 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling
Oct 10, 2023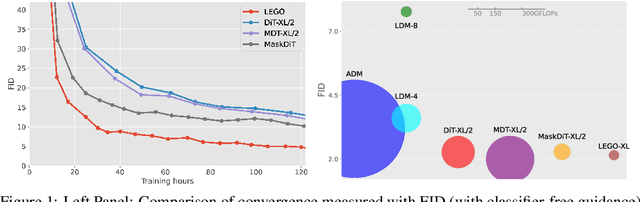


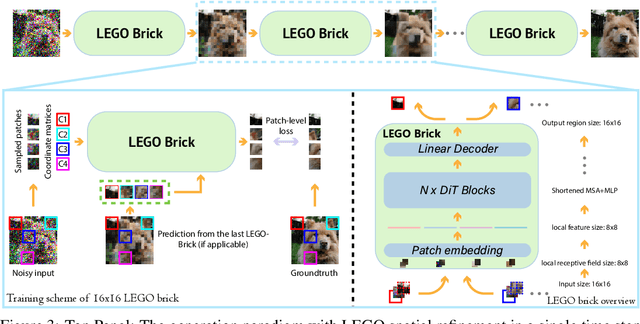
Diffusion models excel at generating photo-realistic images but come with significant computational costs in both training and sampling. While various techniques address these computational challenges, a less-explored issue is designing an efficient and adaptable network backbone for iterative refinement. Current options like U-Net and Vision Transformer often rely on resource-intensive deep networks and lack the flexibility needed for generating images at variable resolutions or with a smaller network than used in training. This study introduces LEGO bricks, which seamlessly integrate Local-feature Enrichment and Global-content Orchestration. These bricks can be stacked to create a test-time reconfigurable diffusion backbone, allowing selective skipping of bricks to reduce sampling costs and generate higher-resolution images than the training data. LEGO bricks enrich local regions with an MLP and transform them using a Transformer block while maintaining a consistent full-resolution image across all bricks. Experimental results demonstrate that LEGO bricks enhance training efficiency, expedite convergence, and facilitate variable-resolution image generation while maintaining strong generative performance. Moreover, LEGO significantly reduces sampling time compared to other methods, establishing it as a valuable enhancement for diffusion models.
Data Augmentation for Object Detection via Differentiable Neural Rendering
Apr 05, 2021



It is challenging to train a robust object detector under the supervised learning setting when the annotated data are scarce. Thus, previous approaches tackling this problem are in two categories: semi-supervised learning models that interpolate labeled data from unlabeled data, and self-supervised learning approaches that exploit signals within unlabeled data via pretext tasks. To seamlessly integrate and enhance existing supervised object detection methods, in this work, we focus on addressing the data scarcity problem from a fundamental viewpoint without changing the supervised learning paradigm. We propose a new offline data augmentation method for object detection, which semantically interpolates the training data with novel views. Specifically, our new system generates controllable views of training images based on differentiable neural rendering, together with corresponding bounding box annotations which involve no human intervention. Firstly, we extract and project pixel-aligned image features into point clouds while estimating depth maps. We then re-project them with a target camera pose and render a novel-view 2d image. Objects in the form of keypoints are marked in point clouds to recover annotations in new views. Our new method is fully compatible with online data augmentation methods, such as affine transform, image mixup, etc. Extensive experiments show that our method, as a cost-free tool to enrich images and labels, can significantly boost the performance of object detection systems with scarce training data. Code is available at \url{https://github.com/Guanghan/DANR}.
LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking
May 07, 2019


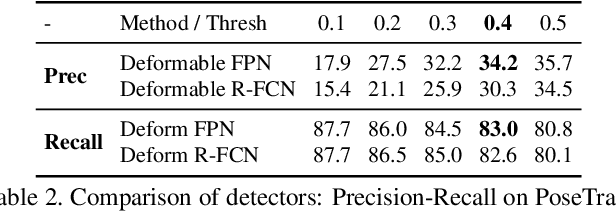
In this paper, we propose a novel effective light-weight framework, called LightTrack, for online human pose tracking. The proposed framework is designed to be generic for top-down pose tracking and is faster than existing online and offline methods. Single-person Pose Tracking (SPT) and Visual Object Tracking (VOT) are incorporated into one unified functioning entity, easily implemented by a replaceable single-person pose estimation module. Our framework unifies single-person pose tracking with multi-person identity association and sheds first light upon bridging keypoint tracking with object tracking. We also propose a Siamese Graph Convolution Network (SGCN) for human pose matching as a Re-ID module in our pose tracking system. In contrary to other Re-ID modules, we use a graphical representation of human joints for matching. The skeleton-based representation effectively captures human pose similarity and is computationally inexpensive. It is robust to sudden camera shift that introduces human drifting. To the best of our knowledge, this is the first paper to propose an online human pose tracking framework in a top-down fashion. The proposed framework is general enough to fit other pose estimators and candidate matching mechanisms. Our method outperforms other online methods while maintaining a much higher frame rate, and is very competitive with our offline state-of-the-art. We make the code publicly available at: https://github.com/Guanghan/lighttrack.
A Top-down Approach to Articulated Human Pose Estimation and Tracking
Jan 23, 2019

