 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
UniHDA: Towards Universal Hybrid Domain Adaptation of Image Generators
Jan 23, 2024

Generative domain adaptation has achieved remarkable progress, enabling us to adapt a pre-trained generator to a new target domain. However, existing methods simply adapt the generator to a single target domain and are limited to a single modality, either text-driven or image-driven. Moreover, they are prone to overfitting domain-specific attributes, which inevitably compromises cross-domain consistency. In this paper, we propose UniHDA, a unified and versatile framework for generative hybrid domain adaptation with multi-modal references from multiple domains. We use CLIP encoder to project multi-modal references into a unified embedding space and then linear interpolate the direction vectors from multiple target domains to achieve hybrid domain adaptation. To ensure the cross-domain consistency, we propose a novel cross-domain spatial structure (CSS) loss that maintains detailed spatial structure information between source and target generator. Experiments show that the adapted generator can synthesise realistic images with various attribute compositions. Additionally, our framework is versatile to multiple generators, \eg, StyleGAN2 and Diffusion Models.
Few-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023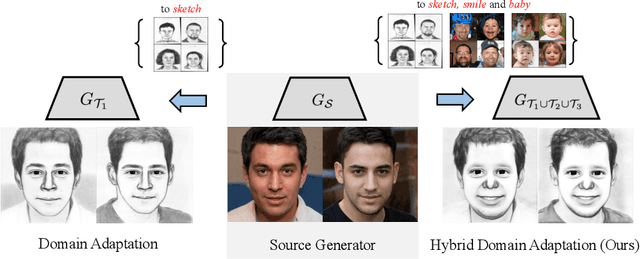
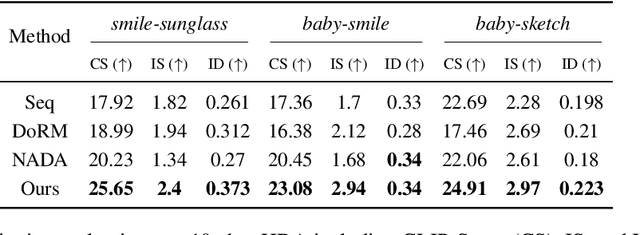
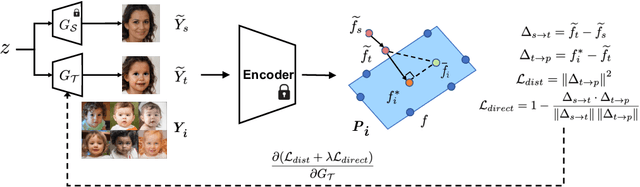
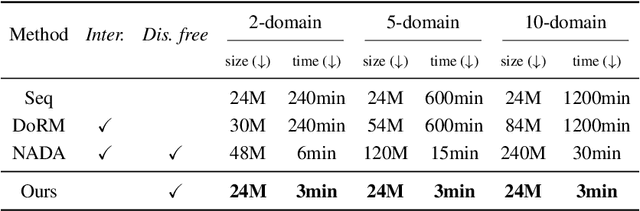
Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.
