Through these, effective control over emotional expression in the generated videos and finer classification of emotion intensity are accomplished. Subsequently, a series of 3DMM coefficient generation networks are designed to predict 3D coefficients, followed by the utilization of a rendering network to generate the final video. Our experimental results demonstrate that our proposed method, EmoSpeaker, outperforms existing emotional talking face generation methods in terms of expression variation and lip synchronization. Project page: https://peterfanfan.github.io/EmoSpeaker/
Regulating Intermediate 3D Features for Vision-Centric Autonomous Driving
Dec 19, 2023



Multi-camera perception tasks have gained significant attention in the field of autonomous driving. However, existing frameworks based on Lift-Splat-Shoot (LSS) in the multi-camera setting cannot produce suitable dense 3D features due to the projection nature and uncontrollable densification process. To resolve this problem, we propose to regulate intermediate dense 3D features with the help of volume rendering. Specifically, we employ volume rendering to process the dense 3D features to obtain corresponding 2D features (e.g., depth maps, semantic maps), which are supervised by associated labels in the training. This manner regulates the generation of dense 3D features on the feature level, providing appropriate dense and unified features for multiple perception tasks. Therefore, our approach is termed Vampire, stands for "Volume rendering As Multi-camera Perception Intermediate feature REgulator". Experimental results on the Occ3D and nuScenes datasets demonstrate that Vampire facilitates fine-grained and appropriate extraction of dense 3D features, and is competitive with existing SOTA methods across diverse downstream perception tasks like 3D occupancy prediction, LiDAR segmentation and 3D objection detection, while utilizing moderate GPU resources. We provide a video demonstration in the supplementary materials and Codes are available at github.com/cskkxjk/Vampire.
Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning
Nov 29, 2023



Recent one-shot video tuning methods, which fine-tune the network on a specific video based on pre-trained text-to-image models (e.g., Stable Diffusion), are popular in the community because of the flexibility. However, these methods often produce videos marred by incoherence and inconsistency. To address these limitations, this paper introduces a simple yet effective noise constraint across video frames. This constraint aims to regulate noise predictions across their temporal neighbors, resulting in smooth latents. It can be simply included as a loss term during the training phase. By applying the loss to existing one-shot video tuning methods, we significantly improve the overall consistency and smoothness of the generated videos. Furthermore, we argue that current video evaluation metrics inadequately capture smoothness. To address this, we introduce a novel metric that considers detailed features and their temporal dynamics. Experimental results validate the effectiveness of our approach in producing smoother videos on various one-shot video tuning baselines. The source codes and video demos are available at \href{https://github.com/SPengLiang/SmoothVideo}{https://github.com/SPengLiang/SmoothVideo}.
DHOT-GM: Robust Graph Matching Using A Differentiable Hierarchical Optimal Transport Framework
Oct 18, 2023



Graph matching is one of the most significant graph analytic tasks in practice, which aims to find the node correspondence across different graphs. Most existing approaches rely on adjacency matrices or node embeddings when matching graphs, whose performances are often sub-optimal because of not fully leveraging the multi-modal information hidden in graphs, such as node attributes, subgraph structures, etc. In this study, we propose a novel and effective graph matching method based on a differentiable hierarchical optimal transport (HOT) framework, called DHOT-GM. Essentially, our method represents each graph as a set of relational matrices corresponding to the information of different modalities. Given two graphs, we enumerate all relational matrix pairs and obtain their matching results, and accordingly, infer the node correspondence by the weighted averaging of the matching results. This method can be implemented as computing the HOT distance between the two graphs -- each matching result is an optimal transport plan associated with the Gromov-Wasserstein (GW) distance between two relational matrices, and the weights of all matching results are the elements of an upper-level optimal transport plan defined on the matrix sets. We propose a bi-level optimization algorithm to compute the HOT distance in a differentiable way, making the significance of the relational matrices adjustable. Experiments on various graph matching tasks demonstrate the superiority and robustness of our method compared to state-of-the-art approaches.