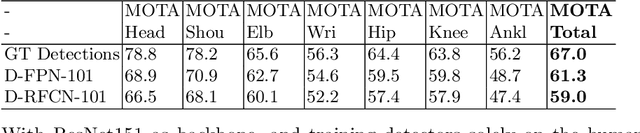
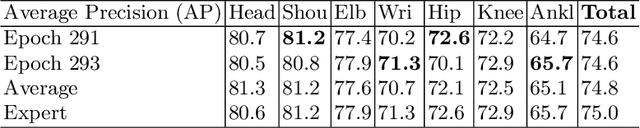
Both the tasks of multi-person human pose estimation and pose tracking in videos are quite challenging. Existing methods can be categorized into two groups: top-down and bottom-up approaches. In this paper, following the top-down approach, we aim to build a strong baseline system with three modules: human candidate detector, single-person pose estimator and human pose tracker. Firstly, we choose a generic object detector among state-of-the-art methods to detect human candidates. Then, the cascaded pyramid network is used to estimate the corresponding human pose. Finally, we use a flow-based pose tracker to render keypoint-association across frames, i.e., assigning each human candidate a unique and temporally-consistent id, for the multi-target pose tracking purpose. We conduct extensive ablative experiments to validate various choices of models and configurations. We take part in two ECCV 18 PoseTrack challenges: pose estimation and pose tracking.
Progressive Neural Networks for Image Classification
Apr 25, 2018


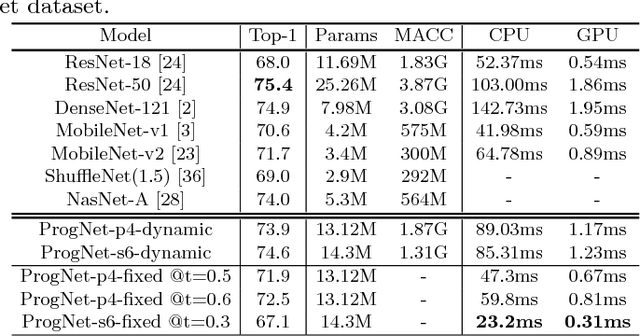
The inference structures and computational complexity of existing deep neural networks, once trained, are fixed and remain the same for all test images. However, in practice, it is highly desirable to establish a progressive structure for deep neural networks which is able to adapt its inference process and complexity for images with different visual recognition complexity. In this work, we develop a multi-stage progressive structure with integrated confidence analysis and decision policy learning for deep neural networks. This new framework consists of a set of network units to be activated in a sequential manner with progressively increased complexity and visual recognition power. Our extensive experimental results on the CIFAR-10 and ImageNet datasets demonstrate that the proposed progressive deep neural network is able to obtain more than 10 fold complexity scalability while achieving the state-of-the-art performance using a single network model satisfying different complexity-accuracy requirements.
Dual Path Networks for Multi-Person Human Pose Estimation
Oct 27, 2017



The task of multi-person human pose estimation in natural scenes is quite challenging. Existing methods include both top-down and bottom-up approaches. The main advantage of bottom-up methods is its excellent tradeoff between estimation accuracy and computational cost. We follow this path and aim to design smaller, faster, and more accurate neural networks for the regression of keypoints and limb association vectors. These two regression tasks are naturally dependent on each other. In this work, we propose a dual-path network specially designed for multi-person human pose estimation, and compare our performance with the openpose network in aspects of model size, forward speed, and estimation accuracy.
Knowledge Projection for Deep Neural Networks
Oct 26, 2017
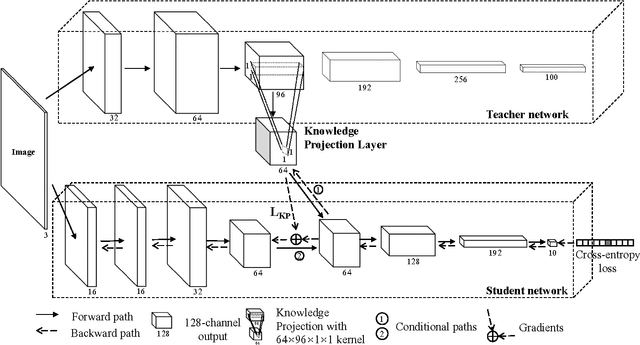