NormKD: Normalized Logits for Knowledge Distillation
Aug 01, 2023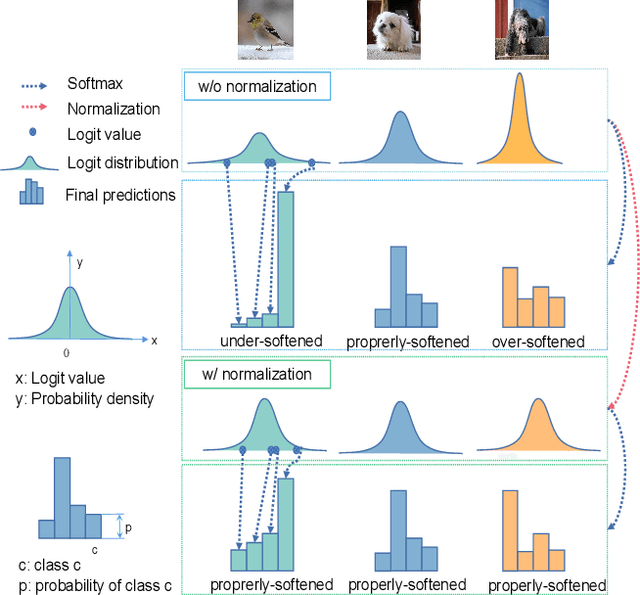
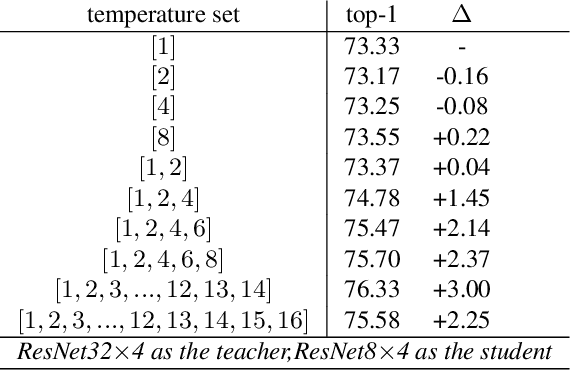
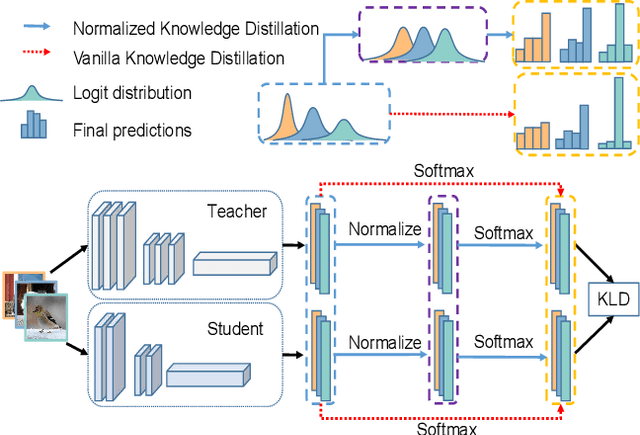
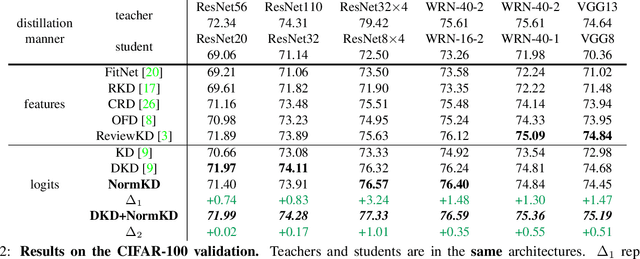
Logit based knowledge distillation gets less attention in recent years since feature based methods perform better in most cases. Nevertheless, we find it still has untapped potential when we re-investigate the temperature, which is a crucial hyper-parameter to soften the logit outputs. For most of the previous works, it was set as a fixed value for the entire distillation procedure. However, as the logits from different samples are distributed quite variously, it is not feasible to soften all of them to an equal degree by just a single temperature, which may make the previous work transfer the knowledge of each sample inadequately. In this paper, we restudy the hyper-parameter temperature and figure out its incapability to distill the knowledge from each sample sufficiently when it is a single value. To address this issue, we propose Normalized Knowledge Distillation (NormKD), with the purpose of customizing the temperature for each sample according to the characteristic of the sample's logit distribution. Compared to the vanilla KD, NormKD barely has extra computation or storage cost but performs significantly better on CIRAR-100 and ImageNet for image classification. Furthermore, NormKD can be easily applied to the other logit based methods and achieve better performance which can be closer to or even better than the feature based method.
