 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormKD: Normalized Logits for Knowledge Distillation
Paper and Code
Aug 01, 2023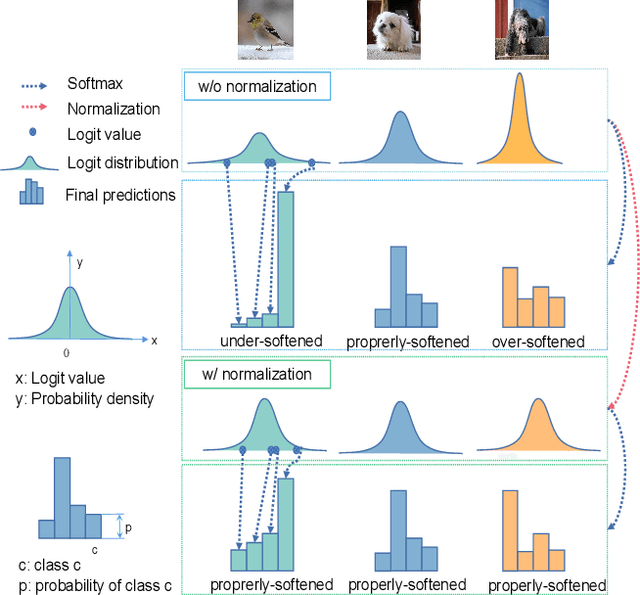
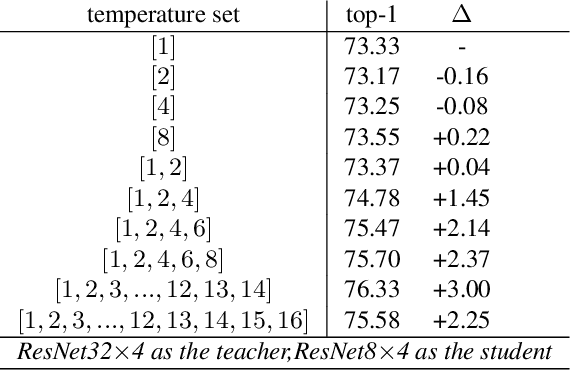
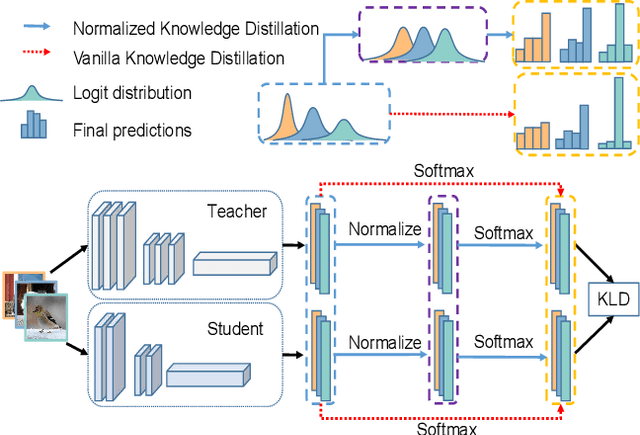
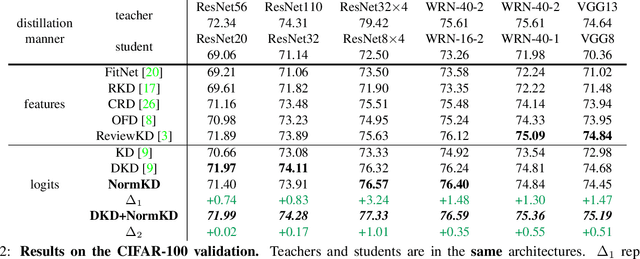
Logit based knowledge distillation gets less attention in recent years since feature based methods perform better in most cases. Nevertheless, we find it still has untapped potential when we re-investigate the temperature, which is a crucial hyper-parameter to soften the logit outputs. For most of the previous works, it was set as a fixed value for the entire distillation procedure. However, as the logits from different samples are distributed quite variously, it is not feasible to soften all of them to an equal degree by just a single temperature, which may make the previous work transfer the knowledge of each sample inadequately. In this paper, we restudy the hyper-parameter temperature and figure out its incapability to distill the knowledge from each sample sufficiently when it is a single value. To address this issue, we propose Normalized Knowledge Distillation (NormKD), with the purpose of customizing the temperature for each sample according to the characteristic of the sample's logit distribution. Compared to the vanilla KD, NormKD barely has extra computation or storage cost but performs significantly better on CIRAR-100 and ImageNet for image classification. Furthermore, NormKD can be easily applied to the other logit based methods and achieve better performance which can be closer to or even better than the feature based method.