 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023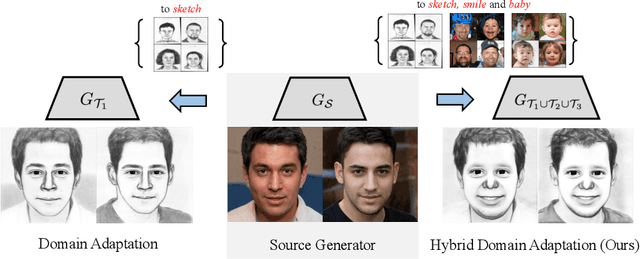
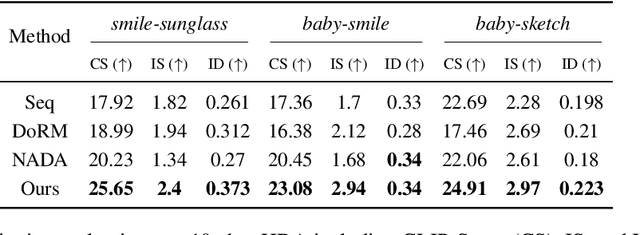
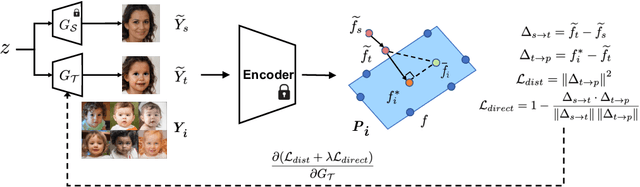
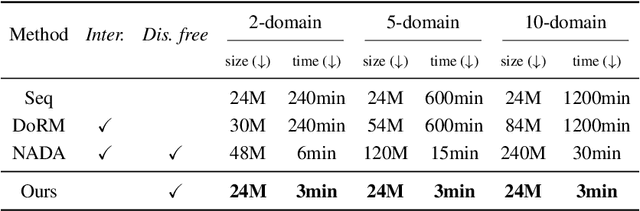
Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Jul 19, 2016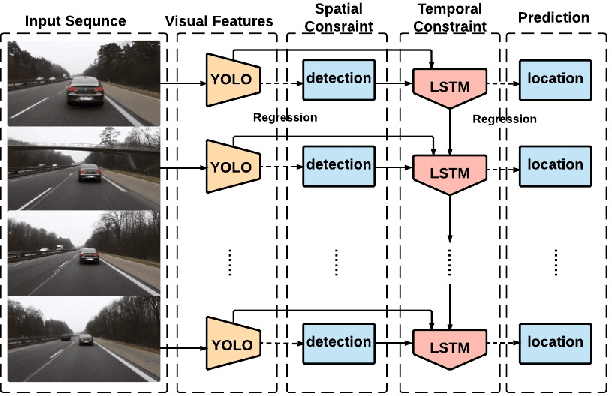



In this paper, we develop a new approach of spatially supervised recurrent convolutional neural networks for visual object tracking. Our recurrent convolutional network exploits the history of locations as well as the distinctive visual features learned by the deep neural networks. Inspired by recent bounding box regression methods for object detection, we study the regression capability of Long Short-Term Memory (LSTM) in the temporal domain, and propose to concatenate high-level visual features produced by convolutional networks with region information. In contrast to existing deep learning based trackers that use binary classification for region candidates, we use regression for direct prediction of the tracking locations both at the convolutional layer and at the recurrent unit. Our extensive experimental results and performance comparison with state-of-the-art tracking methods on challenging benchmark video tracking datasets shows that our tracker is more accurate and robust while maintaining low computational cost. For most test video sequences, our method achieves the best tracking performance, often outperforms the second best by a large margin.