APPT : Asymmetric Parallel Point Transformer for 3D Point Cloud Understanding
Mar 31, 2023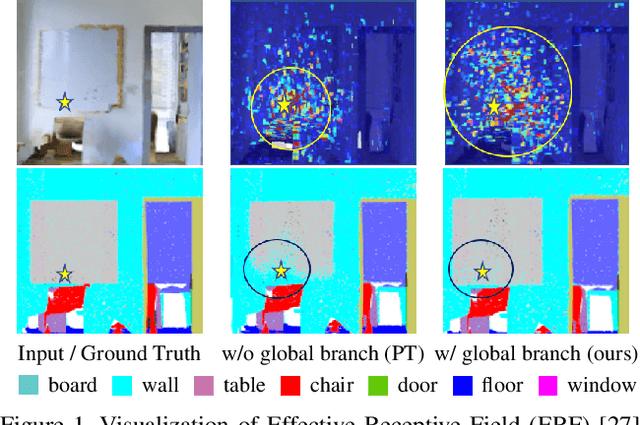
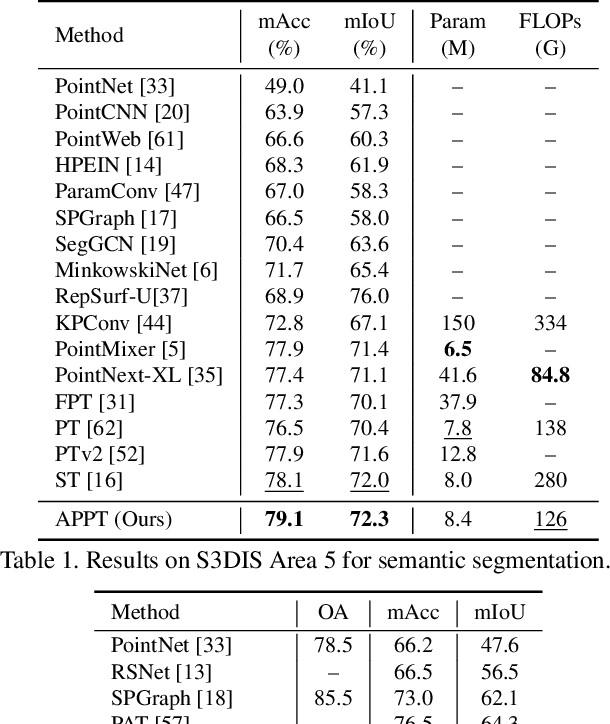
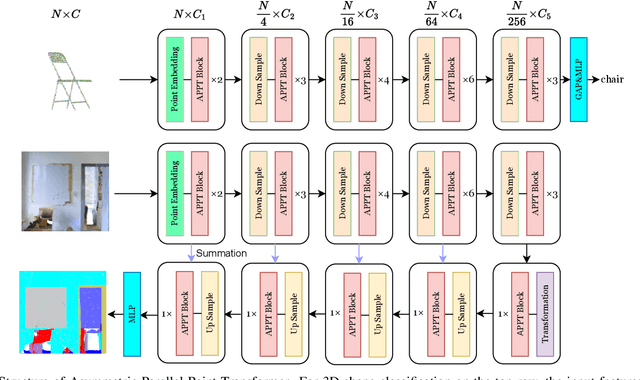
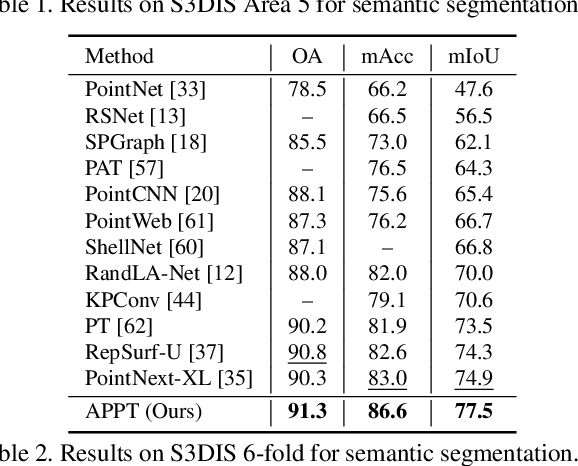
Transformer-based networks have achieved impressive performance in 3D point cloud understanding. However, most of them concentrate on aggregating local features, but neglect to directly model global dependencies, which results in a limited effective receptive field. Besides, how to effectively incorporate local and global components also remains challenging. To tackle these problems, we propose Asymmetric Parallel Point Transformer (APPT). Specifically, we introduce Global Pivot Attention to extract global features and enlarge the effective receptive field. Moreover, we design the Asymmetric Parallel structure to effectively integrate local and global information. Combined with these designs, APPT is able to capture features globally throughout the entire network while focusing on local-detailed features. Extensive experiments show that our method outperforms the priors and achieves state-of-the-art on several benchmarks for 3D point cloud understanding, such as 3D semantic segmentation on S3DIS, 3D shape classification on ModelNet40, and 3D part segmentation on ShapeNet.