While deeper and wider neural networks are actively pushing the performance limits of various computer vision and machine learning tasks, they often require large sets of labeled data for effective training and suffer from extremely high computational complexity. In this paper, we will develop a new framework for training deep neural networks on datasets with limited labeled samples using cross-network knowledge projection which is able to improve the network performance while reducing the overall computational complexity significantly. Specifically, a large pre-trained teacher network is used to observe samples from the training data. A projection matrix is learned to project this teacher-level knowledge and its visual representations from an intermediate layer of the teacher network to an intermediate layer of a thinner and faster student network to guide and regulate its training process. Both the intermediate layers from the teacher network and the injection layers from the student network are adaptively selected during training by evaluating a joint loss function in an iterative manner. This knowledge projection framework allows us to use crucial knowledge learned by large networks to guide the training of thinner student networks, avoiding over-fitting, achieving better network performance, and significantly reducing the complexity. Extensive experimental results on benchmark datasets have demonstrated that our proposed knowledge projection approach outperforms existing methods, improving accuracy by up to 4% while reducing network complexity by 4 to 10 times, which is very attractive for practical applications of deep neural networks.
Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation
Aug 08, 2017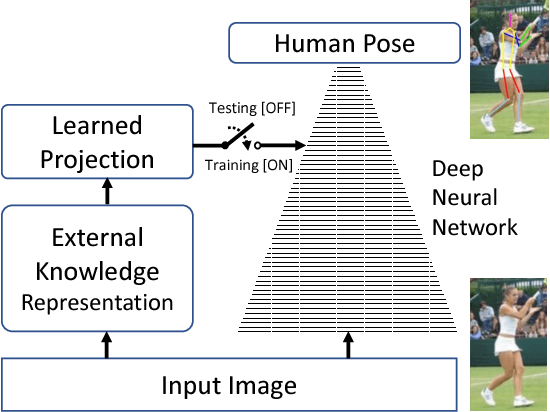



Human pose estimation using deep neural networks aims to map input images with large variations into multiple body keypoints which must satisfy a set of geometric constraints and inter-dependency imposed by the human body model. This is a very challenging nonlinear manifold learning process in a very high dimensional feature space. We believe that the deep neural network, which is inherently an algebraic computation system, is not the most effecient way to capture highly sophisticated human knowledge, for example those highly coupled geometric characteristics and interdependence between keypoints in human poses. In this work, we propose to explore how external knowledge can be effectively represented and injected into the deep neural networks to guide its training process using learned projections that impose proper prior. Specifically, we use the stacked hourglass design and inception-resnet module to construct a fractal network to regress human pose images into heatmaps with no explicit graphical modeling. We encode external knowledge with visual features which are able to characterize the constraints of human body models and evaluate the fitness of intermediate network output. We then inject these external features into the neural network using a projection matrix learned using an auxiliary cost function. The effectiveness of the proposed inception-resnet module and the benefit in guided learning with knowledge projection is evaluated on two widely used benchmarks. Our approach achieves state-of-the-art performance on both datasets.
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Jul 19, 2016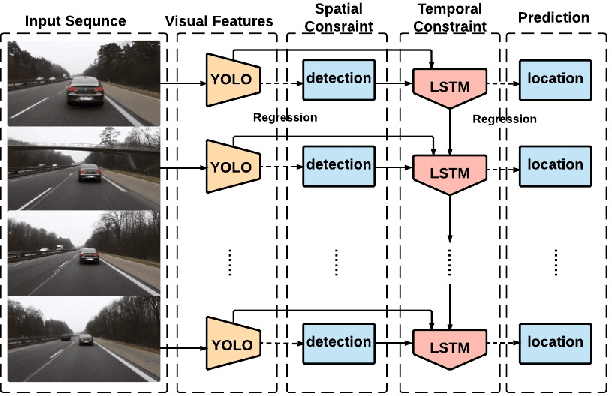



In this paper, we develop a new approach of spatially supervised recurrent convolutional neural networks for visual object tracking. Our recurrent convolutional network exploits the history of locations as well as the distinctive visual features learned by the deep neural networks. Inspired by recent bounding box regression methods for object detection, we study the regression capability of Long Short-Term Memory (LSTM) in the temporal domain, and propose to concatenate high-level visual features produced by convolutional networks with region information. In contrast to existing deep learning based trackers that use binary classification for region candidates, we use regression for direct prediction of the tracking locations both at the convolutional layer and at the recurrent unit. Our extensive experimental results and performance comparison with state-of-the-art tracking methods on challenging benchmark video tracking datasets shows that our tracker is more accurate and robust while maintaining low computational cost. For most test video sequences, our method achieves the best tracking performance, often outperforms the second best by a large margin.