CLRNet: Cross Layer Refinement Network for Lane Detection
Mar 19, 2022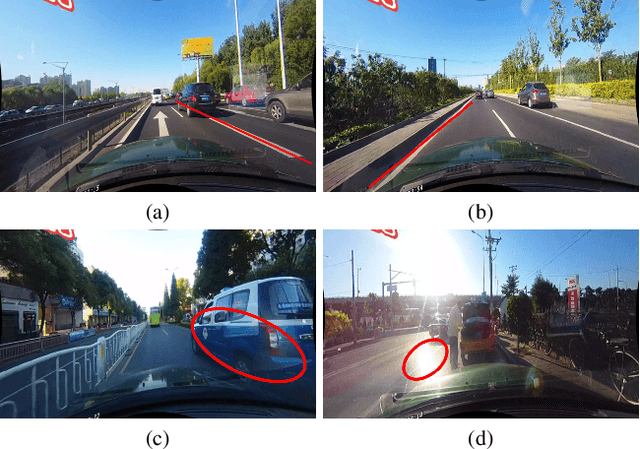
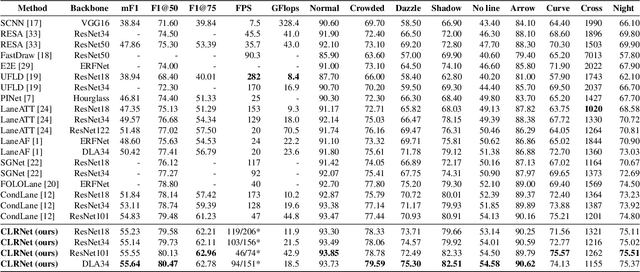
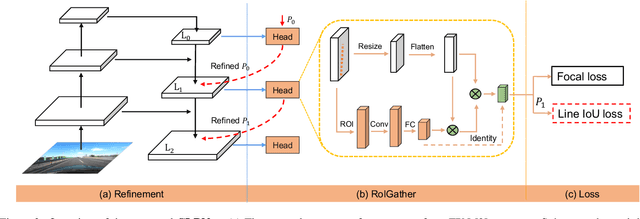
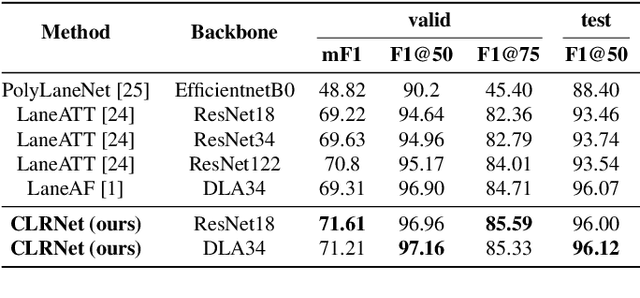
Lane is critical in the vision navigation system of the intelligent vehicle. Naturally, lane is a traffic sign with high-level semantics, whereas it owns the specific local pattern which needs detailed low-level features to localize accurately. Using different feature levels is of great importance for accurate lane detection, but it is still under-explored. In this work, we present Cross Layer Refinement Network (CLRNet) aiming at fully utilizing both high-level and low-level features in lane detection. In particular, it first detects lanes with high-level semantic features then performs refinement based on low-level features. In this way, we can exploit more contextual information to detect lanes while leveraging local detailed lane features to improve localization accuracy. We present ROIGather to gather global context, which further enhances the feature representation of lanes. In addition to our novel network design, we introduce Line IoU loss which regresses the lane line as a whole unit to improve the localization accuracy. Experiments demonstrate that the proposed method greatly outperforms the state-of-the-art lane detection approaches.
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
Jun 10, 2021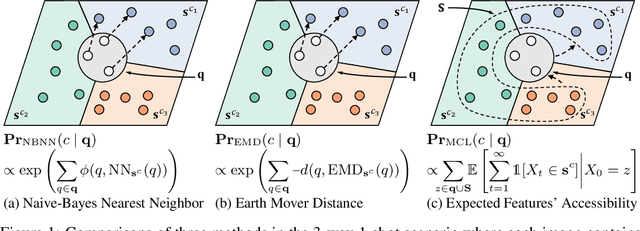
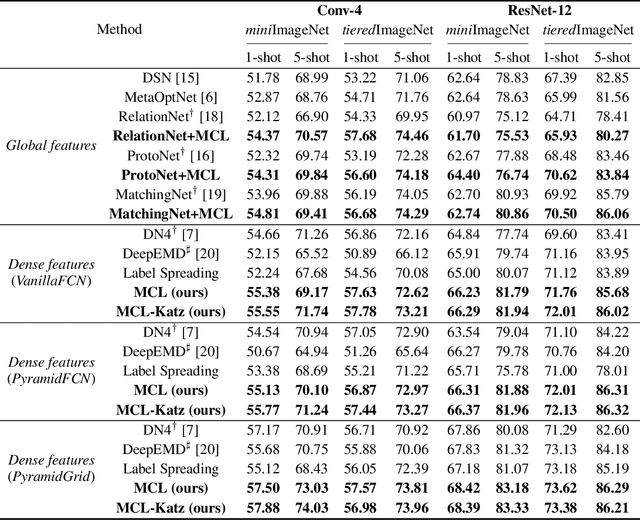
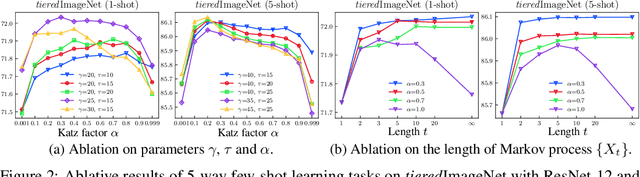
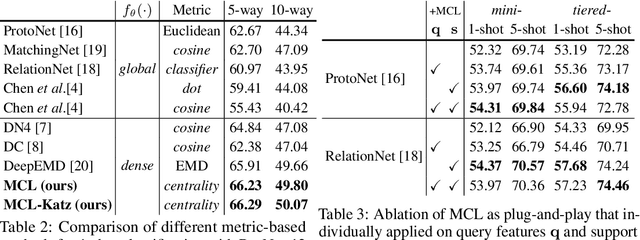
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to accommodate new tasks not seen during training, given only a few examples. To handle the limited-data problem in few-shot regimes, recent methods tend to collectively use a set of local features to densely represent an image instead of using a mixed global feature. They generally explore a unidirectional query-to-support paradigm in FSL, e.g., find the nearest/optimal support feature for each query feature and aggregate these local matches for a joint classification. In this paper, we propose a new method Mutual Centralized Learning (MCL) to fully affiliate the two disjoint sets of dense features in a bidirectional paradigm. We associate each local feature with a particle that can bidirectionally random walk in a discrete feature space by the affiliations. To estimate the class probability, we propose the features' accessibility that measures the expected number of visits to the support features of that class in a Markov process. We relate our method to learning a centrality on an affiliation network and demonstrate its capability to be plugged in existing methods by highlighting centralized local features. Experiments show that our method achieves the state-of-the-art on both miniImageNet and tieredImageNet.
SCALoss: Side and Corner Aligned Loss for Bounding Box Regression
Apr 01, 2021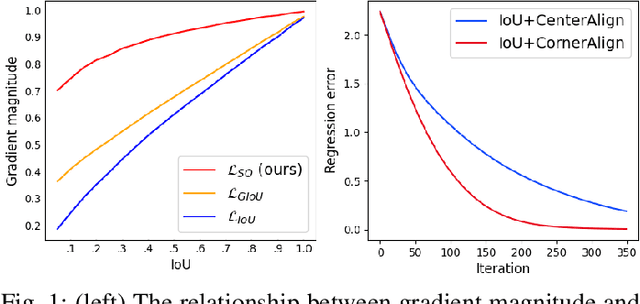
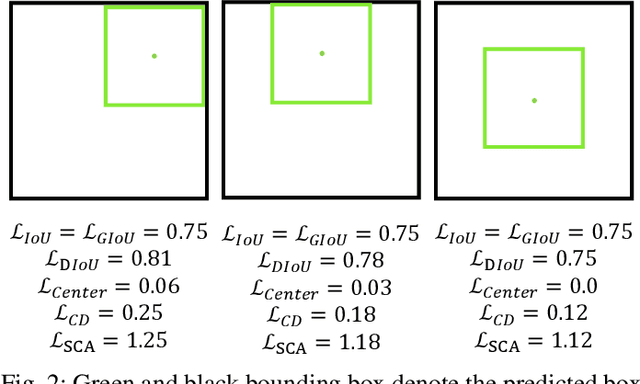
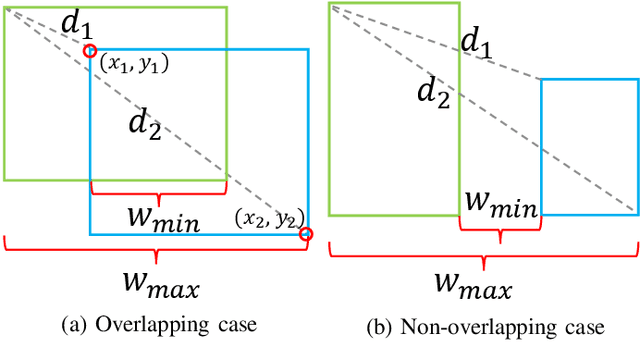
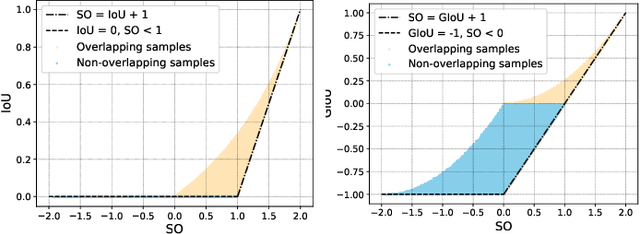
Bounding box regression is an important component in object detection. Recent work has shown the promising performance by optimizing the Intersection over Union (IoU) as loss. However, IoU-based loss has the gradient vanish problem in the case of low overlapping bounding boxes, and the model could easily ignore these simple cases. In this paper, we propose Side Overlap (SO) loss by maximizing the side overlap of two bounding boxes, which puts more penalty for low overlapping bounding box cases. Besides, to speed up the convergence, the Corner Distance (CD) is added into the objective function. Combining the Side Overlap and Corner Distance, we get a new regression objective function, Side and Corner Align Loss (SCALoss). The SCALoss is well-correlated with IoU loss, which also benefits the evaluation metric but produces more penalty for low-overlapping cases. It can serve as a comprehensive similarity measure, leading the better localization performance and faster convergence speed. Experiments on COCO and PASCAL VOC benchmarks show that SCALoss can bring consistent improvement and outperform $\ell_n$ loss and IoU based loss with popular object detectors such as YOLOV3, SSD, Reppoints, Faster-RCNN.
DMN4: Few-shot Learning via Discriminative Mutual Nearest Neighbor Neural Network
Mar 15, 2021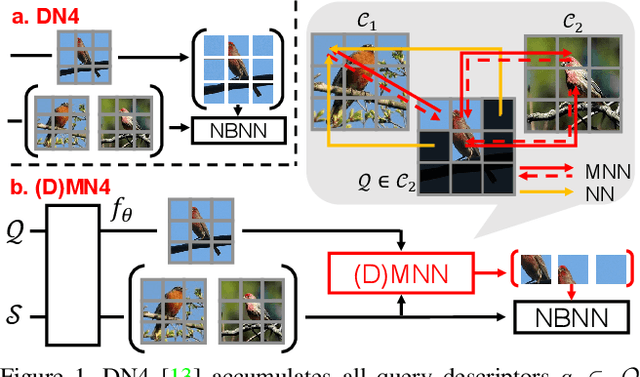
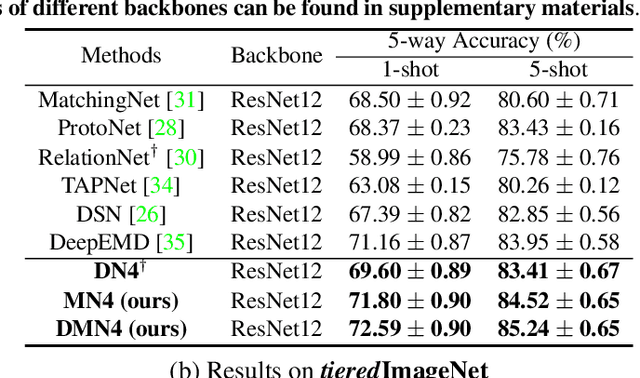

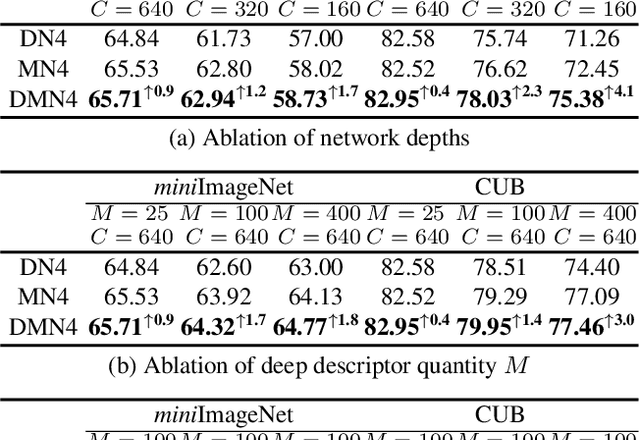
Few-shot learning (FSL) aims to classify images under low-data regimes, where the conventional pooled global representation is likely to lose useful local characteristics. Recent work has achieved promising performances by using deep descriptors. They generally take all deep descriptors from neural networks into consideration while ignoring that some of them are useless in classification due to their limited receptive field, e.g., task-irrelevant descriptors could be misleading and multiple aggregative descriptors from background clutter could even overwhelm the object's presence. In this paper, we argue that a Mutual Nearest Neighbor (MNN) relation should be established to explicitly select the query descriptors that are most relevant to each task and discard less relevant ones from aggregative clutters in FSL. Specifically, we propose Discriminative Mutual Nearest Neighbor Neural Network (DMN4) for FSL. Extensive experiments demonstrate that our method not only qualitatively selects task-relevant descriptors but also quantitatively outperforms the existing state-of-the-arts by a large margin of 1.8~4.9% on fine-grained CUB, a considerable margin of 1.4~2.2% on both supervised and semi-supervised miniImagenet, and ~1.4% on challenging tieredimagenet.
RESA: Recurrent Feature-Shift Aggregator for Lane Detection
Aug 31, 2020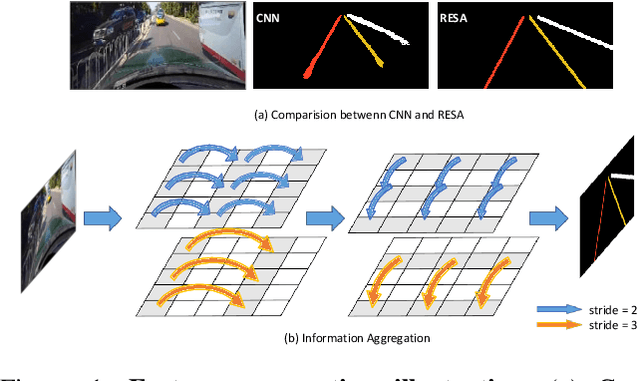

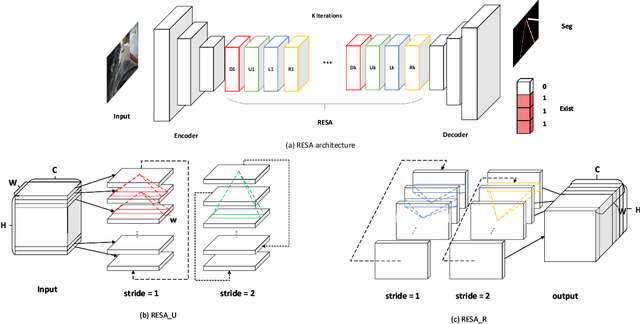
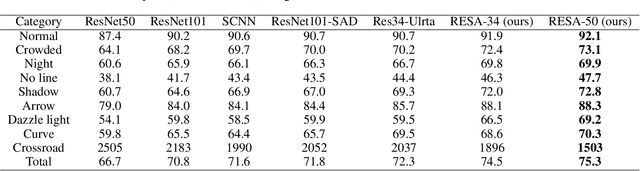
Lane detection is one of the most important tasks in self-driving. Due to various complex scenarios (e.g., severe occlusion, ambiguous lanes, and etc.) and the sparse supervisory signals inherent in lane annotations, lane detection task is still challenging. Thus, it is difficult for ordinary convolutional neural network (CNN) trained in general scenes to catch subtle lane feature from raw image. In this paper, we present a novel module named REcurrent Feature-Shift Aggregator (RESA) to enrich lane feature after preliminary feature extraction with an ordinary CNN. RESA takes advantage of strong shape priors of lanes and captures spatial relationships of pixels across rows and columns. It shifts sliced feature map recurrently in vertical and horizontal directions and enables each pixel to gather global information. With the help of slice-by-slice information propagation, RESA can conjecture lanes accurately in challenging scenarios with weak appearance clues. Moreover, we also propose a Bilateral Up-Sampling Decoder which combines coarse grained feature and fine detailed feature in up-sampling stage, and it can recover low-resolution feature map into pixel-wise prediction meticulously. Our method achieves state-of-the-art results on two popular lane detection benchmarks (CULane and Tusimple). The code will be released publicly available.